






1. Torch 的两种并行化模型封装
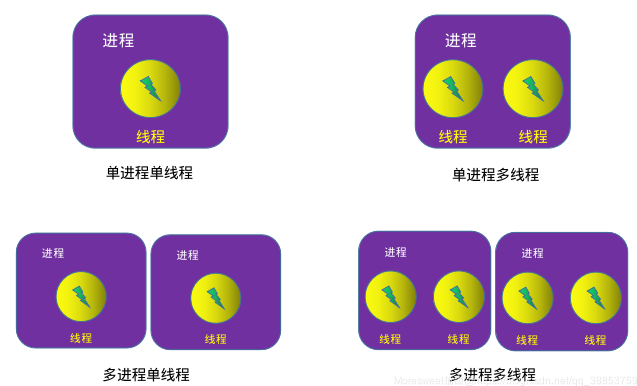
1.1 DataParallel
DataParallel 是 PyTorch 提供的一种数据并行方法,用于在单台机器上的多个 GPU 上进行模型训练。它通过将输入数据划分成多个子部分(mini-batches),并将这些子部分分配给不同的 GPU,以实现并行计算。
在前向传播过程中,输入数据会被划分成多个副本并发送到不同的设备(device)上进行计算。模型(module)会被复制到每个设备上,这意味着输入的批次(batch)会被平均分配到每个设备,但模型会在每个设备上有一个副本。每个模型副本只需要处理对应的子部分。需要注意的是,批次大小应大于GPU数量。在反向传播过程中,每个副本的梯度会被累加到原始模型中。总结来说,DataParallel会自动将数据切分并加载到相应的GPU上,将模型复制到每个GPU上,进行正向传播以计算梯度并汇总。
注意:DataParallel是单进程多线程的,仅仅能工作在单机中。
封装示例:
import torchimport torch.nn as nnimport torch.optim as optim# 定义模型class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc = nn.Linear(10, 1)def forward(self, x):return self.fc(x)# 初始化模型model = SimpleModel()# 使用 DataParallel 将模型分布到多个 GPU 上model = nn.DataParallel(model)
1.2 DistributedDataParallel
DistributedDataParallel (DDP) 是 PyTorch 提供的一个用于分布式数据并行训练的模块,适用于单机多卡和多机多卡的场景。相比于 DataParallel,DDP 更加高效和灵活,能够在多个 GPU 和多个节点上进行并行训练。
DistributedDataParallel是多进程的,可以工作在单机或多机器中。DataParallel通常会慢于DistributedDataParallel。所以目前主流的方法是DistributedDataParallel。
封装示例:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def main(rank, world_size):
# 初始化进程组
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# 创建模型并移动到GPU
model = SimpleModel().to(rank)
# 包装模型为DDP模型
ddp_model = DDP(model, device_ids=[rank])
if __name__ == "__main__":
import os
import torch.multiprocessing as mp
# 世界大小:总共的进程数
world_size = 4
# 使用mp.spawn启动多个进程
mp.spawn(main, args=(world_size,), nprocs=world_size, join=True)2. 多GPU训练的三种架构组织方式
由于上一节的讨论,本节所有源码均由DDP封装实现。
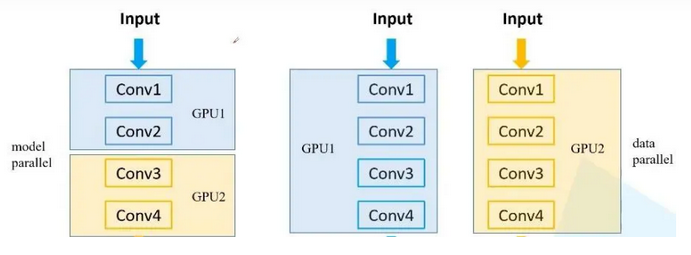
2.1 数据拆分,模型不拆分(Data Parallelism)
数据并行(Data Parallelism)将输入数据拆分成多个子部分(mini-batches),并分配给不同的 GPU 进行计算。每个 GPU 上都有一份完整的模型副本。这种方式适用于模型相对较小,但需要处理大量数据的场景。
由于下面的代码涉及了rank、world_size等概念,这里先做一下简要普及。
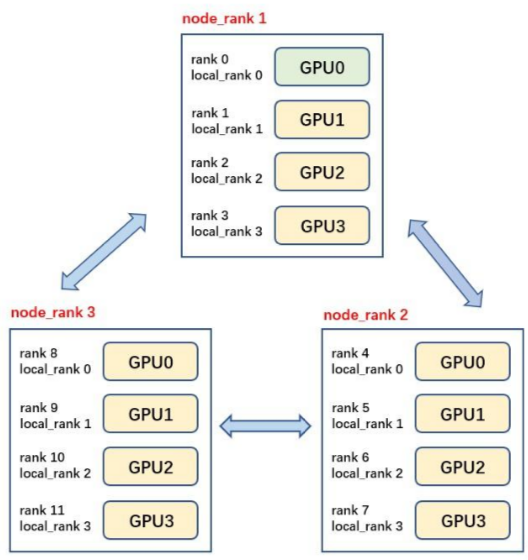
Rank
rank 是一个整数,用于标识当前进程在整个分布式训练中的身份。每个进程都有一个唯一的 rank。rank 的范围是 0 到 world_size - 1。
用于区分不同的进程。
可以根据 rank 来分配不同的数据和模型部分。
World Size
world_size 是一个整数,表示参与分布式训练的所有进程的总数。
确定分布式训练中所有进程的数量。
用于初始化通信组,确保所有进程能够正确地进行通信和同步。
Backend
backend 指定了用于进程间通信的后端库。常用的后端有 nccl(适用于 GPU)、gloo(适用于 CPU 和 GPU)和 mpi(适用于多种设备)。
决定了进程间通信的具体实现方式。
影响训练的效率和性能。
Init Method
