






大家好我是阿道夫!!!
Florence2是一款革命性的AI绘图工具,它将LLM(大型语言模型)的强大功能与AI绘图技术完美结合。本文将介绍Florence2的五大核心功能:提示反推、对象检查、蒙版识别、文字识别及咨询建议,以及如何使用一个模型轻松搞定这些功能,助力您的AI绘图创作。


在LLM大语言模型快速发展下,视觉大模型已成为主流,能够精准的识别图片信息、检查图片对象、提取文字等,甚至可以根据输入图像实现代码编程、咨询建议、物理世界识别等,模拟现实世界物理运动反馈和回应。同时以SD、MJ为首的绘图模型在扩散模型(包括近期 的的DiT架构) 下也得到的快速的发展,模仿垫图一直是绘图过程中重要需求之一。大家常用的提示词反推工具有:ComfyUI-WD14-Tagger,但它并不是非常的精准。今天的主题则是使用微软发布的Florence2视觉大模型集成ComfyUI助力AI绘图。当然它不止提示词反推,还包括:对象检查、蒙版识别、OCR文字识别、文档视觉问题解答等。
Florence-2是一个微软发布的高级视觉基础模型,它采用基于提示的方法来处理广泛的视觉和视觉-语言任务。Florence-2 可以解释简单的文本提示,执行如字幕、目标检测和分割等任务。它利用FLD-5B 数据集训练,包含 5.4 亿个注释跨足 1260 万张图像,以精通多任务学习。该模型的序列到序列架构使其在零样本和微调设置中都表现出色,试验结果证明了Florence-2 是一个具有竞争力的视觉基础模型。
Florence-2具有多版本发布。其中base和base-ft体积小(约400MB)适合低显存用户 ,large和large-fit 体积大(约1G)更精准智能。
Florence-2模型ComfyUI体验
首选ComfyUI中利用插件管理器搜索ComfyUI-Florence2, 并点击安装,此插件无需安装任何模型,在首次运行时会自动下载。重启ComfyUI既可开始体验。
• ComfyUI插件:(需要的同学可以自行扫描获取)

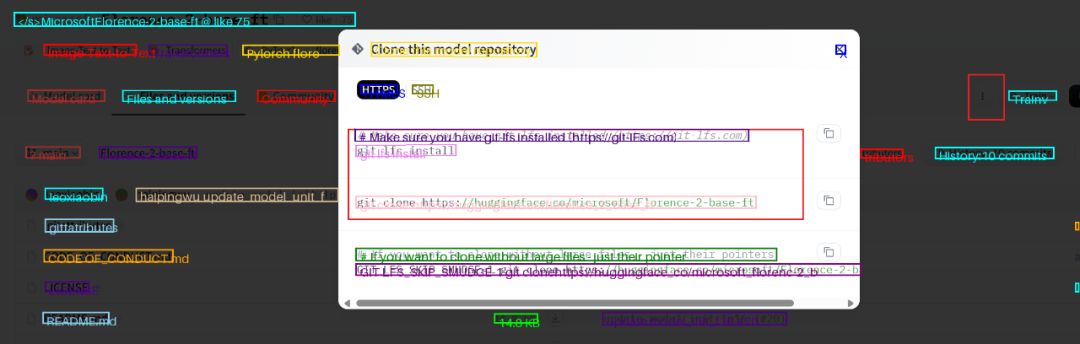
/ComfyUI/models/LLM/Florence-2-base-ft 目录下。如无法自动下载可以使用git lfs clone下载(切记CD到正确目录):
01. 工作流界面
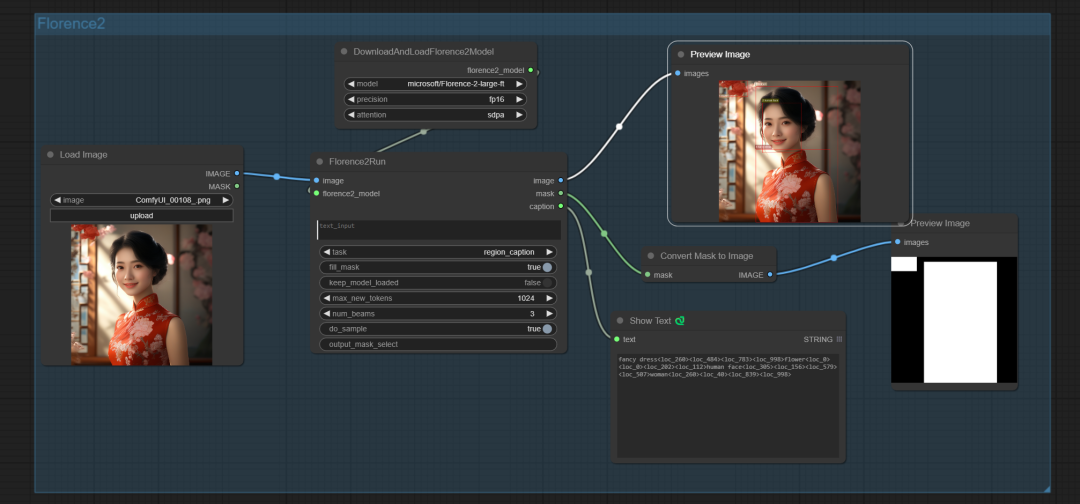
插件中最终的选项是Task任务选项,一共包含11个任务:
-
region_caption:简单的对象检测,识别图像中的基本元素。对象检测标记。
-
dense_region_caption:更详细的对象检测,提供更丰富的描述。
-
region_proposal:纯粹的区域识别,没有语义描述。
-
caption:对图片进行简单描述,反推提示词。
-
detailed_caption:提供更详细的图像描述。
-
more_detailed_caption:进一步增加图像描述的细节。适合适用于图像提示词反推。
-
caption_to_phrase_grounding:将图像描述与短语关联起来。
-
referring_expression_segmentation:根据指示性表达分割图像。图像预期分隔制作蒙版。
-
- Ocr:识别图像中的文本。
-
- ocr_with_region:结合区域信息的文本识别。
-
- docvqa:文档问答咨询。图像识别建议方案。
01. 对象检测
明确的识别出图中:脸、衣服、花、人物。并提供了对象检测位置描述。dense_region_caption包含更详细的描述,region_proposal不包含描述,但具有更多的对象识别。

