






论文链接: https://arxiv.org/pdf/1902.09130.pdf
1.论文任务
VideoLSTM用于动作分类和定位,进行视频中动作的端到端学习。这篇文章的主要贡献是在 Attention LSTM的基础上引入了 conv-lstm,并且Attention是基于motion得出的,文章将这种 conv-lstm +motion-based attention的结构称为 VideoLSTM。
2.论文创新
以attention LSTM为基本架构
- 引入motion特征,提出基于motion的注意力。因为在建模视频时,仅使用深层的卷积是不够的,还必须考虑注意力,motion不仅显示表示动作内容,还可以更好地将注意力引导到相关的时空位置,因此引入了基于motion的注意力。
- 在ALSTM架构中使用卷积。本文认为,得到图像的空间相关性,相比于内积,卷积能够更好地捕获。
- 通过标签和时间注意力来进行动作定位,与其他 LSTM 结构相比,它在动作定位方面具有优势。
3.VideoLSTM模型
以上已经介绍了,模型包括了appearance, motion,attention,具体是用Convolutional ALSTM,Motion-based Attention来改进attention LSTM。此三种结构缺一不可,单独使用不能带来改善。
conv-lstm将传统的lstm的隐藏单元替换为了feature map,并且将hidden到hidden的映射替换成卷积。传统的 fc-lstm网络中,输入到lstm的是具有抽象语义信息的全连接层特征,所以无论是输入到hidden的映射还是hidden到hidden的映射,都会忽略输入图像中的空间信息。而conv-lstm网络是将feature map 输入到lstm中,feature map 中保留着输入的空间结构信息,所以当前的输入会与历史信息中相同的空间区域进行作用,能够描述不同空间区域的局部变化。
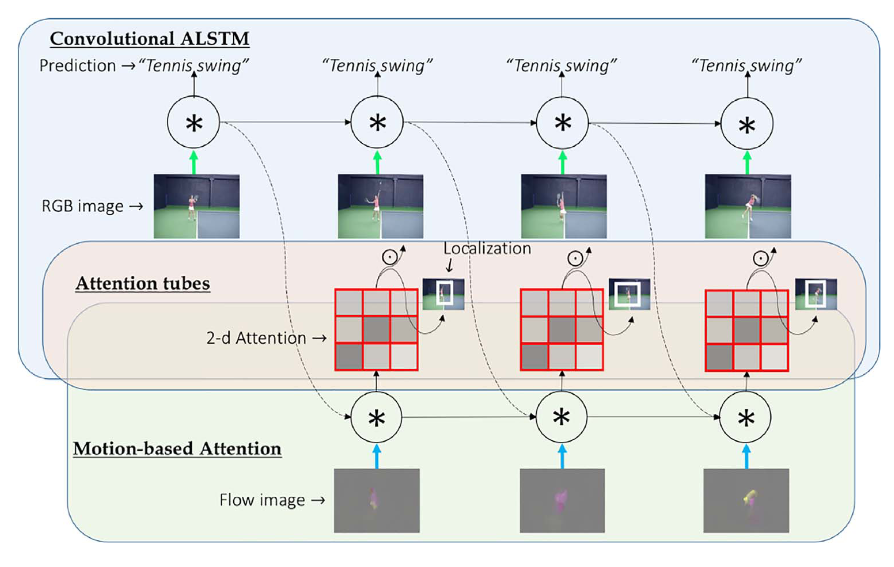
3.1 Convolutional ALSTM
标准的LSTM和ALSTM网络利用全连接,将输入视为序列,这是处理视频(时空数据)的一个主要缺点,因为没有对空间信息进行编码。本文认为,在图像中,首选局部连接,而不是完全连接,就是将LSTM单元中的全连接的乘法运算替换为convolutional运算。
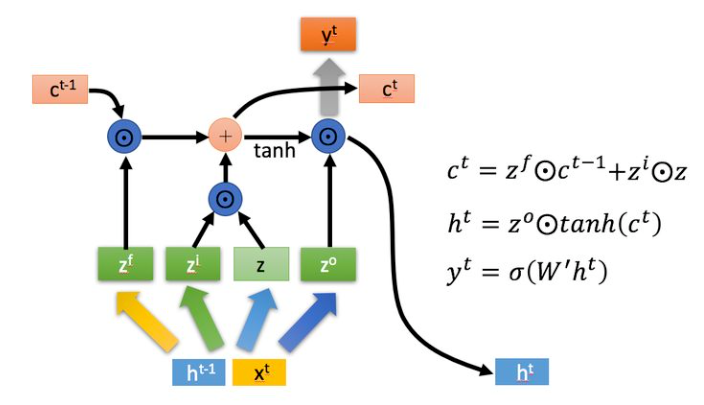
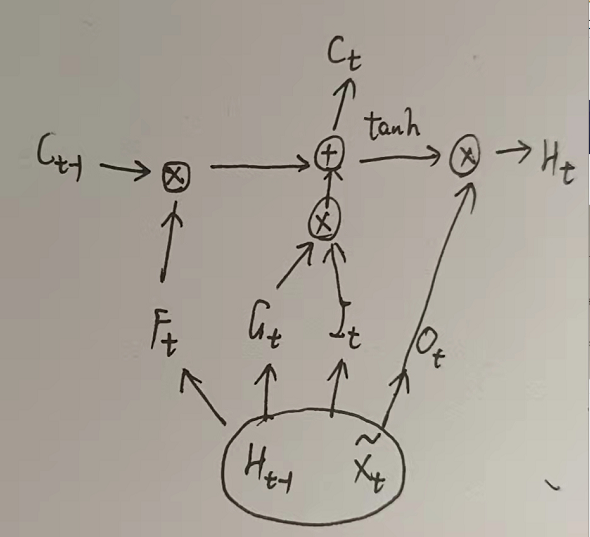
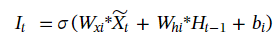
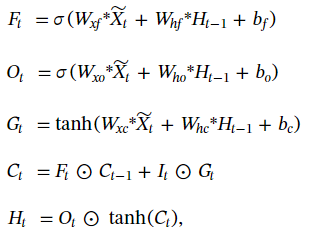
上面的公式根据LSTM得来,但是此处需要注意,*代表卷积操作,
⨀
\bigodot
⨀代表逐点相乘,W是二维卷积核,其他都是三维tensor。
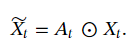
图像特征
X
t
X_t
Xt和每帧t处的attention map相结合,将
X
~
t
\widetilde X_t
X
t作为注意加权图像表示,
X
t
X_t
Xt的shape为
N
∗
N
∗
D
N*N*D
N∗N∗D,attention map的shape为
N
∗
N
N*N
N∗N
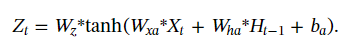
Z
t
Z_t
Zt是一个二维的score map,他的目的是为了产生空间attention map,即
A
t
A_t
At.
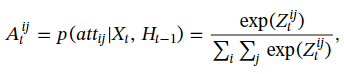

