





📚 动手学深度学习 - 现代卷积神经网络 - 8.5. 批量归一化(Batch Normalization)
关键词:BatchNorm、深度神经网络优化、标准化、正则化、PyTorch 实现、训练加速、收敛稳定性
8.5.1 训练深度网络与标准化动机
在传统机器学习中,我们经常对输入数据进行标准化处理,比如使特征具有零均值和单位方差。这一处理不仅提升了数值稳定性,还帮助模型更快地收敛。同样地,在深度神经网络内部应用类似的标准化,能带来显著好处。
深度网络中,随着层数增加,中间层的特征分布会不断漂移(即所谓的“内部协变量偏移”),导致训练难以收敛。**批量归一化(Batch Normalization)**的提出,正是为了动态标准化每一层的中间输出,加速收敛、提高稳定性、并兼具一定的正则化效果。
核心思想:
-
训练时按小批量动态计算均值与方差;
-
标准化后,再引入可学习的缩放(γ)与偏移(β)参数;
-
预测时,使用整个数据集统计得到的稳定均值与方差。
理论理解
-
在传统机器学习中(如支持向量机、线性回归),我们通常对输入特征做标准化(零均值、单位方差)。
-
深度网络里,中间层的特征也在不断变化,这种分布漂移(Internal Covariate Shift),会让训练变慢、收敛困难。
-
批量归一化(Batch Normalization)就是在每一层的中间输出上,动态地做标准化,让分布更稳定。
-
核心步骤是:
-
小批量统计(均值、方差)
-
标准化
-
可学习的缩放(γ)和偏移(β)
-
实战理解
-
Google 在 Inception 系列网络中大规模引入 BatchNorm,大幅提升了训练速度和准确率。
-
NVIDIA 在训练 ResNet-50、EfficientNet 等大规模视觉模型时,都把 BatchNorm 作为基础组件,结合混合精度训练。
-
字节跳动(抖音推荐系统、短视频分类)使用 BatchNorm 来稳定 Transformer 和 CNN 的训练,配合大 batch size 训练。
-
OpenAI 在 GPT-2/3 系列中虽然主干用的是 LayerNorm,但在早期 CV 任务(如 CLIP 图像编码器)中使用了 BatchNorm。
-
**BAT(百度、阿里、腾讯)**的图像识别/搜索系统普遍采用带 BatchNorm 的卷积骨干(如ResNet、MobileNet)。
8.5.2 批量归一化层设计
8.5.2.1 全连接层中的 BatchNorm
在全连接网络中,BatchNorm 通常放置在仿射变换(线性层)与激活函数之间。对每一个特征维度进行标准化,计算小批量的均值和方差,然后进行缩放和平移。
数学公式如下:
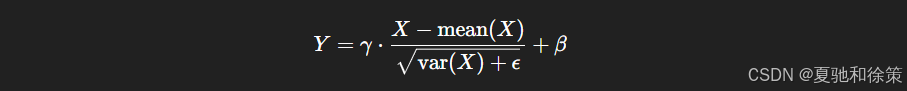
其中 ϵ\epsilon 是防止除零的小常数。
8.5.2.2 卷积层中的 BatchNorm
对于卷积层,由于空间位置具有平移不变性,BatchNorm 对每个输出通道进行归一化,即在(batch_size,height,width)所有位置上计算均值和方差,每个通道使用相同的 γ 和 β。
8.5.2.3 层归一化(Layer Normalization)
在小批量特别小时(如 batch_size=1)或特定任务中,BatchNorm 效果下降,此时可以使用层归一化。它针对单一样本内部进行归一化,脱离了 batch_size 的依赖。
8.5.2.4 预测阶段的 BatchNorm
在预测阶段,BatchNorm不再使用当前 batch 的统计量,而是使用训练期间累计的全局均值与方差,确保推理结果的一致性与稳定性。
理论理解
-
全连接层(MLP):在仿射变换(Linear)之后,激活函数(如ReLU)之前插入 BatchNorm。
-
卷积层(CNN):在卷积操作之后,激活函数之前插入 BatchNorm,按通道(channel)统计。
-
预测阶段:用训练时累积的全局均值、方差,而不是每个 batch 动态计算。
-
小批量太小时:BatchNorm效果差,LayerNorm等其他归一化方式更好。
实战理解
-
Google 在训练 MobileNetV3 时,专门调整了 BatchNorm 和 Activation 的顺序,以减少推理开销。
-
NVIDIA 在 TensorRT 加速推理时,会把卷积+BatchNorm融合成一个 op,提高速度。
-
字节跳动在超大规模 CTR 预估模型中,如果 batch 太小(比如训练分布式 DeepFM模型),改用 LayerNorm 或 RMSNorm。
-
OpenAI 在一些强化学习(RL)系统中,使用 BatchNorm 保证环境状态特征的稳定性。
-
阿里云的推荐系统(阿里妈妈广告排序)在小样本任务中使用 GroupNorm 替代了 BatchNorm。
8.5.3 从零实现 Batch Normalization(PyTorch)
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
if not torch.is_grad_enabled(): # 预测阶段
