







来源:专知
本文约1000字,建议阅读5分钟
在强化学习中简单地执行这种初始化可能会导致在新任务的在线交互过程中性能显著下降。
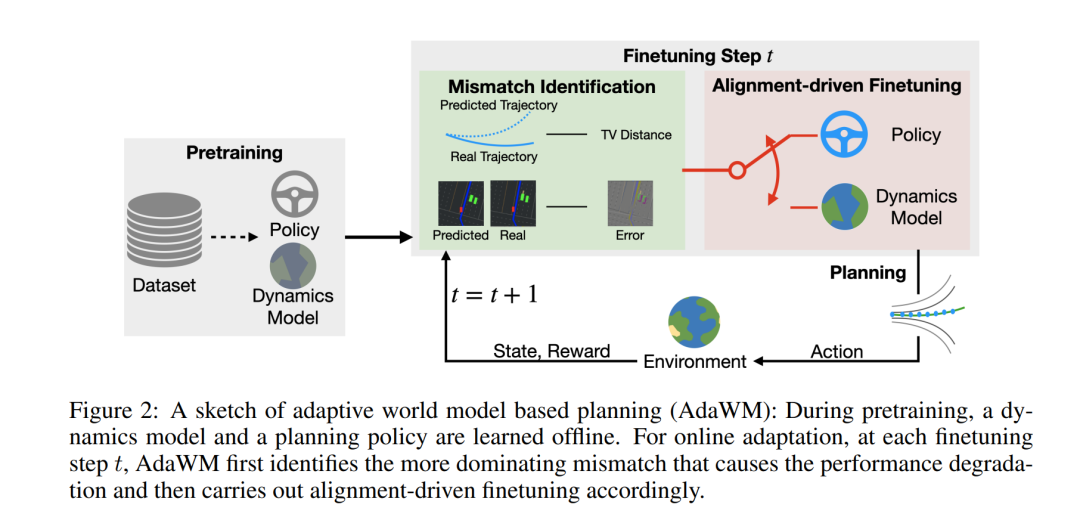
世界模型驱动的强化学习(RL)已成为自动驾驶领域一个有前景的方法,它通过学习潜在的动态模型,并利用该模型来训练规划策略。为了加速学习过程,通常采用预训练-微调范式,其中在线强化学习通过一个预训练的模型初始化,并且策略是在离线学习的。然而,在强化学习中简单地执行这种初始化可能会导致在新任务的在线交互过程中性能显著下降。为了解决这一挑战,我们首先分析了性能下降的原因,并识别出了其中的两个主要根本原因:规划策略的不匹配和动态模型的不匹配,这些问题源于分布变化。我们进一步分析了这些因素在微调过程中对性能下降的影响,研究结果表明,微调策略的选择在缓解这些影响方面起到了关键作用。接着,我们提出了AdaWM,一种基于自适应世界模型的规划方法,包含两个关键步骤:(a)不匹配识别,它量化了不匹配的程度并为微调策略提供指导;(b)基于对齐的微调,它根据需要选择性地更新策略或模型,并使用高效的低秩更新方法。通过在具有挑战性的CARLA自动驾驶任务上的大量实验,AdaWM显著改善了微调过程,从而在自动驾驶系统中实现了更强大且高效的性能。
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 2111
2111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