02.提示词反推
都具有图像描述提示词反推描述,而more_detailed_caption则提示语更详细,识别绘图提示词反推,替代ComfyUI-WD14-Tagger。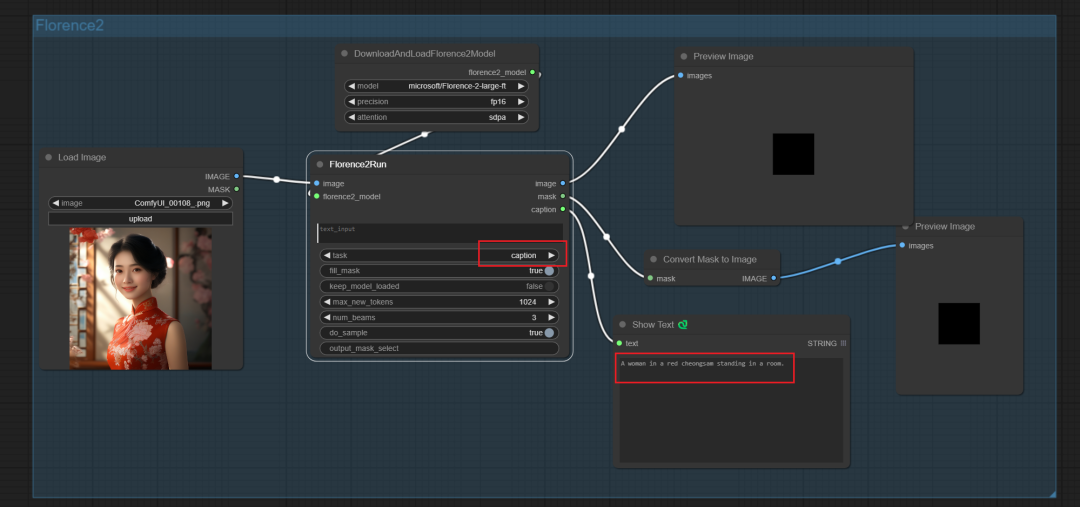 caption:
caption:
A woman in a red cheongsam standing in a room.
detailed_caption:
In this image we can see a woman. In the background there is a wall.
more_detailed_caption:
A woman is wearing a red dress with white flowers on it. The woman has dark brown hair and is smiling. There is a mirror behind the woman.
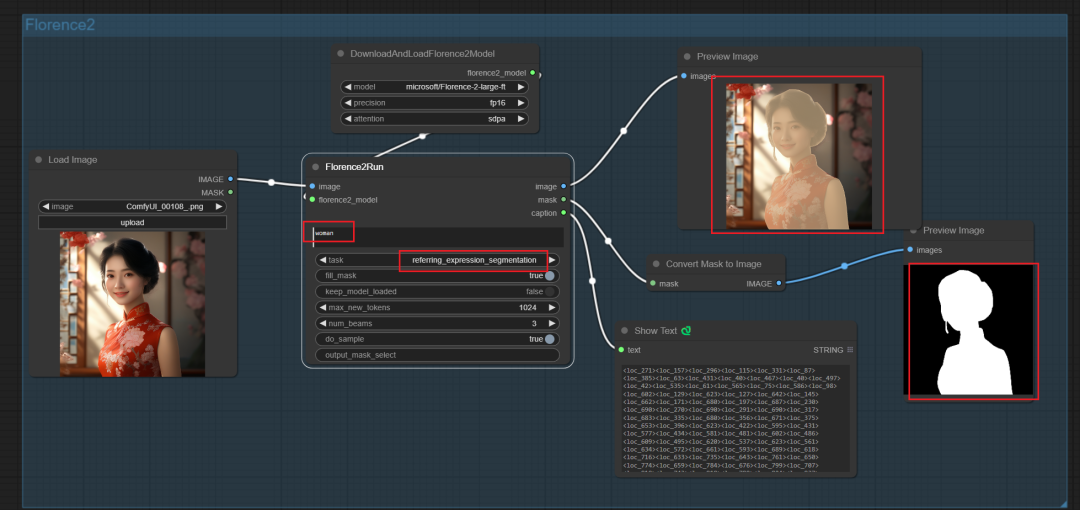
03. 语义分隔,蒙版制作
caption_to_phrase_grounding仅标记语义识别圈选对象,标记区域。caption_to_phrase_grounding则会圈选并生成蒙版。

