






FlashAttention
FlashAttention一般指的是FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness这篇,当然Transformer Quality in Linear Time这篇里非要说FLASH = Fast Linear Attention with a Single Head,命名有点无语,关于FLASH的细节参考 FLASH:可能是近来最有意思的高效Transformer设计 ,下面重点写写FlashAttention:
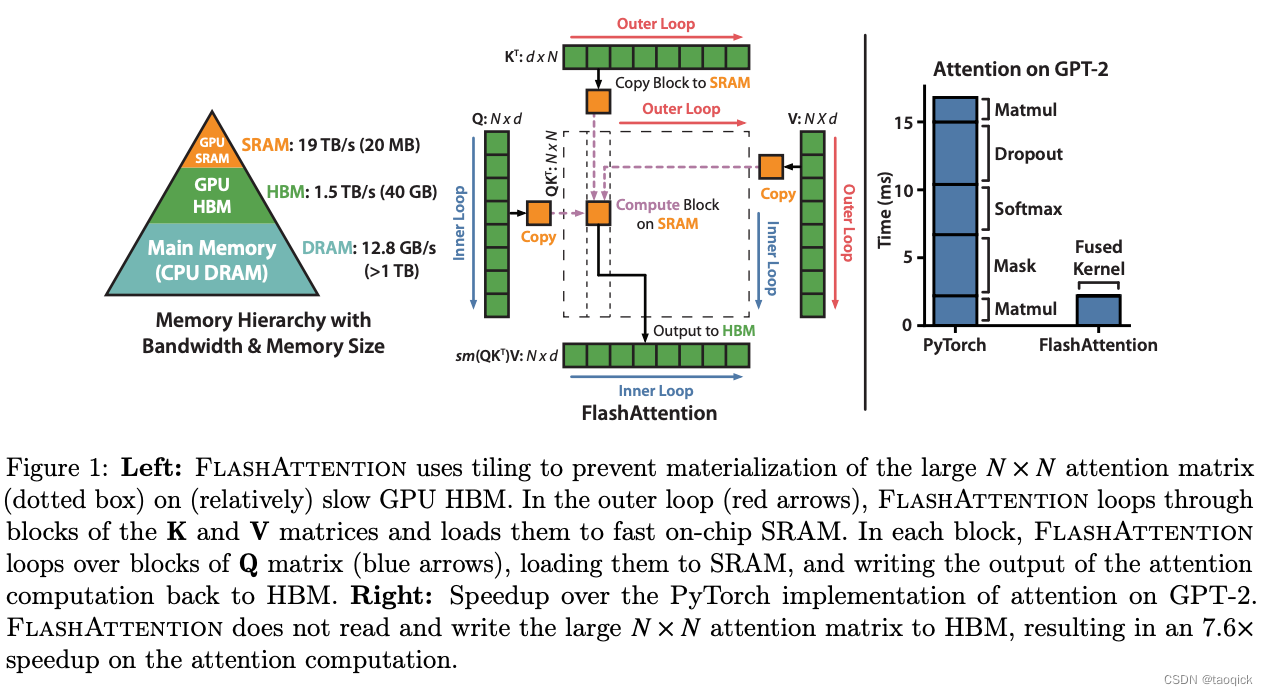
tiling中文是瓦片化,实际上就是把计算像瓦片一样铺向SRAM,保证运算不要频繁在SRAM和**HBM(High-Bandwidth Memory,HBM是高带宽内存,也就是我们常说的显存)**频繁切换,提高速度。
标准注意力的内存复杂度
对于标准注意力实现,初期我们需要把输入
Q
,
K
,
V
\mathbf{Q}, \mathbf{K}, \mathbf{V}
Q,K,V从HBM中读取,并计算完毕后把输出
O
\mathbf{O}
O写入到HBM中。
第一步把
Q
,
K
\mathbf{Q}, \mathbf{K}
Q,K读取出来计算出
S
=
Q
K
⊤
\mathbf{S}=\mathbf{Q K}^{\top}
S=QK⊤,然后把
S
\mathbf{S}
S存回去,内存访问复杂度
Θ
(
N
d
+
N
2
)
\Theta\left(N d+N^2\right)
Θ(Nd+N2)。
第二步把 S \mathbf{S} S读取出来计算出 P = softmax ( S ) \mathbf{P}=\operatorname{softmax}(\mathbf{S}) P=softmax(S),然后把 P \mathbf{P} P存回去,内存访问复杂度 Θ ( N 2 ) \Theta\left(N^2\right) Θ(N2)。
第三步把 V , P \mathbf{V}, \mathbf{P} V,P读取出来计算出 O = P V \mathbf{O}=\mathbf{P} \mathbf{V} O=PV,然后计算出结果 O \mathbf{O} O,内存访问复杂度 Θ ( N d + N 2 ) \Theta\left(N d+N^2\right) Θ(Nd+N2)。
综上所述,整体的内存访问复杂度为 Θ ( N d + N 2 ) \Theta\left(N d+N^2\right) Θ(Nd+N2)。
FlashAttention的算法
前向传播时减少对内存的访问次数
FlashAttention关键的想法就是tile(分块),把QKV都拆成块。这里一个关键点是softmax怎么算,有点绕,简单说就是把每部分分子分母的和给存下来,归一化到相同的比例。下面是个具体的例子,
l
_
p
r
e
l\_pre
l_pre是分母缩最大倍数后的和,也是最绕的点。假设QK结果是[1,2],那么softmax结果就是
[
e
1
e
1
+
e
2
,
e
2
e
1
+
e
2
]
[\frac{e^1}{e^1+e^2},\frac{e^2}{e^1+e^2}]
[e1+e2e1,e1+e2e2]
再乘以V的结果就是:
e
1
∗
v
1
e
1
+
e
2
+
e
2
∗
v
2
e
1
+
e
2
\frac{e^1*v_1}{e^1+e^2}+\frac{e^2*v_2}{e^1+e^2}
e1+e2e1∗v1+e1+e2e2∗v2
如果拆成两步算,第一步:
c
u
r
_
s
u
m
=
e
1
∗
v
1
e
1
m
_
p
r
e
=
m
a
x
(
e
1
)
=
e
1
,
是分子
e
的和
l
_
p
r
e
=
s
u
m
(
e
1
)
=
e
1
,
是分母
e
的和