init_method 指定了初始化分布式环境的方法。常用的初始化方法有 TCP、共享文件系统和环境变量。
用于设置进程间通信的初始化方式,确保所有进程能够正确加入到分布式训练中。
Local Rank
local_rank 是每个进程在其所在节点(机器)上的本地标识。不同节点上的进程可能会有相同的 local_rank。
用于将每个进程绑定到特定的 GPU 或 CPU。
import torchimport torch.nn as nnimport torch.optim as optimimport torch.distributed as distfrom torch.nn.parallel import DistributedDataParallel as DDPimport torch.multiprocessing as mpclass SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc = nn.Linear(10, 1)def forward(self, x):return self.fc(x)def train(rank, world_size):dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:29500', rank=rank, world_size=world_size)model = SimpleModel().to(rank)ddp_model = DDP(model, device_ids=[rank])criterion = nn.MSELoss().to(rank)optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)inputs = torch.randn(64, 10).to(rank)targets = torch.randn(64, 1).to(rank)outputs = ddp_model(inputs)loss = criterion(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()dist.destroy_process_group()if __name__ == "__main__":world_size = 4mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
2.2 数据不拆分,模型拆分(Model Parallelism)
模型并行(Model Parallelism)将模型拆分成多个部分,并分配给不同的 GPU。输入数据不拆分,但需要通过不同的 GPU 处理模型的不同部分。这种方式适用于模型非常大,单个 GPU 无法容纳完整模型的场景。
import torchimport torch.nn as nnimport torch.optim as optimimport torch.distributed as distfrom torch.nn.parallel import DistributedDataParallel as DDPimport torch.multiprocessing as mpclass ModelParallelModel(nn.Module):def __init__(self):super(ModelParallelModel, self).__init__()self.fc1 = nn.Linear(10, 10).to('cuda:0')self.fc2 = nn.Linear(10, 1).to('cuda:1')def forward(self, x):x = x.to('cuda:0')x = self.fc1(x)x = x.to('cuda:1')x = self.fc2(x)return xdef train(rank, world_size):dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:29500', rank=rank, world_size=world_size)model = ModelParallelModel()ddp_model = DDP(model, device_ids=[rank])criterion = nn.MSELoss().to('cuda:1')optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)inputs = torch.randn(64, 10).to('cuda:0')targets = torch.randn(64, 1).to('cuda:1')outputs = ddp_model(inputs)loss = criterion(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()dist.destroy_process_group()if __name__ == "__main__":world_size = 2mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
