









决策树的演化:ID3->C4.5->CART。目前sklearn里使用的是CART树

下面从图表所示的几个维度,对比下这三种决策树
1 如何选择要划分的特征
1.1 我们的目的
我们要做的事,是要构造一棵决策树,有好的分类效果(叶子节点纯)或回归效果(预测值与真实值的差距小),同时高度低(更快更简单的进行划分,不易过拟合)
1.1.2 根据哪个特征划分,分类/回归效果更好?
1.1.2.1 分类
对于分类而言,一般使用信息熵或基尼系数,用来表示其混乱程度。其中信息熵可用来计算信息增益和信息增益率,用于ID3和C4.5决策树的特征选择,而基尼系数直接用于CART分类决策树的特征选择。公式如下:
信息熵
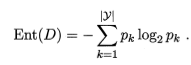
信息增益
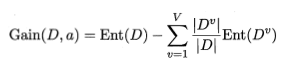
信息增益率
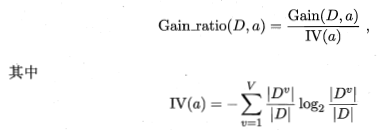
基尼系数
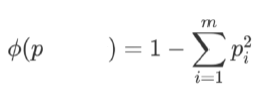
下面以西瓜书的例子为例,展示下如何计算信息熵、信息增益、信息增益率
信息熵
信息增益
以色泽划分的信息增益
以其它特征划分的信息增益
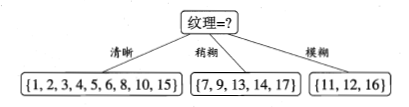
很明显,纹理的信息增益是最大的,说明从根结点出发,先经过纹理这一特征进行划分,纯度的提升是最多的,所以首选纹理
由于纹理的特征值有清晰、稍糊、模糊三类,因此经过纹理这一特征后,会分出3个叉(注意,这里讨论的是多叉的情况,实际上CART树是二叉树)
接下来就对分出来的每一个叉,计算信息增益(此时纹理特征就不必再考虑了),再继续向下分叉
信息增益率
选择信息增益作为我们的划分特征的指标有个弊端,那就是如果某个指标的特征值特别多,那么更可能选中这个指标作为我们的划分特征
考虑极端的情况,如果我们对编号这一列计算其信息增益,会发现其信息增益为0.998,是所有特征里最高的,但是很明显,以编号划分并不是一个好的选择,于是引入了信息增益率来克服信息增益的缺点
根据上面的公式,计算信息增益率,是在信息增益的基础上,除以IV
色泽IV=-6/17np.log2(6/17)-6/17np.log2(6/17)-5/17np.log2(5/17)=1.58
根蒂IV=-12/17np.log2(12/17)-5/17*np.log2(5/17)=0.87

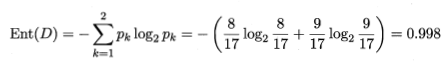
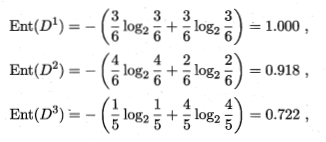
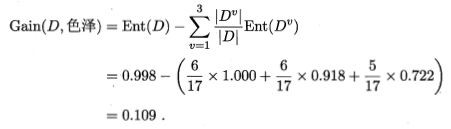

总结
ID3:在判断先对哪个特征进行划分时,是用的信息增益进行判断
C4.5:信息增益的缺点在于会倾向于选择类别更多的特征,所以引入了信息增益率
CART:分类任务,使用基尼系数。回归任务,使用均方误差MSE
2 对缺失值的处理
3 输入自变量
4 目标因变量
5 剪枝
预剪枝和后剪枝

不同的后剪枝方式
https://blog.csdn.net/weixin_43216017/article/details/87534496
参考
https://blog.csdn.net/weixin_43216017/article/details/87534496
西瓜书















 1007
1007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