cur\_sum = \frac{e^1*v_1}{e^1} \\ m\_pre = max(e^1)=e^1,是分子e的和 \\ l\_pre = sum(e^1)=e^1,是分母e的和
cur_sum=e1e1∗v1m_pre=max(e1)=e1,是分子e的和l_pre=sum(e1)=e1,是分母e的和
第二步:
m
_
c
u
r
=
m
a
x
(
e
2
,
m
_
p
r
e
)
=
e
2
l
_
p
r
e
∗
=
e
m
_
p
r
e
−
m
_
c
u
r
=
e
1
−
2
,分母缩共同倍数后相加
l
_
c
u
r
=
s
u
m
(
e
2
−
2
)
+
l
_
p
r
e
c
u
r
_
s
u
m
=
c
u
r
_
s
u
m
∗
l
_
p
r
e
l
_
c
u
r
=
e
1
∗
v
1
e
1
∗
e
−
1
e
−
1
+
e
0
c
u
r
_
s
u
m
+
=
v
2
∗
c
u
r
_
s
u
m
l
_
p
r
e
=
e
1
∗
v
1
e
1
+
e
2
+
e
2
∗
v
2
e
1
+
e
2
m\_cur = max(e^2,m\_pre)=e^2 \\ l\_pre *= e^{m\_pre - m\_cur}=e^{1-2} ,分母缩共同倍数后相加\\ l\_cur = sum(e^{2-2})+l\_pre\\ cur\_sum=cur\_sum*\frac{l\_pre}{l\_cur}=\frac{e^1*v_1}{e^1}*\frac{e^{-1}}{e^{-1}+e^0}\\ cur\_sum+=\frac{v_2*cur\_sum}{l\_pre}=\frac{e^1*v_1}{e^1+e^2}+\frac{e^2*v_2}{e^1+e^2}
m_cur=max(e2,m_pre)=e2l_pre∗=em_pre−m_cur=e1−2,分母缩共同倍数后相加l_cur=sum(e2−2)+l_precur_sum=cur_sum∗l_curl_pre=e1e1∗v1∗e−1+e0e−1cur_sum+=l_prev2∗cur_sum=e1+e2e1∗v1+e1+e2e2∗v2
这样,在前向的过程中,我们采用分块计算的方式,避免了矩阵的存储开销,整体的运算都在SRAM内进行,降低了HBM访问次数,大大提升了计算的速度,减少了对存储的消耗。详细的复杂度分析可以参考原文和https://readpaper.feishu.cn/docx/AC7JdtLrhoKpgxxSRM8cfUounsh
反向传播时使用重新计算(recompute的方式来更新梯度)
我们这里则采用重新计算的方式来计算对应的梯度。在上面前向计算的时候我们不会存储
S
,
P
\mathbf{S}, \mathbf{P}
S,P矩阵,但是我们会存储对应的指数项之和
L
L
L来进行梯度的计算。这里不展开写了,细节可以参考原文和https://readpaper.feishu.cn/docx/AC7JdtLrhoKpgxxSRM8cfUounsh
目前,Flash Attention已经集成至torch2.0,并且社区也提供了多种实现
vLLM
源自vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention这篇paper,关键的技术有两点PagedAttention和内存共享:
PagedAttention
KVCache
KV Cache是大模型推理优化的一个常用技术,该技术以空间换时间的思想,通过使用上次推理的KV缓存,可以在不影响任何计算精度的前提下,提高推理性能,降低端到端的时延。
以GPT为代表的Decoder-Only自回归语言模型在生成每一个新的 token 时,接受所有之前生成的 tokens 作为输入。然而,对于这些先前生成的 tokens,每次生成新的 token 时都需要重新计算他们的表示,这个过程造成了大量的计算浪费。KV Cache 的引入就是为了解决这个问题。