2.3 数据拆分,模型拆分(Pipeline Parallelism)
流水线并行(Pipeline Parallelism)结合了数据并行和模型并行。输入数据和模型都被拆分成多个部分,每个 GPU 处理部分数据和部分模型。这种方式适用于需要平衡计算和内存需求的大规模深度学习任务。
import torchimport torch.nn as nnimport torch.optim as optimimport torch.distributed as distfrom torch.nn.parallel import DistributedDataParallel as DDPimport torch.multiprocessing as mpclass PipelineParallelModel(nn.Module):def __init__(self):super(PipelineParallelModel, self).__init__()self.fc1 = nn.Linear(10, 10)self.fc2 = nn.Linear(10, 1)def forward(self, x):if self.fc1.weight.device != x.device:x = x.to(self.fc1.weight.device)x = self.fc1(x)if self.fc2.weight.device != x.device:x = x.to(self.fc2.weight.device)x = self.fc2(x)return xdef train(rank, world_size):dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:29500', rank=rank, world_size=world_size)model = PipelineParallelModel()model.fc1.to('cuda:0')model.fc2.to('cuda:1')ddp_model = DDP(model)criterion = nn.MSELoss().to('cuda:1')optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)inputs = torch.randn(64, 10).to('cuda:0')targets = torch.randn(64, 1).to('cuda:1')outputs = ddp_model(inputs)loss = criterion(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()dist.destroy_process_group()if __name__ == "__main__":world_size = 2mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
3. NCCL以及DistributedSampler
3.1 NCCL
NCCL是一个Nvidia专门为多GPU之间提供集合通讯的通讯库,或者说是一个多GPU卡通讯的框架 ,它具有一定程度拓扑感知的能力,提供了包括AllReduce、Broadcast、Reduce、AllGather、ReduceScatter等集合通讯API,也支持用户去使用ncclSend()、ncclRecv()来实现各种复杂的点对点通讯,如One-to-all、All-to-one、All-to-all等,在绝大多数情况下都可以通过服务器内的PCIe、NVLink、NVSwitch等和服务器间的RoCEv2、IB、TCP网络实现高带宽和低延迟。
它解决了前文提到的GPU间拓补识别、GPU间集合通信优化的问题。NCCL屏蔽了底层复杂的细节,向上提供API供训练框架调用,向下连接机内机间的GPU以完成模型参数的高效传输。
3.2 常见参数
修改环境变量或在nccl.conf中修改相关参数选项。可以改变通信特点,进而起到影响通行性能的作用。
NCCL_P2P_DISABLE 默认是开启P2P通信的,这样一般会更高效,用到点对点通信延迟会有所改善,带宽也是。
NCCL_P2P_LEVEL 开启P2P后可以设置P2P的级别,比如在那些特定条件下可以开启点对点通信,具体的可以参看文档(0-5)
NCCL_SOCKET_NTHREADS 增加它的数量可以提高socker传输的效率,但是会增加CPU的负担