04. 文字识别
Ocr仅识别了文字,ocr_with_region还输出了图像区域标记。不支持中文,应该缺少中文数据的微调。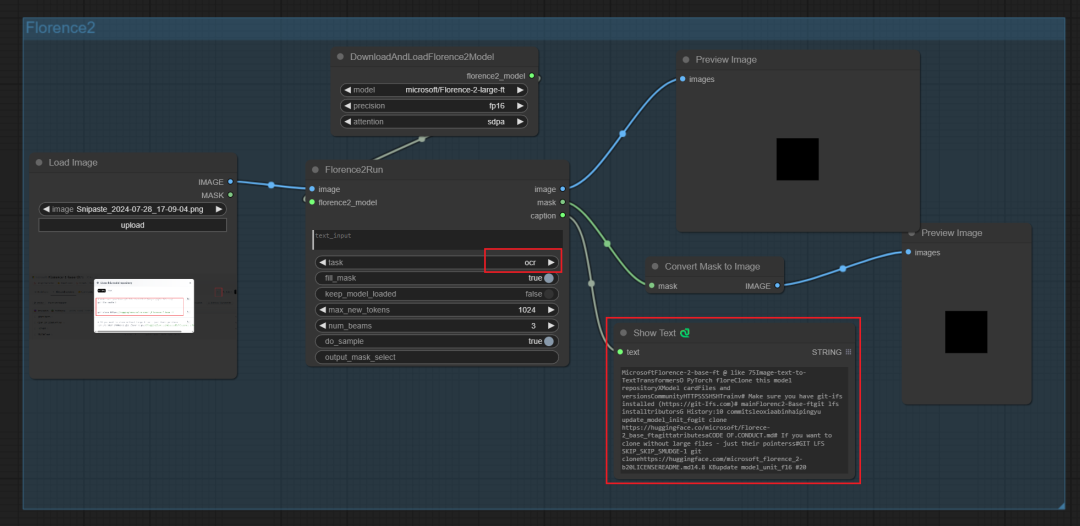
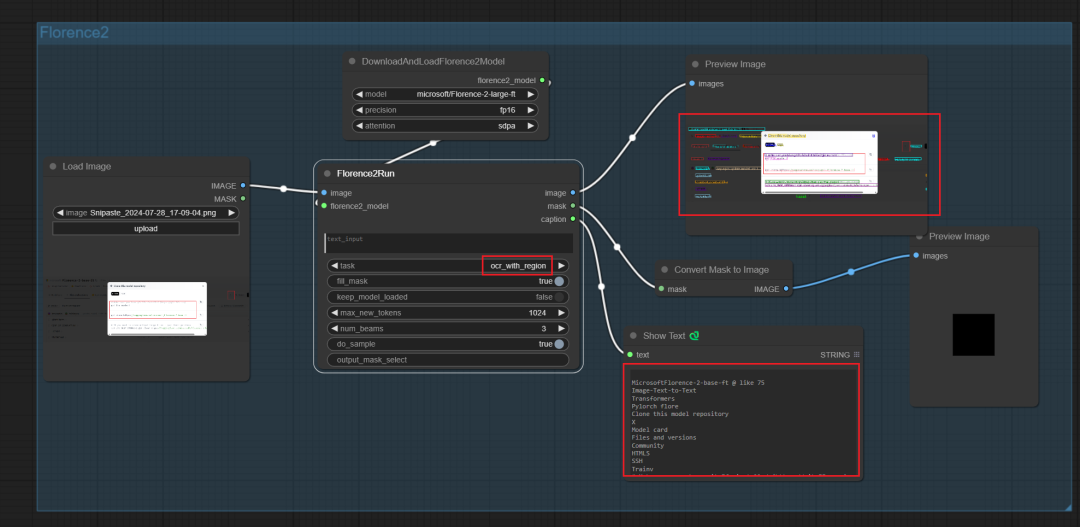
05. 文档咨询
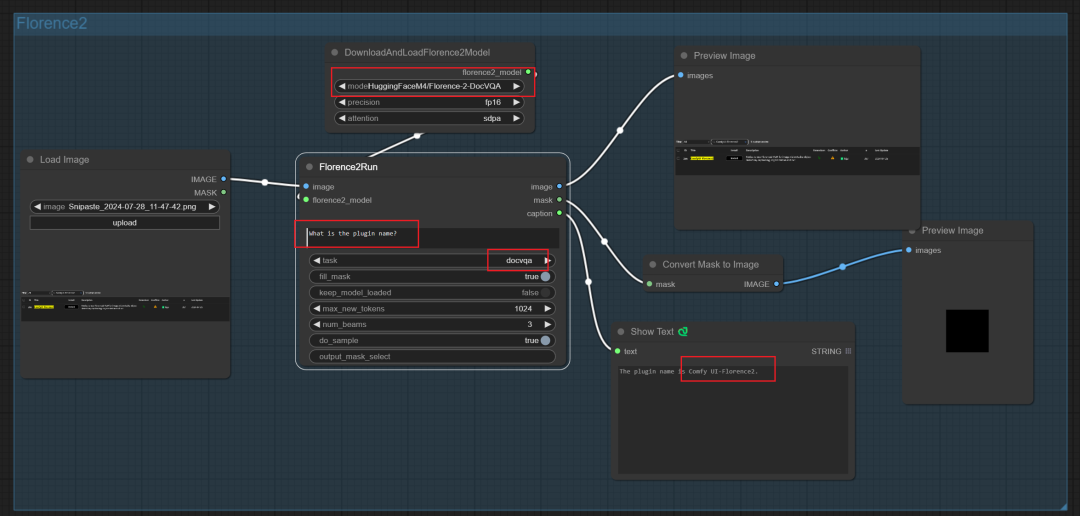
注意切换模型Florence-2-DocVQA。这属于小模型,当前识别能力还很弱,无法与GPT4O等视觉大模型类比。
Florence-2模型提示词反推实战
本文涉及模型下载地址:(可自行扫描获取)