KV Cache实质上是存储了之前计算过的 key-value 对用于下一个Token的生成。在 Transformer 结构中,self-attention 中的k_proj, v_proj会将输入的每个 token 转化为一个 key 和一个 value,然后使用这些 key-value 以及当前的query对来计算下一个 token。引入 KV Cache,我们就可以将之前生成的 tokens 对应的 key-value 对存储起来,当生成新的 token 时,直接从 KV Cache 中取出这些已经计算好的 key-value 对,再把当前token的key-value做一个连结在进行计算,这样就避免了KV的重复计算,大大提高了计算效率。
到huggingface代码里看,例如Hugging Face的transformers库代码实现就比较清爽,在modeling_gpt2.py中Attention部分相关代码如下:
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
if layer_past is not None: # 当输出第一个token后,layer_past就是非None了
past_key, past_value = layer_past # 取出之前计算好的 key, value
key = torch.cat((past_key, key), dim=-2) # past_key 与当前 token 对应的 key 拼接
value = torch.cat((past_value, value), dim=-2) # past_value 与当前 token 对应的 value 拼接
if use_cache is True:
present = (key, value)
else:
present = None
整体来说,使用KV Cache包含以下两个步骤:
- 预填充阶段:在计算第一个输出token过程中,此时Cache是空的,计算时需要为每个 transformer layer 计算并保存key cache和value cache,在输出token时Cache完成填充;FLOPs同KV Cache关闭一致,存在大量gemm操作,推理速度慢,这时属于Compute-bound类型计算。
- KV Cache阶段:在计算第二个输出token至最后一个token过程中,此时Cache是有值的,每轮推理只需读取Cache,同时将当前轮计算出的新的Key、Value追加写入至Cache;FLOPs降低,gemm变为gemv操作,推理速度相对第一阶段变快,这时属于Memory-bound类型计算。
beamsearch、topk sampling、nucleus sampling等解码策略在hugging face的GenerationMixin(transformers/generation/utils.py)中均有所实现,在hugging face上的生成式模型都要继承GenerationMixin,以beamsearch为例,下面self就是继承的子类提供的根据 w 0.. i − 1 w_{0..i-1} w0..i−1给 w i w_{i} wi打分的language model,这个language model里当然要实现例如kv_cache等策略:
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)
PagedAttention
通过KV Cache的技术,我们已经可以极大地提升LLM地推理速度,但是现有的Cache仍存在一些问题,