NCCL_BUFFLE_SIZE 缓存数据量,缓存越大一次ring传输的数据就越大自然对带宽的压力最大,但是相应的总延迟次数会少。缺省值是4M(4194304),注意设置的时候使用bytes(字节大小)
NCCL_MAX/MIN_NCHANNELS 最小和最大的rings,rings越多对GPU的显存、带宽的压力都越大,也会影响计算性能
NCCL_CHECKS_DISABLE 在每次集合通信进行前对参数检验校对,这会增加延迟时间,在生产环境中可以设为1.缺省是0
NCCL_CHECK_POINTERS 在每次集合通信进行前对CUDA内存 指针进行校验,这会增加延迟时间,在生产环境中可以设为1.缺省是0
NCCL_NET_GDR_LEVEL GDR触发的条件,默认是当GPU和NIC挂载一个swith上面时使用GDR
NCCL_IGNORE_CPU_AFFINITY 忽略CPU与应用的亲和性使用GPU与nic的亲和性为主
NCCL_ALGO 通信使用的算法,ring Tree Collnet
NCCL_IB_HCA 代表IB使用的设备:Mellanox mlx5系列的HCA设备
A40(GPU3-A40:596:596 [2] NCCL INFO NET/IB : Using [0]mlx5_0:1/IB ; OOB ib0:66.66.66.211<0>),
V100(gpu196-v100:786:786 [5] NCCL INFO NET/IB : Using [0]mlx5_0:1/IB [1]mlx5_1:1/IB ; OOB ib0:66.66.66.110<0>),
A100(GPU6-A100:686:686 [1] NCCL INFO NET/IB : Using [0]mlx5_0:1/RoCE [1]mlx5_2:1/IB [2]mlx5_3:1/IB ; OOB ib0:66.66.66.128<0>),
NCCL_IB_HCA=mlx5 会默认轮询所有的设备。
NCCL_IB_HCA=mlx5_0:1 指定其中一台设备。
a100有两个口,如果都开的话,会出现训练的浮动;如果指定只使用一个口,训练速度会下降。
3.3 DistributedSampler
DistributedSampler原理如图所示:假设当前数据集有0~10共11个样本,使用2块GPU计算。首先打乱数据顺序,然后用 11/2 =6(向上取整),然后6乘以GPU个数2 = 12,因为只有11个数据,所以再把第一个数据(索引为6的数据)补到末尾,现在就有12个数据可以均匀分到每块GPU。然后分配数据:间隔将数据分配到不同的GPU中。
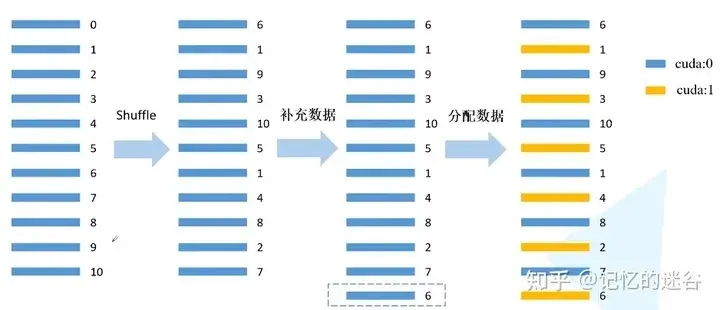
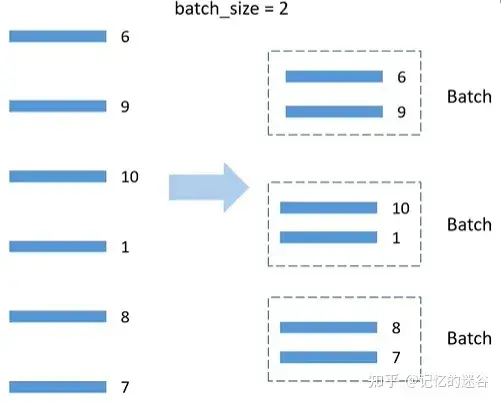
BatchSampler原理: DistributedSmpler将数据分配到两个GPU上,以第一个GPU为例,分到的数据是6,9,10,1,8,7,假设batch_size=2,就按顺序把数据两两一组,在训练时,每次获取一个batch的数据,就从组织好的一个个batch中取到。注意:只对训练集处理,验证集不使用BatchSampler。
train_dset = NBADataset(obs_len=self.cfg.past_frames,pred_len=self.cfg.future_frames,training=True)self.train_sampler = torch.utils.data.distributed.DistributedSampler(train_dset)self.train_loader = DataLoader(train_dset, batch_size=self.cfg.train_batch_size, sampler=self.train_sampler,num_workers=4, collate_fn=seq_collate)
4. 多进程启动综合测试
4.1 多卡训练多进程启动的两种方式
多卡训练启动有两种方式,其一是pytorch自带的torchrun,其二是自行设计多进程程序。

以下为torch,distributed.launch的简单demo:
运行方式为
# 直接运行torchrun --nproc_per_node=4 test.py# 等价方式python -m torch.distributed.launch --nproc_per_node=4 test.py
torchrun实际上运行的是/usr/local/mambaforge/envs/led/lib/python3.7/site-packages/torch/distributed/launch.py(根据读者的环境变化)
python -m torch.distributed.launch也会找到这个程序的python文件执行,这个命令会帮助设置一些环境变量启动backend,否则需要自行设置环境变量。
