







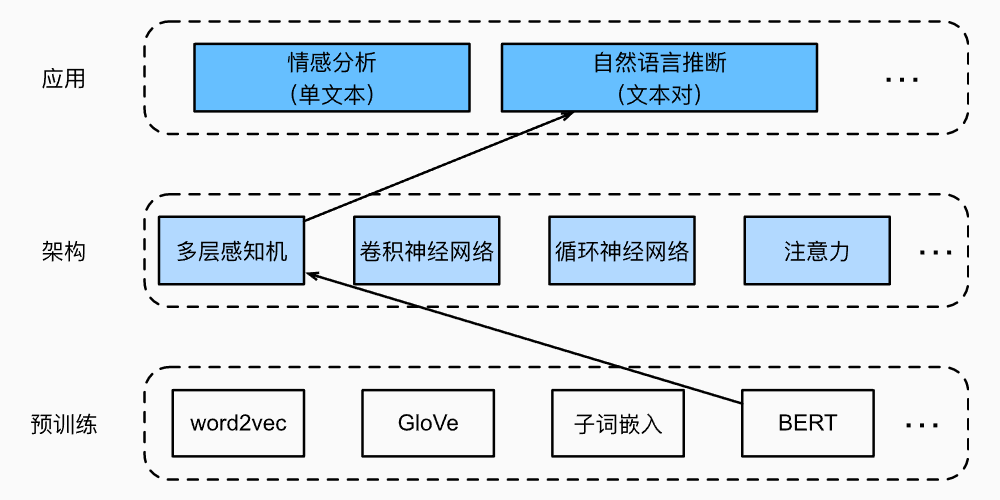
将下载一个预训练好的小版本的BERT,然后对其进行微调,以便在SNLI数据集上进行自然语言推断。
import json
import multiprocessing
import os
from mxnet import gluon, np, npx
from mxnet.gluon import nn
from d2l import mxnet as d2l
npx.set_np()加载预训练的BERT
在下面,我们提供了两个版本的预训练的BERT:“bert.base”与原始的BERT基础模型一样大,需要大量的计算资源才能进行微调,而“bert.small”是一个小版本,以便于演示。
d2l.DATA_HUB['bert.base'] = (d2l.DATA_URL + 'bert.base.zip',
'7b3820b35da691042e5d34c0971ac3edbd80d3f4')
d2l.DATA_HUB['bert.small'] = (d2l.DATA_URL + 'bert.small.zip',
'a4e718a47137ccd1809c9107ab4f5edd317bae2c')两个预训练好的BERT模型都包含一个定义词表的“vocab.json”文件和一个预训练参数的“pretrained.params”文件。我们实现了以下load_pretrained_model函数来加载预先训练好的BERT参数。
def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens,
num_heads, num_layers, dropout, max_len, devices):
data_dir = d2l.download_extract(pretrained_model)
# 定义空词表以加载预定义词表
vocab = d2l.Vocab()
vocab.idx_to_token = json.load(open(os.path.join(data_dir,
'vocab.json')))
vocab.token_t 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1353
1353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