- Large:对于LLaMA-13B中的单个序列,它占用高达1.7GB的内存。关于这个怎么算的:kvcache变量内容为((k,v), (k,v), …, (k,v)),即有L个 k,v 组成的一个元组,其中 k 和 v 的维度均为[b, n h e a d n_{head} nhead, s, head_dims]。这里可以顺带计算出每轮推理对应的 cache 数据量为 2 × L × n l a y e r s × n h e a d × h e a d _ d i m 2 \times L \times n_{layers} \times n_{head}\times head\_dim 2×L×nlayers×nhead×head_dim,这里s值等于当前轮次值。可以随着输出tokens的增长,cache数据量呈现线性增加特点。以LLaMA-13B为例,假设以 float16 来保存 KV cache,senquence长度为50,batchsize=1,则KV cache占用显存为 2 × L × n l a y e r s × n h e a d × h e a d _ d i m × 2 ( 这个 2 表示 f l o a t 16 占的 2 字节 ) = 2 ∗ 100 (序列长度) ∗ 40 (层数) ∗ 40 (头数) ∗ 5120 ( h e a d _ d i m ) ∗ 2 = 1.64 G 2 \times L \times n_{layers} \times n_{head}\times head\_dim \times 2(这个2表示float16占的2字节)=2*100(序列长度)*40(层数)*40(头数)*5120(head\_dim)*2=1.64G 2×L×nlayers×nhead×head_dim×2(这个2表示float16占的2字节)=2∗100(序列长度)∗40(层数)∗40(头数)∗5120(head_dim)∗2=1.64G(关于头数这些信息直接到google搜索LLama model card即可)。从https://zhuanlan.zhihu.com/p/624740065的分析来看,kvcache的显存大约占了模型参数显存的一半
- Dynamic:它的大小取决于序列长度,而序列长度具有高度可变和不可预测的特点。
因此,高效地管理KV Cache是一个重大挑战。现有系统(HuggingFace 默认实现是pytorch的内存分配策略)由于内存碎片化和过度预留而浪费了60%至80%的内存。
为了解决这个问题,我们引入了PagedAttention,这是一种受传统操作系统虚拟内存和分页概念启发的注意力算法。与传统的注意力算法不同,PagedAttention允许将连续的键和值存储在非连续的内存空间中。具体而言,PagedAttention将每个序列的KV缓存分成多个块,每个块包含固定数量的标记的键和值。在注意力计算过程中,PagedAttention Kernel高效地识别和获取这些块,采用并行的方式加速计算。(和ByteTransformer的思想有点像)
到vLLM开源的代码里去看,实际上PagedAttention是以加了一个cuda的核函数实现的,核心是single_query_cached_kv_attention_kernel函数的工作(https://github.com/vllm-project/vllm/blob/main/csrc/attention/attention_kernels.cu)
内存布局
由于块在内存中不需要连续存储,我们可以像操作系统的虚拟内存那样以更加灵活的方式管理键和值的缓存:可以将块看作页,标记看作字节,序列看作进程。序列的连续逻辑块通过块表映射到非连续的物理块。随着生成新的标记,序列的边长,物理块按需进行分配。
在PagedAttention中,内存浪费仅发生在序列的最后一个块中。这样就使得我们的方案接近最优的内存使用率,仅有不到4%的浪费。通过内存效率的提升,我们能够显著提升BatchSize,同时进行多个序列的推理,提高GPU利用率,从而显著提高吞吐量。
PagedAttention:Cache在物理上不必连续

使用 PagedAttention 的请求的示例生成过程
内存共享