import torchimport torch.distributed as distimport torch.multiprocessing as mpimport torch.nn as nnimport torch.optim as optimfrom torch.nn.parallel import DistributedDataParallel as DDPimport osdef example(rank, world_size):# create default process groupdist.init_process_group("nccl", rank=rank, world_size=world_size)# create local modelmodel = nn.Linear(10, 10).to(rank)# construct DDP modelddp_model = DDP(model, device_ids=[rank])# define loss function and optimizerloss_fn = nn.MSELoss()optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)# forward passoutputs = ddp_model(torch.randn(20, 10).to(rank))labels = torch.randn(20, 10).to(rank)# backward passloss_fn(outputs, labels).backward()# update parametersoptimizer.step()def main():world_size = 2mp.spawn(example,args=(world_size,),nprocs=world_size,join=True)if __name__=="__main__":# Environment variables which need to be# set when using c10d's default "env"# initialization mode.os.environ["MASTER_ADDR"] = "localhost"os.environ["MASTER_PORT"] = "10086"main()以下为multiprocessing的设计demoimport torchimport torch.distributed as distimport torch.multiprocessing as mpfrom torch.nn.parallel import DistributedDataParallel as DDPdef setup(rank, world_size):dist.init_process_group(backend='nccl',init_method='tcp://localhost:12355',rank=rank,world_size=world_size)torch.cuda.set_device(rank)dist.barrier()def cleanup():dist.destroy_process_group()def demo_basic(rank, world_size):setup(rank, world_size)model = torch.nn.Linear(10, 10).to(rank)ddp_model = DDP(model, device_ids=[rank])inputs = torch.randn(20, 10).to(rank)outputs = ddp_model(inputs)print(f"Rank {rank} outputs: {outputs}")cleanup()def main():world_size = torch.cuda.device_count()mp.spawn(demo_basic, args=(world_size,), nprocs=world_size, join=True)if __name__ == "__main__":main()
4.2 多卡训练多进程调试办法(Pycharm为例)
首先如果读者使用的是multiprocessing的方式,那么直接使用本地工具运行和调试即可,如果使用torchrun的方式,那么我们需要手动配置Run/Debug Configurations,根据4.1,我们要找到原型文件launch.py,以笔者的环境为例,我的launch文件在/usr/local/mambaforge/envs/led/lib/python3.7/site-packages/torch/distributed/launch.py,添加一个配置,笔者命名为torchrun,在Script path一列选择launch.py,参数

