









问题背景
对于分类问题,尤其是多类别分类问题中,常常把类别向量做成one-hot vector(独热向量)。
简单地说,就是对于多分类向量,计算机中往往用[0, 1, 3]等此类离散的、随机的而非有序(连续)的向量表示,而one-hot vector 对应的向量便可表示为[0, 1, 0],即对于长度为n 的数组,只有一个元素是1,其余都为0。
因此表征我们已知样本属于某一类别的概率是为1的确定事件,属于其他类别的概率则均为0。
此处就可引出一对概念:
- 硬编码的类别标签向量是二值的,如,一个类别标签是正类别-1,其他类别标签为负类别-0.
- 软编码的类别标签中,正类别具有最大的概率;其他类别也具有非常小的概率.
one-hot 带来的问题:
对于损失函数,我们需要用预测概率去拟合真实概率,而拟合one-hot的真实概率函数会带来两个问题:
1)无法保证模型的泛化能力,容易造成过拟合;
2)全概率和0概率鼓励所属类别和其他类别之间的差距尽可能加大,而由梯度有界可知,这种情况很难adapt。会造成模型过于相信预测的类别。
解决方法
使用下面的 label smoothing 可以缓解这个问题:
- 原理:对于以Dirac函数分布的真实标签,我们将它变成分为两部分获得(替换)
其中,Dirac函数就是 在除了零以外的点函数值都等于零,而其在整个定义域上的积分等于1。完全对应one-hot编码的分布。
第一部分:将原本Dirac分布的标签变量替换为(1 - ϵ)的Dirac函数;
第二部分:以概率 ϵ ,在u(k)u(k) 中份分布的随机变量。
代码对应为:
def label_smoothing(inputs, epsilon=0.1):
K = inputs.get_shape().as_list()[-1] # number of channels
return ((1-epsilon) * inputs) + (epsilon / K)
代码的第一行是取Y的channel数也就是类别数
第二行就是对应公式了。
举例说明
下面用一个例子理解一下:
假设我做一个蛋白质二级结构分类,是三分类,那么K=3; 假如一个真实标签是[0, 0, 1],
取epsilon = 0.1, 新标签就变成了(1 - 0.1)× [0, 0, 1] + (0.1 / 3) = [0, 0, 0.9] + [0.0333, 0.0333, 0.0333]
= [0.0333, 0.0333, 0.9333]
实际上分了一点概率给其他两类(均匀分),让标签没有那么绝对化,留给学习一点泛化的空间。从而能够提升整体的效果。
这些是软标签,而不是硬标签(0和1)。当出现错误预测时,这将降低最终的损失,随后,模型将在较小程度上惩罚和学习错误。(不希望模型对其预测结果过度自信.)
本质上,标签平滑将帮助您的模型避免围绕错误的标签数据进行训练(如果有错误标签未清理干净,label smoothing会有点用),从而提高其健壮性和性能。(标签平滑可以降低模型的可信度,并防止模型下降到过拟合所出现的损失的深度裂缝里.)
label_smoohing相当于一种正则方式,
- 在相对较小的模型上,精度提升不明显甚至会有所下降,下表展示了ResNet18在ImageNet-1k上使用label_smoothing前后的精度指标。可以明显看到,在使用label_smoothing后,精度有所下降。
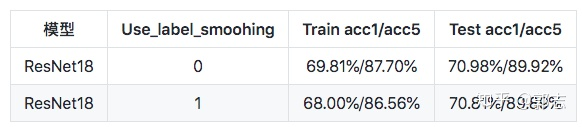
- 较大的模型使用label smoothing可以有效的提升模型的精度,较小的模型使用此种方法可能会降低模型精度。
所以在决定是否使用label_smoohing前,需要评估模型的大小和任务的难易程度。
个人理解(不一定准确)
直白地说,label smoothing就是将标签由0,1转换成小数。从交叉熵loss公式可以看出,经过LS后的标签算loss就相当于在原loss前乘了个系数。总的来看loss都比原来one-not标签时缩小了。
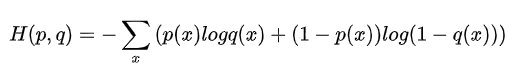
突然联想到了focal loss,计算方式如下:
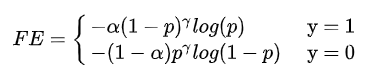
感觉这个LS和Focal Loss只保留α系数时很像,但实际作用还是不同。
- Focal Loss的阿尔法是调节正负样本比例不均衡造成的影响。
- LS是防止过拟合,正负样本类间相聚较远,类内收缩太严重,决策面挤到一起,不具有泛化性。
LS后的loss较原先的loss,算正负样本的loss较原来都会减小,从梯度计算 或 可视化角度来看,相当于算正样本loss时,负样本会往回拉一点,不会跑的太远;算负样本loss时,正样本loss也会存在,会往反方向拉一点,也不至于跑的太远;所以会有防止过拟合的作用。

但是,LS在人脸上貌似没有作用,详细原因剖析可以参考大佬的讲解。















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