在并行采样中,从相同的提示生成多个输出序列。在这种情况下,可以在输出序列之间共享提示的计算和内存。通过其块表,PagedAttention能够自然地实现内存共享。类似于进程共享物理页,PagedAttention中的不同序列可以通过将它们的逻辑块映射到相同的物理块来共享块。为确保安全共享,PagedAttention跟踪物理块的引用计数并实现 Copy-on-Write 机制。
通过PagedAttention的内存共享机制,极大地降低了复杂采样算法(如ParallelSampling和BeamSearch)的内存开销,使其内存使用量下降了高达55%。这项优化可以直接带来最多2.2倍的吞吐量提升,从而使得LLM服务中使用这些采样方法变得更加实用。
同时进行多输出的采样

多输出采样的物理展示

LightSeq
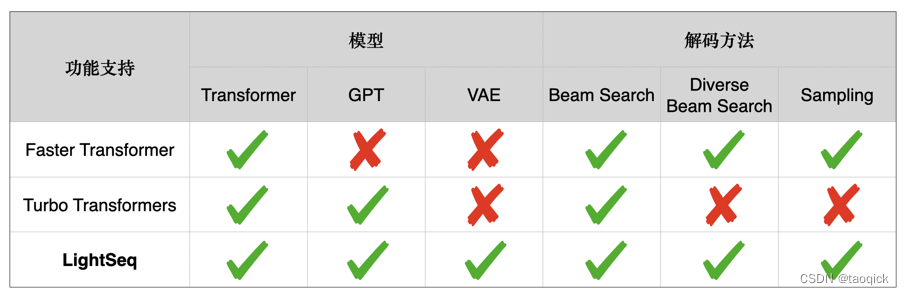
LightSeq支持BERT、GPT、Transformer、VAE 等众多模型,同时支持beam search、diverse beam search[5]、sampling等多种解码方式。下表详细列举了Faster Transformer[7]、Turbo Transformers[6]和LightSeq三种推理引擎在文本生成场景的功能差异:
这个工作大约是20年做的,部分转载自https://mp.weixin.qq.com/s/HUSYSrjG65p1TU9lS_KEUA,几个关键技术
利用 CUDA 矩阵运算库 cuBLAS提供的GEMM和自定义核函数重写了TransformerEncoder
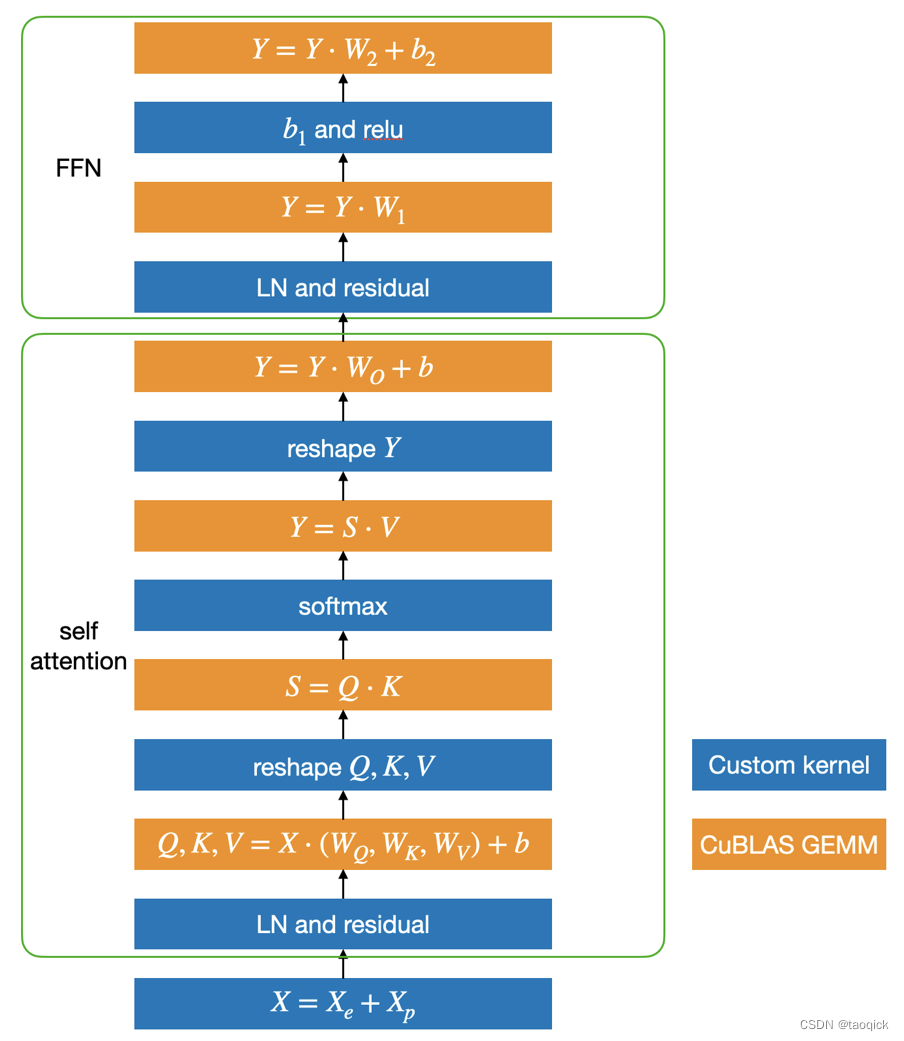
蓝色部分是自定义核函数,黄色部分是矩阵乘法。可以发现,矩阵乘法之间的运算全部都用一个定制化核函数实现了,因此大大减少了核函数调用和显存读写,最终提升了运算速度。
输入输出层融合
此外LightSeq还实现了词嵌入层和损失函数层的算子融合。对于词嵌入层,LightSeq将词表查找与放缩、位置向量融合以及dropout操作都写成了一个核函数。对于损失函数层,将交叉熵损失融合成一个核函数。通过输入输出层的融合,进一步减小了模型训练的时间,增加了显卡利用率。
在融合之前一个词嵌入层需要经过词向量查找与放缩、位置向量查找、两者相加、dropout五种运算,因此需要频繁调用核函数,非常耗时。而将这五个操作融合成一个核函数可以大大加快获取最终词表示的速度
动态显存复用
为了避免计算过程中的显存申请释放并节省显存占用,LightSeq 首先对模型中所有动态的 shape 都定义了最大值(例如最大序列长度),将所有动态shape转换为静态。接着在服务启动的时候,为计算过程中的每个中间计算结果按最大值分配显存,并对没有依赖的中间结果共用显存。这样对每个请求,模型推理时不再申请显存,做到了:不同请求的相同 Tensor 复用显存;同请求的不同 Tensor 按 shape 及依赖关系复用显存。
通过该显存复用策略,在一张 T4 显卡上,LightSeq 可以同时部署多达 8 个 Transformer big 模型(batch_size=8,最大序列长度=8,beam_size=4,vocab_size=3万)。从而在低频或错峰等场景下,大大提升显卡利用率。
层级式解码计算
在自回归序列生成场景中,最复杂且耗时的部分就是解码。LightSeq 目前已经支持了 beam search、diversity beam search、top-k/top-p sampling 等多种解码方法,并且可以配合 Transformer、GPT使用,达到数倍加速。这里我们以应用最多的 beam search 为例,介绍一下 LightSeq 对解码过程的优化。
首先来看下在深度学习框架中传统是如何进行一步解码计算的:
1.计算以每个token为结尾的序列的log probability
log_token_prob = tf.nn.log_softmax(logit) # [batch_size, beam_size, vocab_size]
