







从上下文无关到上下文敏感
以EMLO为例
通过将整个序列作为输入,ELMo是为输入序列中的每个单词分配一个表示的函数。具体来说,ELMo将来自预训练的双向长短期记忆网络的所有中间层表示组合为输出表示。然后,ELMo的表示将作为附加特征添加到下游任务的现有监督模型中,例如通过将ELMo的表示和现有模型中词元的原始表示(例如GloVe)连结起来。一方面,在加入ELMo表示后,冻结了预训练的双向LSTM模型中的所有权重。另一方面,现有的监督模型是专门为给定的任务定制的。利用当时不同任务的不同最佳模型,添加ELMo改进了六种自然语言处理任务的技术水平:情感分析、自然语言推断、语义角色标注、共指消解、命名实体识别和问答。
BERT:把两个最好的结合起来
ELMo对上下文进行双向编码,但使用特定于任务的架构;而GPT是任务无关的,但是从左到右编码上下文。BERT(来自Transformers的双向编码器表示)结合了这两个方面的优点。它对上下文进行双向编码,并且对于大多数的自然语言处理任务只需要最少的架构改变。通过使用预训练的Transformer编码器,BERT能够基于其双向上下文表示任何词元。在下游任务的监督学习过程中,BERT在两个方面与GPT相似。首先,BERT表示将被输入到一个添加的输出层中,根据任务的性质对模型架构进行最小的更改,例如预测每个词元与预测整个序列。其次,对预训练Transformer编码器的所有参数进行微调,而额外的输出层将从头开始训练。下图描述了ELMo、GPT和BERT之间的差异。
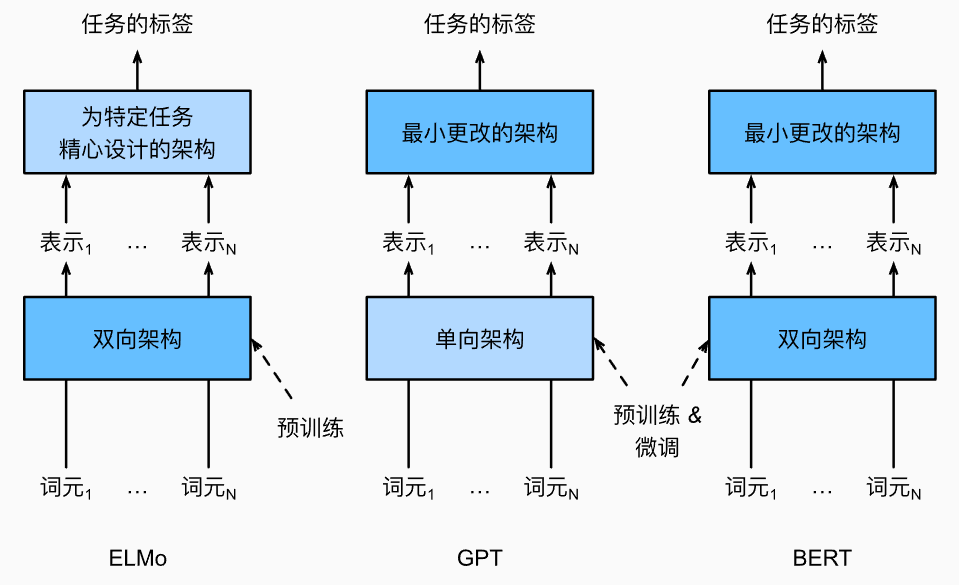
BERT进一步改进了11种自然语言处理任务的技术水平,这些任务分为以下几个大类:
(1)单一文本分类(如情感分析)
(2)文本对分类(如自然语言推断)
(3)问答
(4)文本标记(如命名实体识别)
下面是针对BERT进行的微调。
from mxnet import gluon, np, npx
from mxnet.gluon import nn
from d2l import mxnet as d2l
npx.set_np()输入表示
在自然语言处理中,有些任务(如情感分析)以单个文本作为输入,而有些任务(如自然语言推断)以一对文本序列作为输入。BERT输入序列明确地表示单个文本和文本对。当输入为单个文本时,BERT输入序列是特殊类别词元“<cls>”、文本序列的标记、以及特殊分隔词元“<sep>”的连结。当输入为文本对时,BERT输入序列是“<cls>”、第一个文本序列的标记、“<sep>”、第二个文本序列标记、以及“<sep>”的连结。我们将始终如一地将术语“BERT输入序列”与其他类型的“序列”区分开来。例如,一个BERT输入序列可以包括一个文本序列或两个文本序列。
为了区分文本对,根据输入序列学到的片段嵌入eA和eB分别被添加到第一序列和第二序列的词元嵌入中。对于单文本输入,仅使用eA。
下面的get_tok
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









