







Attention Is All You Need
视频链接:
https://www.bilibili.com/video/BV1pu411o7BE?spm_id_from=333.999.0.0
github网址:
https://github.com/tensorflow/tensor2tensor
一、摘要
这篇文章提出了一个新的简单的架构,模型的名称叫做transformer。这个模型仅仅依赖于注意力机制,没有用之前的循环或者是卷积,(所提出的模型,和之前大家所了解的表现较好的模型长得不一样),该模型的并行度更好,训练的时间更少。该transformer架构能够很好的泛化到一些别的任务上。
二、论文结论部分
1、在论文的结论部分说明了,Transformer是第一个做序列转录的模型,仅仅使用注意力,把之前所有的循环程全部换成了multi-headed self-attention(该文章主要是提出了这样一个层)。
2、在机器翻译任务上Transformer能够训练的比其他的架构能够快很多,并且实际的效果比较好。
三、导言
1、在时序模型中最常用的是RNN、LSTM、GRU等。两个主流模型是语言模型和编码器和解码器的架构。
2、RNN的特点,
(1)缺点。
在RNN中,对于序列是从左往右一步一步走(对于第t个词会计算一个输出叫做h(t),也叫做他的隐藏状态,h(t)是由h(t-1)和第t个词本身决定的,这样就可以把前面的历史信息放在当下用来计算),所以难以并行。
(2)在这篇文章之前,attention已经被成功用在了编码器和解码器上了,主要是用在怎样把编码器的东西有效的传递给解码器。
3、本文新提出来的Transformer不再使用之前被大家使用的循环神经层,是纯基于注意力机制的。并行度比较高,能够在较短的时间完成更好的结果。
四、相关工作
1、首先讲到怎样使用卷积神经网络来替换循环神经网络,使得减少时序的计算。之后提高工作的问题是使用卷积神经网络对于比较长的序列难以建模。
2、提出的多头注意力机制(multi-headed attention)可以模拟卷积神经网络多输出通道的一个效果。
3、提到的自注意力机制,Transformer是第一个只依赖于自注意力来做编码器和解码器架构的模型。
五、模型架构
1、对于编码器而言(一次性可以看清整个内容),编码器会将(x1…xn)表示为(z1…zn),zt表示的是第t个词的 一个向量表示。将一些原始的输入变成机器学习可以理解的一系列的向量。
2、对于解码器而言(只能一个一个生成,自回归,你的输入又是你的输出),会拿到编码器的输出,之后会生成一个长为m的一个序列。
3、Transformer是使用了一个编码器和解码器的架构,将一些自注意力、point-wise、fully connected layers。
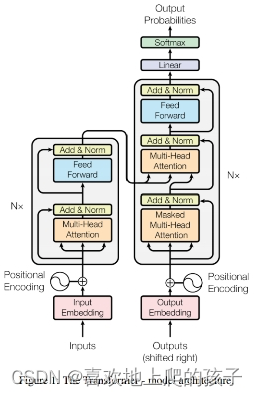
4、在编码器这里使用到了N=6的六个完全一样的层,每个layer里面包含两个sub-layer(子层),第一个sub-layer叫做multi-head self-attention,第二个sub-layer叫做simple,position-wise fully connected feed-forword network(其实就是MLP),每一个子层用了一个残差连接,最后使用一个叫做layer normalization。
公式:LayerNorm(x+Sublayer(x))(因为是残差链接故把输入和输出加在一起)
每一个层的输出维度为512,
5、在解码器这里使用到了N=6的六个完全一样的层构成的,每个层里面也是有两个一样的子层,但是不一样的在于多一个第三个子层,(会用到自回归),保证你在t时间的时候是不会看到t时间以后的那些输入,从而保证训练和预测的时候的行为的一致。
6、注意力函数是将一个query和一些key-value对映射成一个输出的一个函数,这里的所有的query、key-value、output都是一些向量,具体来说output是value的一个加权和,确保输出的维度和value的维度是一样的。对每一个value的权重是这个value对应的key和query的相似度算来的。(不同的注意力机制有不同的算法)
公式:
 7、在Transformer中怎样使用注意力机制
7、在Transformer中怎样使用注意力机制
(1)自注意力机制中key、value、query其实使是同一个东西,输入和输出的大小其实也是一个东西。
(2)设置masked,在进行t时刻计算的时候不会考虑t以后的数据。
(3)编码器的输出key和value以及解码器的下一层输出作为query进来。
六、实验
以翻译为例进行的。
















 2126
2126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