log_seq_prob += log_token_prob # [batch_size, beam_size, vocab_size]
log_seq_prob = tf.reshape(log_seq_prob, [-1, beam_size * vocab_size])
- 为每个序列(batch element)找出排名topk的token
topk_log_probs, topk_indices = tf.nn.top_k(log_seq_prob, k=K)
- 根据beam id,刷新decoder中的self attention模块中的key和value的缓存
refresh_cache(cache, topk_indices)
可以发现,为了挑选概率 top-k 的 token ,必须在 [batch_size, beam_size, vocab_size]大小的 logit 矩阵上进行 softmax 计算及显存读写,然后进行 batch_size 次排序。通常 vocab_size 都是在几万规模,因此计算量非常庞大,而且这仅仅只是一步解码的计算消耗。因此实践中也可以发现,解码模块在自回归序列生成任务中,累计延迟占比很高(超过 30%)。
LightSeq 的创新点在于结合 GPU 计算特性,借鉴搜索推荐中常用的粗选-精排的两段式策略,将解码计算改写成层级式,设计了一个 logit 粗选核函数,成功避免了 softmax 的计算及对十几万元素的排序。该粗选核函数遍历 logit 矩阵两次:
• 第一次遍历,对每个 beam,将其 logit 值随机分成k组,每组求最大值,然后对这k个最大值求一个最小值,作为一个近似的top-k值(一定小于等于真实top-k值),记为R-top-k。在遍历过程中,同时可以计算该beam中logit的log_sum_exp值。
• 第二次遍历,对每个 beam,找出所有大于等于 R-top-k 的 logit 值,将(logit - log_sum_exp + batch_id * offset, beam_id * vocab_size + vocab_id)写入候选队列,其中 offset 是 logit 的下界。
在第一次遍历中,logit 值通常服从正态分布,因此算出的R-top-k值非常接近真实top-k值。同时因为这一步只涉及到寄存器的读写,且算法复杂度低,因此可以快速执行完成(十几个指令周期)。实际观察发现,在top-4设置下,根据R-top-k只会从几万token中粗选出十几个候选,因此非常高效。第二次遍历中,根据R-top-k粗选出候选,同时对 logit 值按 batch_id 做了值偏移,多线程并发写入显存中的候选队列。
粗选完成后,在候选队列中进行一次排序,就能得到整个batch中每个序列的准确top-k值,然后更新缓存,一步解码过程就快速执行完成了。
下面是k=2,词表大小=8的情况下一个具体的示例(列代表第几个字符输出,行代表每个位置的候选)。可以看出,原来需要对 16 个元素进行排序,而采用层级解码之后,最后只需要对 5 个元素排序即可,大大降低了排序的复杂度。

ByteTransformer
几个关键技术:
Transformer 变长文本 padding free
Remove padding 算法
这个算法源自字节跳动 AML 团队之前的工作 “effective Transformer”,在 NVIDIA 开源 FasterTransformer 中也有集成。ByteTransformer 同样使用该算法去除对 attention 外矩阵乘的额外计算。
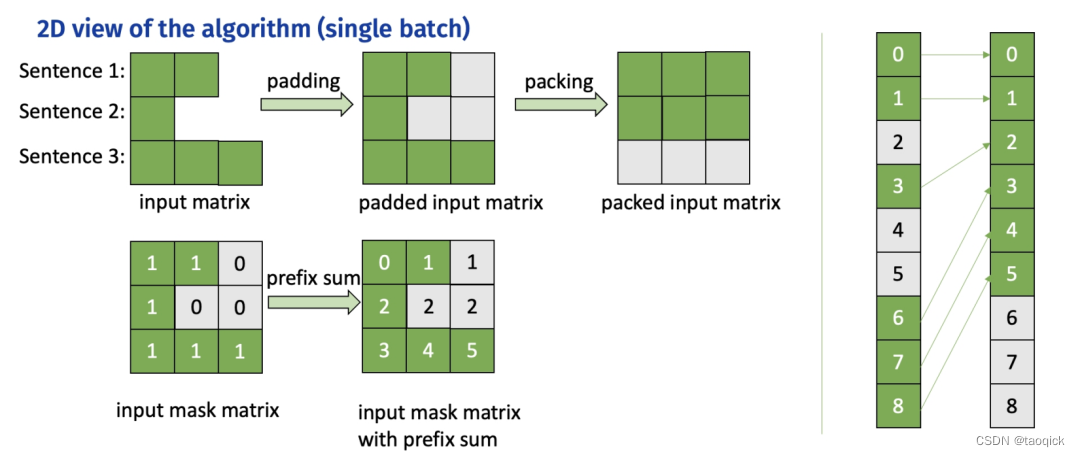
算法步骤:
- 计算 attention mask 的前缀和,作为 offsets
- 根据 offsets 把输入张量从 [batch_size, seqlen, hidden_size] 重排列为 valid_seqlen, hidden_size] ,再参与后续的矩阵乘计算,实现 padding free