• 麻袋realistic_XL
• 东方审美 | BRairt.SDXLLORA
• 真实皮肤
• HandFineTuning_XL-修手LORA
绘图负向提示词:
(nsfw:1.5),(worst quality, low quality:2),(Watermark:1.5),(NSFW:2),ng_deepnegative_v1_75t,EasyNegative,badhandv4,NSFW,(nsfw:1.3),render,childlike,text,signature,(worst quality, low quality, very displeasing, lowres),(interlocked fingers, badly drawn hands and fingers, anatomically incorrect hands),blurry,watermark,
01. 工作流界面
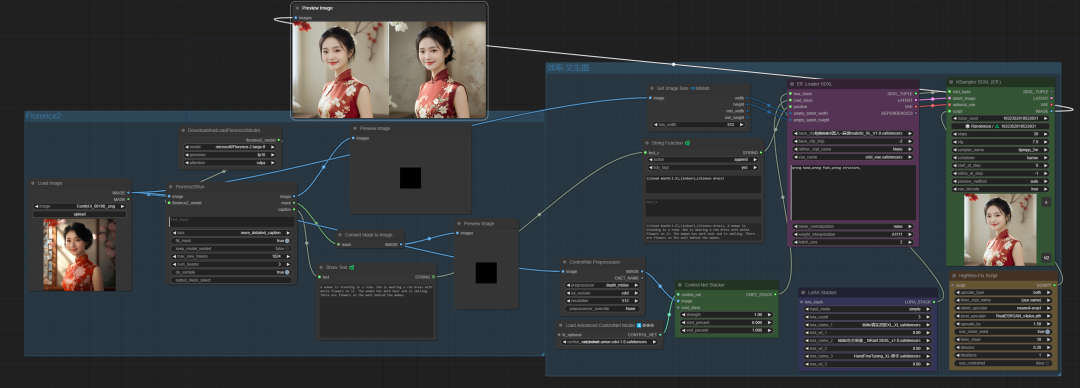
01. 提示词反推实战
反推提示词:
(closed mouth:1.5),(indoor),(chinese dress), A woman is standing in a room. She is wearing a red dress with white flowers on it. The woman has dark hair and is smiling. There are flowers on the wall behind the woman.
输入效果:

这里并未使用相同的模型绘图,因此仍存在模型的差异性。选择相似的模型将会更好的解决仿图。
资料软件免费放送
次日同一发放请耐心等待
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
需要的可以扫描下方CSDN官方认证二维码免费领取【保证100%免费】

**一、AIGC所有方向的学习路线**
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 340
340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