左边是一个ALSTM模型,它根据注意力对输入向量进行加权,并输出一个D维向量。右边是卷积ALSTM网络,它以二维张量输入,执行卷积运算,并返回一个N×N×D维张量,保留视频的空间结构。
3.2 Motion-based attention
在卷积ALSTM网络中,注意力是基于先前ALSTM单元的隐藏状态产生的。但是,视频与显著运动的帧位置高度相关,在ALSTM和卷积ALSTM网络中,使用运动信息来帮助推断注意力是合理的。
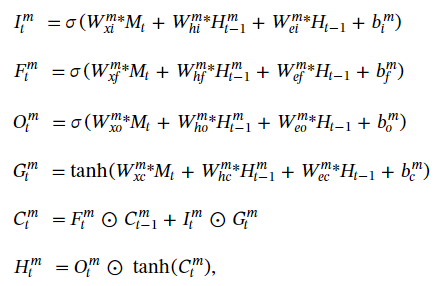
与Convolutional ALSTM相比,将
X
~
t
\widetilde X_t
X
t换成了
M
t
M_t
Mt,并且I,F,O,G都多了一个Ht-1m,
M
t
M_t
Mt是在t时刻从光流中提取的特征图,最后由Htm来生成attention map。
4.实验结果
从输入帧是外观还是光流来比较
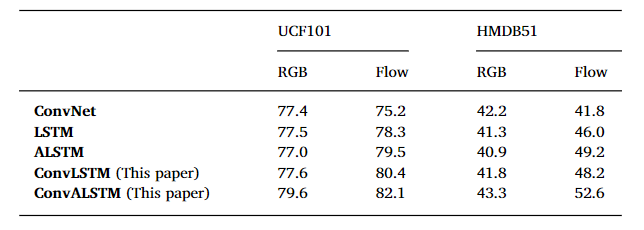
外观流:
- 仅用ConvNet就能得到良好的准确率
- 除了本文的ConvALSTM之外,其他基于LSTM的模型都不能表现出优秀的结果,有的还会使结果更糟糕
光流:
- 基于LSTM结构的模型都表现出了优秀的结果,相较于ConvNet有显著提升
- 在LSTM基础上加入Attention或者Conv都有所提升,两者共同加入结果提升更明显
从注意力方面比较
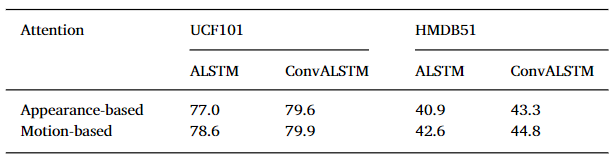
由于使用光流的注意力,会更在意视频中运动明显的部分,准确率相较于使用外观的注意力全部提升。
对跳水动作而言,使用appearance 注意力的模型根据跳水板作出对跳水动作的预测,使用Motion 注意力的模型则根据跳水的人来对跳水作出预测,如下图


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