FMHA (Fused Multi-Head Attention)
为了优化 attention 部分的性能,ByteTransformer 中实现了 fused multi-head attention 算子。对于 seqlen 长度,以 384 为界划分为两种实现方式:
- 对于短 seqlen, 因为可以把 QK 整行放在共享内存进行 softmax 操作,通过手写 kernel 的方式实现,矩阵乘通过调用 wmma 接口使用 TensorCore 保证高性能。
- 对于长 seqlen, 因为共享内存大小限制,不能在一个手写 kernel 中完成所有操作。基于高性能的 CUTLASS [5] grouped GEMM, 分成两个 gemm kernel 实现,并把 add_bias, softmax 等操作 fused 到 GEMM kernel 中。
CUTLASS grouped GEMM
NVIDIA 开发的 grouped GEMM 可以在一个 kernel 中完成多个独立矩阵乘问题的计算,利用这个性质可以实现 Attention 中的 padding free。
- Attention 中的两次矩阵乘操作,都可以拆解为 batch_size x head_num 个独立的矩阵乘子问题。
- 每个矩阵乘子问题,把问题大小传入到 grouped GEMM,其中 seqlen 传递真实的 valid seqlen 即可。
grouped GEMM 原理:kernel 中每个 threadblock (CTA) 固定 tiling size,每个矩阵乘子问题根据 problem size 和 tiling size,拆解为不同数量的待计算块,再把这些块平均分配到每个 threadblock 中进行计算。
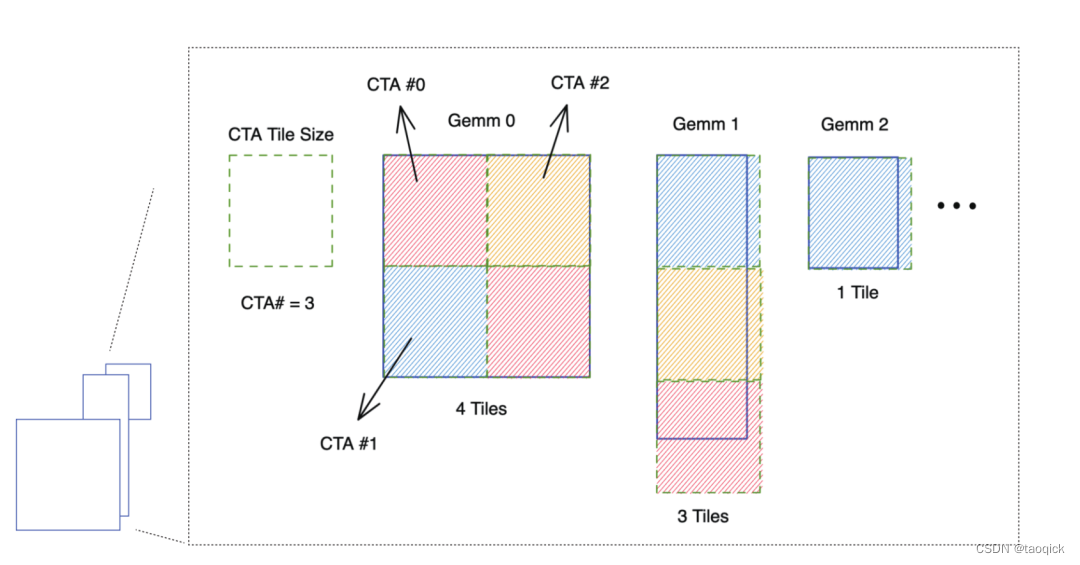
使用 grouped GEMM 实现 attention 时,由于子问题的数量 batch_size x head_num 通常较大,读取子问题参数会有不小的开销,因为从线程角度看,每个线程都需要遍历读取所有的子问题大小。
为了解决这个问题,ByteTransformer 对 grouped GEMM 中读取子问题参数进行了性能优化,使其可以忽略不计:
- 共享子问题参数。对同一个输入,不同 head 的 valid seqlen 相同,problem size 也相同,通过共享使参数存储量从 batch_size x head_num 减少到 batch_size。
- warp prefetch. 原始实现中,每个 CUDA thread 依次读取所有的子问题 problem size,效率很低。改为一个 warp 内线程读取连续的 32 个子问题参数,然后通过 warp 内线程通信交换数据,每个线程的读取次数降低到 1/32。

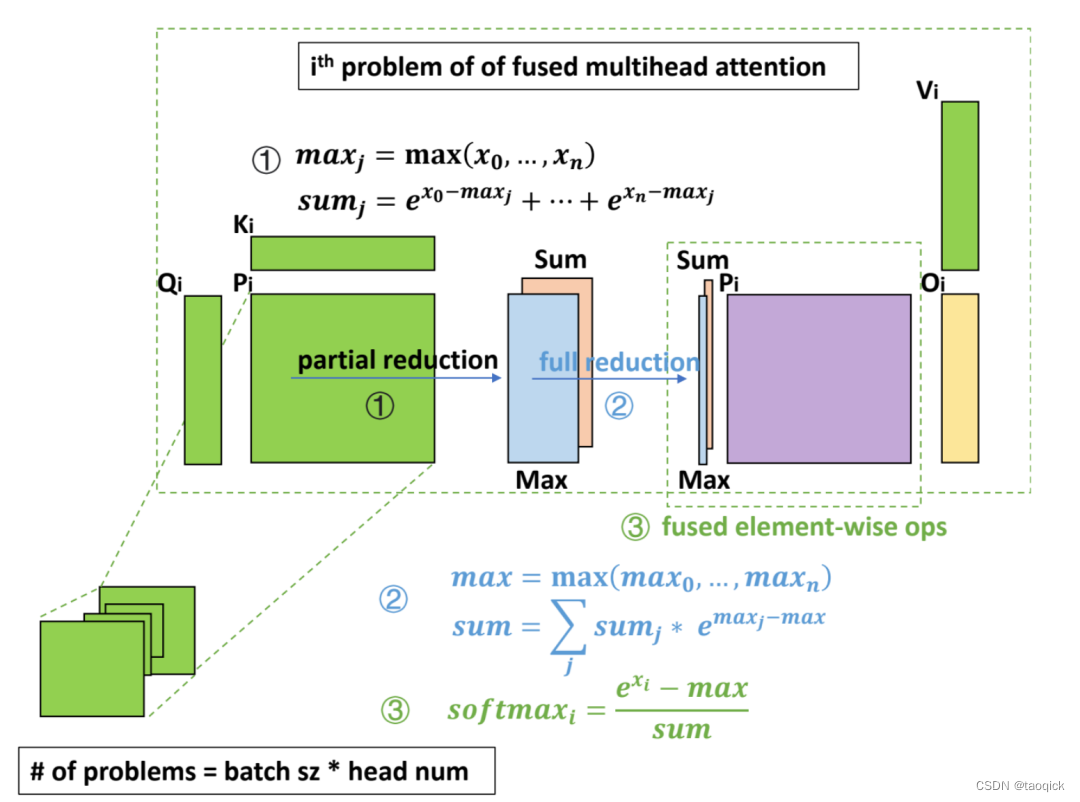
算法步骤: - partial reduction:Q x K 的 epilogue 中,每个 threadblock 内部规约,计算出 max 和 sum 两个值。
- full reduction:一个轻量级的 kernel,把每一行的 partial reduction 结果继续规约到整行的结果。
- element-wise op:修改了 CUTLASS 的代码,使其支持 prologue fusion,即在加载输入矩阵后,fuse 一些 element-wise 的操作。在 QK x V 的 prologue 中,读取当前行的规约结果,计算出 softmax 的最终结果,再参与后续的矩阵乘计算。
softmax fusion
这部分和FlashAttention其实有点像,但
FlashAttention是用一个threadblock循环计算不同的块,然后不断更新结果。ByteTransformer是
