









label smoothing是一种在分类问题中,防止过拟合的方法。
交叉熵损失函数在多分类任务中存在的问题
多分类任务中,神经网络会输出一个当前数据对应于各个类别的置信度分数,将这些分数通过softmax进行归一化处理,最终会得到当前数据属于每个类别的概率。
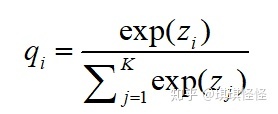
然后计算交叉熵损失函数:

训练神经网络时,最小化预测概率和标签真实概率之间的交叉熵,从而得到最优的预测概率分布。最优的预测概率分布是:

神经网络会促使自身往正确标签和错误标签差值最大的方向学习,在训练数据较少,不足以表征所有的样本特征的情况下,会导致网络过拟合。
label smoothing(标签平滑)
label smoothing可以解决上述问题,这是一种正则化策略,主要是通过soft one-hot来加入噪声,减少了真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果。
增加label smoothing后真实的概率分布有如下改变:

交叉熵损失函数的改变如下:

最优预测概率分布如下:

这里的α是任意实数,最终模型通过抑制正负样本输出差值,使得网络有更强的泛化能力。
Tensorflow代码中如何增加label smoothing
def smoothing_cross_entropy(logits,labels,vocab_size,confidence):
with tf.name_scope("smoothing_cross_entropy", values=[logits, labels]):
# Low confidence is given to all non-true labels, uniformly.
low_confidence = (1.0 - confidence) / to_float(vocab_size - 1)
# Normalizing constant is the best cross-entropy value with soft targets.
# We subtract it just for readability, makes no difference on learning.
normalizing = -(
confidence * tf.log(confidence) + to_float(vocab_size - 1) *
low_confidence * tf.log(low_confidence + 1e-20))
soft_targets = tf.one_hot(
tf.cast(labels, tf.int32),
depth=vocab_size,
on_value=confidence,
off_value=low_confidence)
xentropy = tf.nn.softmax_cross_entropy_with_logits_v2(
logits=logits, labels=soft_targets)
return xentropy - normalizing这里的confidence=1- epi
--------------------------
Inception V2中,Rethinking改进了目标函数:原来的目标函数,在单类情况下,如果某一类概率接近1,其他的概率接近0,那么会导致交叉熵取log后变得很大很大。从而导致两个问题:
1、过拟合
2、导致样本属于某个类别的概率非常的大,模型太过于自信自己的判断。
所以,使用了一种平滑方法,可以使得类别概率之间的差别没有那么大。这项改动就是label smooth,提升了0.2%个点。当然这种做法也将背景类暗含进了分类类别中(1000->1001)。
该技术实际作用如何?
label smoothing就是一种正则化的方法而已,让分类之间的cluster更加紧凑,增加类间距离,减少类内距离,避免over high confidence的adversarial examples。
推荐两篇文章,一篇是李沐mxnet团队的关于训练神经网络小技巧:
作者们亲测,label smoothing与mixup以及knowledge distillation一样,都是涨分的,模式识别、目标检测与语义分割,三大权威任务,不骗人。

然后是Hinton老带的谷歌大脑团队的这篇文章《When does label smoothing help》,论证了知识蒸馏+标签平滑是有用的,具体做法就是用硬标签先生成一个老师模型,再控制温度,训练一个基于软标签(label smoothing)的学生模型。因为之前的迁移学习、模型压缩不知道怎么把两种方法结合起来用,这篇paper提供了详尽的实验参考数据。
时过境迁,我觉得这个技术没有火,是两个原因:
1.提高泛化性,对于工业界的团队来说,其实足够多的样本就够了,Natural Training是One Pass的,而Label Smooth是Two Pass,或许跨域迁移学习可以用知识蒸馏及其变种,Label Smooth有更好的子孙方法。
2. 提高鲁棒性,在对抗攻击上,Label Smooth只能防住FGSM,而FGSM攻击是欠拟合的。














 873
873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









