






Online Learning定义
传统的批量算法的每次迭代是对全体训练数据集进行计算(例如计算全局梯度),优点是精度和收敛还可以,缺点是无法有效处理大数据集(此时全局梯度计算代价太大),且没法应用于数据流做在线学习。而在线学习算法的特点是:每来一个训练样本,就用该样本产生的loss和梯度对模型迭代一次,一个一个数据地进行训练,因此可以处理大数据量训练和在线训练。准确地说,Online Learning并不是一种模型,而是一种模型的训练方法,Online Learning能够根据线上反馈数据,实时快速地进行模型调整,使得模型及时反映线上的变化,提高线上预测的准确率。Online Learning的流程包括:将模型的预测结果展现给用户,然后收集用户的反馈数据,再用来训练模型,形成闭环的系统。
Online Learning问题
- 难以得到稀疏解
- 稀疏解的意义:
- 特征选择,抛弃无用的特征
- 避免过拟合
- 节省存储空间和计算资源,工业界的模型特征在亿级别到百亿级
为什么Batch Training能得到稀疏解,Online Learning不行
简单来说,Batch Training沿着全局梯度方向进行下降,Online Learning每次沿着某个样本的梯度方向进行下降,即使采用L1正则化的方式,也很难产生稀疏解。(关于L1正则化为什么可以得到稀疏解可以参考l1 相比于 l2 为什么容易获得稀疏解? - 知乎)
Online Learning优化目标
直观理解二者的区别,Loss是在一次batch计算完,得到了新的Wn,然后计算loss,追求loss最小。而Regret是每t个样本来,更新w后得到Wt,追求累计regret最小,有点贪心的思想。

经典的Online Learning的方法
- SGD:学习率恒定的梯度下降法
- OGD:学习率随着步长变化的(变小)梯度下降法
- 简单截断法:对参数进行截断的SGD(每训练k轮,进行一次截断,截断小于阈值θ的参数。优点简单粗暴,可以得到稀疏解;缺点会丢失比较稀疏的重要特征,实践中存在精度差)
- TG :对参数进行截断的SGD(每训练k轮,进行一次计算,“截断”小于阈值θ的参数。截断方式更加平滑;可以得到稀疏解,实践中精确度效果较差)
- FOBOS: TG截断法的延伸。基于SGD,把权重的更新分为两步,第一步是不带正则的梯度下降,第二步是加上正则后的微调
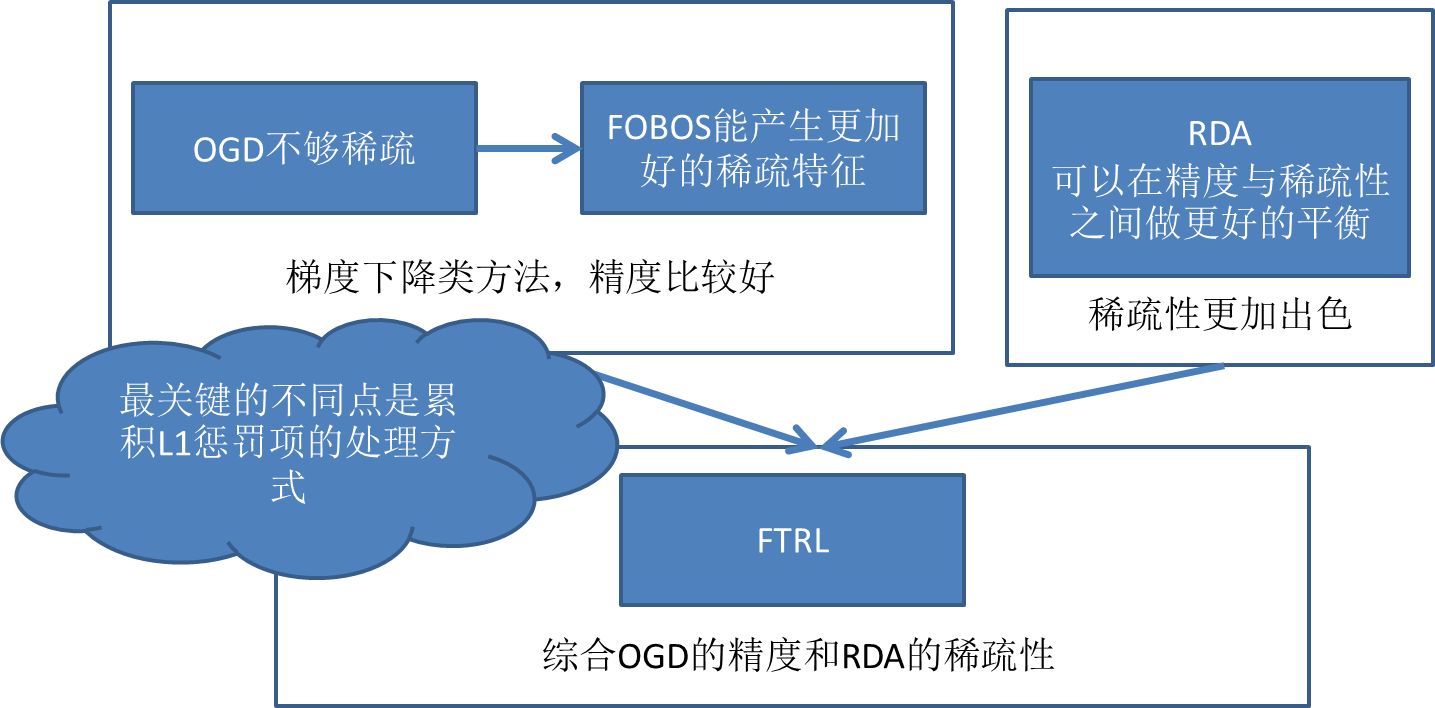
其他内容后续补充















 5362
5362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