多个threadblock独立计算结果后,再用一个小kernel聚合。FlashAttention是在一个fused kernel中完成所有计算的,而ByteTransformer是拆成了两个矩阵乘的kernel。在batchsizexhead_num小的情况下,flash会因为threadblock并发度不足打满硬件sm数量,性能较差,但除此之外因为fuse的更彻底,flash性能会更好一点
为了进一步提高性能,把 Q x K 之后的 softmax 也 fuse 到矩阵乘算子中,相比单独的 softmax kernel 节省了中间矩阵的访存操作。
因为 softmax 需要对整行数据做归约,但因为共享内存大小的限制,一个 threadblock 内不能容纳整行数据,同时 threadblock 间的通信很低效,所以不能仅在 Q x K 的 epilogue 中完成整个 softmax 的操作。把 softmax 拆分成三步计算,分别 fuse 到 Q x K 的 epilogue 中, QK x V 的 prologue 中,以及中间再添加一个轻量的 kernel 做规约。
全面的 kernel fusion
除矩阵乘和 attention 的优化外,ByteTransformer 还对一些小的操作进行了全面的 kernel fusion,通过减少显存访问和 kernel launch 的开销,可以获得更极致的性能。
add-bias & LayerNorm fusion
矩阵乘之后的 add-bias 和 LayerNorm 操作,通过手写 kernel 的方式做 fusion,这部分操作在 seqlen 为 256 和 1024 的情况下分别占 10% 和 6% 的延迟,fused kernel 可以优化 61% 的性能,对单层 BERT Transformer 的性能提升 3.2%(平均 seqlen 128 - 1024 的情况)。
GEMM & add-bias & GELU fusion
通过 CUTLASS fuse epilogue 的方式,把矩阵乘后的 add-bias 操作和 GELU activation 操作 fuse 到矩阵乘 kernel 中。add-bias 和 GELU 在 seqlen 为 256 和 1024 的情况下占比耗时分别为 7% 和 5%。把 add-bias 和 GELU 融合 GEMM 可以完美隐藏这部分的访存延迟,进一步使单层 transformer 性能提升 3.8%。
部分引用自:
- FLASH:https://arxiv.org/pdf/2202.10447.pdf
- FlashAttention:https://arxiv.org/pdf/2205.14135.pdf
- https://zhuanlan.zhihu.com/p/582606847
- https://readpaper.feishu.cn/docx/AC7JdtLrhoKpgxxSRM8cfUounsh
- https://readpaper.feishu.cn/docx/EcZxdsf4uozCoixdU3NcW03snwV
- https://zhuanlan.zhihu.com/p/638468472
- https://blog.csdn.net/LF_AI/article/details/130838524
- https://mp.weixin.qq.com/s/HUSYSrjG65p1TU9lS_KEUA
- https://bytedance.feishu.cn/docs/doccn9w7UdOYcEOD99FjFVpdFzf
10.ByteTransformer: https://bytedance.feishu.cn/docx/XbgDdTb28oVRRKxBdy6cDx1Knbb















 2031
2031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