在torchrun等方式下,我们可以看到其实有多个进程或线程启动,而默认的调试窗口只能提供主进程的代码流程断点,此时需要看启动进程的pid
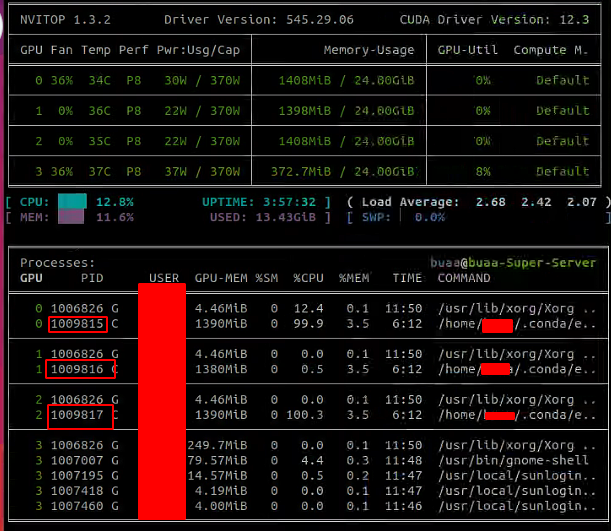
根据pid绑定到对应的进程上
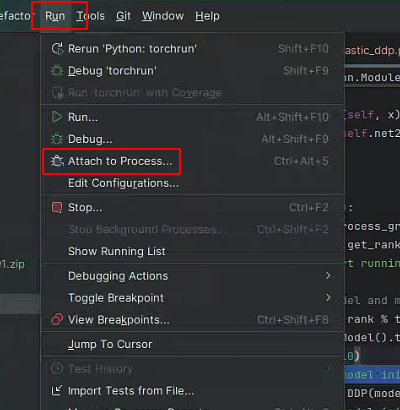
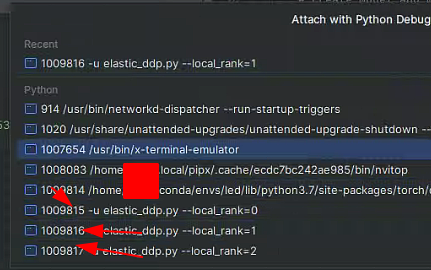
可以看到断点可以断住第二块卡的程序了
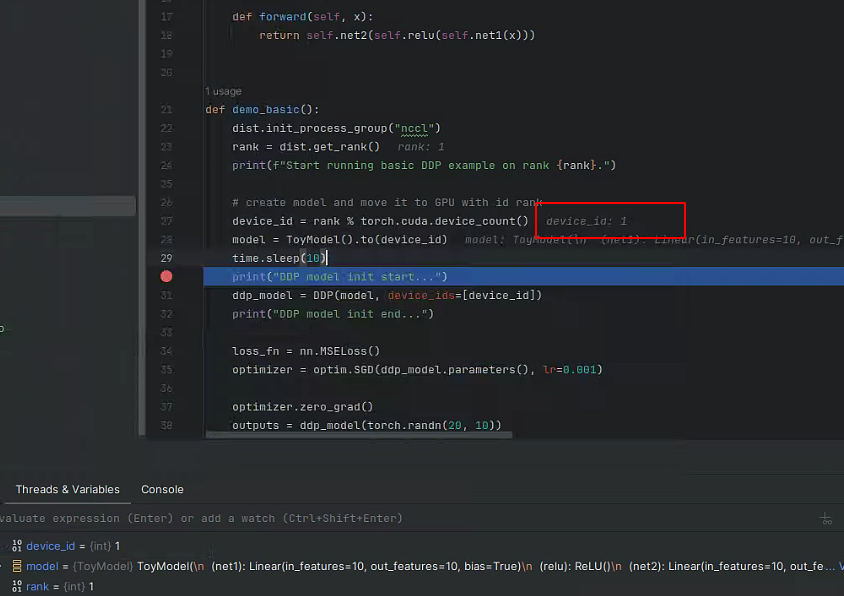
测试代码,启动方式torchrun

import timeimport torchimport torch.distributed as distimport torch.nn as nnimport torch.optim as optimfrom torch.nn.parallel import DistributedDataParallel as DDPclass ToyModel(nn.Module):def __init__(self):super(ToyModel, self).__init__()self.net1 = nn.Linear(10, 10)self.relu = nn.ReLU()self.net2 = nn.Linear(10, 5)def forward(self, x):return self.net2(self.relu(self.net1(x)))def demo_basic():dist.init_process_group("nccl")rank = dist.get_rank()print(f"Start running basic DDP example on rank {rank}.")# create model and move it to GPU with id rankdevice_id = rank % torch.cuda.device_count()model = ToyModel().to(device_id)time.sleep(10)print("DDP model init start...")ddp_model = DDP(model, device_ids=[device_id])print("DDP model init end...")loss_fn = nn.MSELoss()optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)optimizer.zero_grad()outputs = ddp_model(torch.randn(20, 10))labels = torch.randn(20, 5).to(device_id)loss_fn(outputs, labels).backward()optimizer.step()if __name__ == "__main__":demo_basic()
注意:强制终止DDP的程序可能会使得显存占用未释放,此时需要找出nccl监听的端口,例如笔者是29500
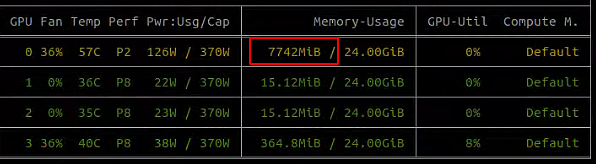

附:参考链接
DP与DDP的区别:https://zhuanlan.zhihu.com/p/343951042?utm_id=0
DDP初始化:https://www.cnblogs.com/rossiXYZ/p/15584032.html
常见卡死问题:https://blog.csdn.net/weixin_42001089/article/details/122733667
https://www.cnblogs.com/azureology/p/16632988.html
https://github.com/IDEA-CCNL/Fengshenbang-LM/issues/123
NCCL:https://zhuanlan.zhihu.com/p/667221519
NCCL参数:
https://zhuanlan.zhihu.com/p/661597951
init_process_group:
https://blog.csdn.net/m0_37400316/article/details/107225030
参数检测:
https://blog.csdn.net/weixin_46552088/article/details/138687997
分布式训练架构:https://zhuanlan.zhihu.com/p/689464092
https://zhuanlan.zhihu.com/p/706298084
点击pytorch多GPU训练简明教程可查看全文















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