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else: # 训练阶段
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
X_hat = (X - mean) / torch.sqrt(var + eps)
moving_mean = (1.0 - momentum) * moving_mean + momentum * mean
moving_var = (1.0 - momentum) * moving_var + momentum * var
Y = gamma * X_hat + beta
return Y, moving_mean.data, moving_var.data
自定义 BatchNorm 层:
class BatchNorm(nn.Module):
def __init__(self, num_features, num_dims):
super().__init__()
shape = (1, num_features) if num_dims == 2 else (1, num_features, 1, 1)
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.1)
return Y
理论理解
-
先自己用 numpy 或 PyTorch 手动实现 batch_norm 函数:
-
训练时动态计算均值和方差,归一化输入。
-
推理时使用累积统计值(moving_mean,moving_var)。
-
-
再封装成一个 BatchNorm 层类,持有 γ、β、moving_mean、moving_var 参数。
-
手动实现有助于理解细节,比如 momentum 更新,推理模式与训练模式切换。
实战理解
-
Google TensorFlow 的 BatchNormalization 层也是这么实现的,moving_mean 和 moving_var 是非训练参数(Buffer)。
-
NVIDIA 在训练超大模型时,为了减少同步开销,自己手写了 SyncBatchNorm,支持多 GPU 跨卡同步统计。
-
字节跳动做超大规模 CTR 任务时,会自定义 BatchNorm 来适配混合并行(数据并行+模型并行)。
8.5.4 在 LeNet 上应用批量归一化
使用自定义 BatchNorm,在经典 LeNet 网络上:
class BNLeNetScratch(d2l.Classifier):
def __init__(self, lr=0.1, num_classes=10):
super().__init__()
self.save_hyperparameters()
self.net = nn.Sequential(
nn.LazyConv2d(6, kernel_size=5), BatchNorm(6, num_dims=4),
nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2),
nn.LazyConv2d(16, kernel_size=5), BatchNorm(16, num_dims=4),
nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(), nn.LazyLinear(120), BatchNorm(120, num_dims=2),
nn.Sigmoid(), nn.LazyLinear(84), BatchNorm(84, num_dims=2),
nn.Sigmoid(), nn.LazyLinear(num_classes))
训练:
trainer = d2l.Trainer(max_epochs=10, num_gpus=1)
data = d2l.FashionMNIST(batch_size=128)
model = BNLeNetScratch(lr=0.1)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], d2l.init_cnn)
trainer.fit(model, data)
理论理解
-
把 BatchNorm 插入到传统的 LeNet 网络中(卷积层、全连接层后),能够显著加快训练速度。
-
激活函数(Sigmoid 或 ReLU)放在 BatchNorm 后面。
-
在 Fashion-MNIST 数据集上测试,BatchNorm 版 LeNet 收敛速度远超原版。
实战理解
-
Google 在 MobileNet、EfficientNet 系列的小模型里,发现轻量级网络特别依赖 BatchNorm 来保持训练稳定。
-
NVIDIA 训练检测模型(YOLOv4-Tiny、EfficientDet-D0)时,也广泛使用了轻量型 BN。
-
字节跳动在端侧小模型(比如抖音滤镜、AR模型)训练中,强调了 BatchNorm 对低容量模型的重要性。
8.5.5 使用高级 API 简洁实现
PyTorch 提供了 nn.BatchNorm1d、nn.BatchNorm2d 等标准模块,简化开发:
