






MCIS是ECCV2020的一篇文章,它比较少见地讨论了利用inter-image information去做弱监督语义分割。文章在工作的motivation处指出,当前图像级标签监督下的语义分割大多数都在挖掘intra-image information上面下功夫,主要的研究思路集中在怎样用图像级标签和分类网络去找更多、更好的上下文信息,但却完全忽略了不同照片之间的的信息关联。
如原文图1所示,(a)部分展示了传统分类网络的训练以及产生目标定位图的简单框架,即训练时完全按照标准的分类网络训练方式,推理产生目标定位图时也仅仅根据当前输入的单张图像直接输出。(b)部分展示了MCIS提出的co-attention训练架构,即在训练时成对输入图像,且保证图像对内存在至少一个共同类别;而对某一张图像进行推理产生分割伪标签时,也去随机采出若干张其他的相关图片,以实现协同分割。

原文的图2则展示了MCIS分类网络的详细结构。网络每次接收一对拥有共同类别的图像A和B,co-attention机制通过一种广义的可微分attention机制(普通的spatial-attention加上一个可以学习的权重矩阵)计算A与B的相似度矩阵(注意力加权图),然后以特征聚合的方式用A的特征组合出B的新特征,用B的特征组合出A的新特征,再用新特征去进一步计算CAM和分类向量。从直观上看,通过co-attention计算得到的新特征能够更好地学习并表示出某个类别的共性,因此在训练和推理阶段都能更好地促进分割任务的完成。

原文的式(10)展示了MCIS完整的损失函数表达式:
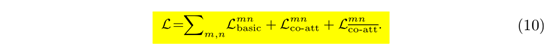
可见,基于co-attention的MCIS共由三部分的损失函数组成,分别代表了基本的分类损失、由co-attention特征计算得到的分类损失以及由contrast co-attention特征计算得到的分类损失。

原文式(2)、式(3)给出了co-attention的affinity matrix P的计算过程。注意到P的计算仅仅在空间注意力的相关计算方法之上增加了一个可学习的线性变换参数矩阵WP。注意P的第一个维度代表图片m的各个像素,第二个维度代表图片n的各个像素,Pij便代表m的第i个像素与n的第j个像素之间的相似程度。因此分别对P进行列归一化和行归一化便可得到对m各个像素的组合系数、对n各个像素的组合系数,之后便是按照attention机制用m的各个像素特征组合出n的新像素特征,用n的像素特征组合出m的新像素特征。如式(4)所示,式(5)进一步给出了co-attention loss的最终表达式。注意![]() 是用
是用![]() 组合得到的特征表示,F
组合得到的特征表示,F![]() 是用
是用![]() 组合得到的特征表示。
组合得到的特征表示。

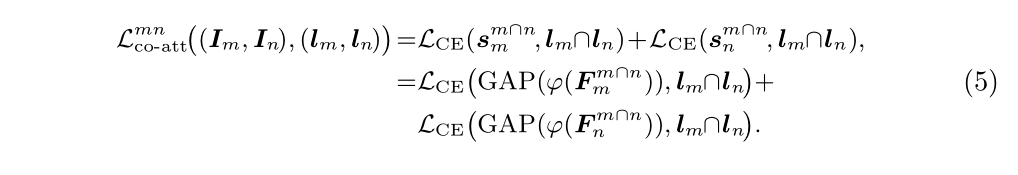
类似地,文中还提出了所谓的contrast co-attention机制,如原文的式(6)、(7)所示。上面提到![]() 和
和![]() 都是通过原有的特征与相似度矩阵加权得到的,那么在两张图片内相似度较大那些区域(同属一个类别的目标区域),区域内会得到较“重”的特征表示,因为它们主要从另一张图片的相似区域以较大的权重值加权而来;而图片不共有的类别目标区域,由于不能从另一张图片找到相似度较大的区域,其内的像素则会得到重量较“轻”的特征表示。如此依赖,便可以通过一个1*1卷积层计算每个特征向量的重量,并用sigmoid函数激活,得到每个特征的相似激活程度,如式(6)所示。
都是通过原有的特征与相似度矩阵加权得到的,那么在两张图片内相似度较大那些区域(同属一个类别的目标区域),区域内会得到较“重”的特征表示,因为它们主要从另一张图片的相似区域以较大的权重值加权而来;而图片不共有的类别目标区域,由于不能从另一张图片找到相似度较大的区域,其内的像素则会得到重量较“轻”的特征表示。如此依赖,便可以通过一个1*1卷积层计算每个特征向量的重量,并用sigmoid函数激活,得到每个特征的相似激活程度,如式(6)所示。


自然而然地,得到了每个特征的相似激活程度,便可用1减去它,得到每个特诊的相似抑制程度![]() 和
和![]() ,点乘原有的特征图得到相似抑制后的特征图,如原文式(8)所示。原文式(9)则进一步展示了contrast co-attention loss的完整表达式。
,点乘原有的特征图得到相似抑制后的特征图,如原文式(8)所示。原文式(9)则进一步展示了contrast co-attention loss的完整表达式。


需要注意的是,co-attention loss只计算图像对共有类别的分类损失,contrast co-attention loss则只计算每张图像独有类别的分类损失,而basic loss按照一般的multi-class sigmoid激活概率进行计算。
对于推理时co-segmentation的细节,如下图所示。文中指出,对一张训练集的图片存在的所有类别![]() ,产生每一个类的CAM时,需要额外采样出N张同样含有该类的图片并得到CAM,把该类的CAM响应值做平均得到最后的响应值(注意只在一个通道上平均)。 因此每一张图片的协同分割实际上需要约KN次CAM的推理才能实现,因此复杂度较高。
,产生每一个类的CAM时,需要额外采样出N张同样含有该类的图片并得到CAM,把该类的CAM响应值做平均得到最后的响应值(注意只在一个通道上平均)。 因此每一张图片的协同分割实际上需要约KN次CAM的推理才能实现,因此复杂度较高。

此外,文中还探讨了co-attention与simple single-class image、noisy web image等extra data结合的可能性。由于extra data与原有数据存在一个较明显的domain gap,作者提出用三个线性变换参数矩阵计算三个不同的P矩阵,即source-source、target-target、source-target三种domain之间的相似度。但这种计算方法显然需要很大的计算量,实际有多work尚待进一步讨论。















 481
481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









