








作者:阿尼·辛格
翻译: 陈之炎
校对:丁楠雅
本文约4200字,建议阅读10+分钟。
本文将研究MLE是如何工作的,以及它如何用于确定具有任何分布的模型的系数。
简介
解释模型如何工作是数据科学中最为基本最为关键的问题之一。当你建立了一个模型之后,它给了你预期的结果,但是它背后的过程是什么呢?作为一个数据科学家,你需要对这个经常被问到的问题做出解答。
例如,假设您建立了一个预测公司股价的模型。您注意到夜深人静的时候,股票价格上涨得很快。背后可能有多种原因,找出可能性最大的原因便是最大似然估计的意义所在。这一概念常被用于经济学、MRIs、卫星成像等领域。
来源:YouTube
在这篇文章中,我们将研究最大似然估计(以下简称MLE)是如何工作的,以及它如何用于确定具有任何分布的模型的系数。理解MLE将涉及到概率和数学,但我将尝试通过例子使它更通俗易懂。
注:如前所述,本文假设您已经了解概率论的基本知识。您可以通过阅读这篇文章来澄清一些基本概念:
《每个数据科学专业人员都应该知道的概率分布常识》:
https://www.analyticsvidhya.com/blog/2017/09/6-probability-distributions-data-science/
目录
为什么要使用最大似然估计(MLE)?
通过一个实例了解MLE
进一步了解技术细节
-
分布参数
似然
对数似然
最大似然估计
利用MLE确定模型系数
R语言的MLE实现
为什么要使用最大似然估计(MLE)?
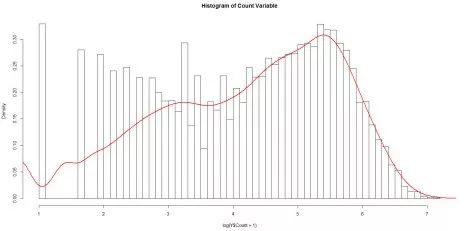
假设我们想预测活动门票的销售情况。数据的直方图和密度如下。

你将如何为这个变量建模?该变量不是正态分布的,而且是不对称的,因此不符合线性回归的假设。一种常用的方法是对变量进行对数、平方根(sqrt)、倒数等转换,使转换后的变量服从正态分布,并进行线性回归建模。
让我们试试这些转换,看看结果如何:
对数转换:
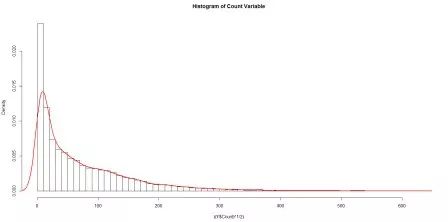
平方根转换:
倒数转换:
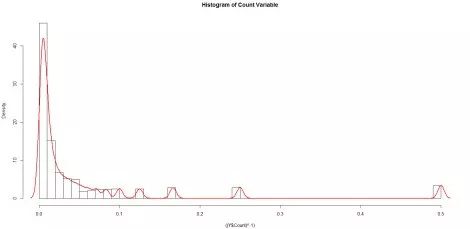
所有这些都不接近正态分布,那么我们应该如何对这些数据进行建模,才能不违背模型的基本假设?如何利用正态分布以外的其他分布来建模这些数据呢?如果我们使用了不同的分布,又将如何来估计系数?
这便是最大似然估计(MLE)的主要优势。
举一个例子来加深对MLE的理解
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