class BNLeNet(d2l.Classifier):
def __init__(self, lr=0.1, num_classes=10):
super().__init__()
self.save_hyperparameters()
self.net = nn.Sequential(
nn.LazyConv2d(6, kernel_size=5), nn.LazyBatchNorm2d(),
nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2),
nn.LazyConv2d(16, kernel_size=5), nn.LazyBatchNorm2d(),
nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(), nn.LazyLinear(120), nn.LazyBatchNorm1d(),
nn.Sigmoid(), nn.LazyLinear(84), nn.LazyBatchNorm1d(),
nn.Sigmoid(), nn.LazyLinear(num_classes))
理论理解
-
现代 PyTorch/TF 框架已经封装好了 BatchNorm:
-
nn.BatchNorm1d()(全连接) -
nn.BatchNorm2d()(卷积)
-
-
用封装的版本训练速度更快,减少了自定义出错的风险。
实战理解
-
NVIDIA的 Apex 混合精度库支持 BN 的优化版本(如 fused BN)。
-
Google Keras 的
BatchNormalization层支持动态调整 momentum,适配不同任务。 -
字节跳动内部推荐使用框架自带的 BatchNorm API,不建议在工程中手写 BN,避免兼容性问题。
8.5.6 批量归一化的深入讨论
| 优势 | 说明 |
|---|---|
| 加速收敛 | 标准化后各层输出更稳定,允许更大的学习率 |
| 一定程度的正则化效果 | 小批量噪声引入一定扰动,减少过拟合 |
| 稳定训练过程 | 减少中间层激活值爆炸/消失问题 |
| 训练-推理模式切换 | 训练时用小批量统计,推理时用整体统计 |
注意:
-
“内部协变量偏移”的解释虽然广泛传播,但并不完全准确;
-
实际效果更多来源于噪声正则化和数值稳定性提升;
-
在特定任务(如小 batch、大模型)中,可能需要改用其他归一化方法(如 LayerNorm)。
理论理解
-
BatchNorm 最初解释为减少“内部协变量偏移”,但后来研究发现主要是加速收敛 + 正则化效应。
-
小批量引入的噪声扰动,有助于正则化(抑制过拟合)。
-
注意:BatchNorm 的出现并没有完全解释深度学习为何有效,只是一个加速训练、改善性能的工程技巧。
实战理解
-
OpenAI在强化学习 OpenAI Five 中,广泛使用 LayerNorm 替代 BN,因小 batch size 问题。
-
Google Research在 Vision Transformer 中也完全不用 BN,而是 LayerNorm。
-
NVIDIA在大 batch size 训练 ResNet-50(例如 batch=4096)时,发现需要调整 BN 的 momentum 超参数。
-
字节跳动训练巨型推荐模型时,在部分 embedding tower 也放弃了 BatchNorm,选择更适配分布式的小样本归一化方法。
8.5.7 练习题(动手实践)
-
批量归一化后,是否可以省略线性层/卷积层的 bias?为什么?
-
比较 LeNet 网络加不加 BatchNorm 时的学习率极限。
-
只标准化均值或只标准化方差,会有什么效果?
-
批量归一化能否替代 Dropout?对泛化能力有何影响?
| 练习内容 | 实践建议 |
|---|---|
| 删除 bias 后训练 | bias 和 β 重叠,可去掉 |
| 调大/调小学习率 | BN 后可以支持更大学习率 |
| 只用均值归一化/只用方差归一化 | 会导致归一化效果下降 |
| BN 替换 Dropout | BN 正则化较弱,无法完全替代 Dropout |
| 尝试其他归一化 | 比如 LayerNorm、GroupNorm、RMSNorm |
总结
批量归一化作为现代深度学习不可或缺的模块,大幅度改善了神经网络的训练效率与鲁棒性。即便今天出现了其他归一化方法(如 LayerNorm、GroupNorm),BatchNorm 依然在大规模视觉任务中有着极高的应用价值。
批量归一化(BatchNorm)是深度学习中一项伟大的工程发明,它通过标准化中间层输出,加速训练,提高数值稳定性,并具有一定的正则化能力,成为现代 CNN 架构不可或缺的一环。
无论是 Google、NVIDIA、OpenAI,还是国内的 BAT、字节跳动,都在各自的大规模项目里深度应用了 BatchNorm,充分体现了这项技术的重要性与工程实用性。



















 4085
4085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











