







环境
GPU:NVIDIA GeForce RTX 3090
内存:128GB
模型下载
https://modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct/files
显存比较大可以下载deepseek-70B:https://www.modelscope.cn/models/mlx-community/DeepSeek-R1-Distill-Llama-70B-4bit/files
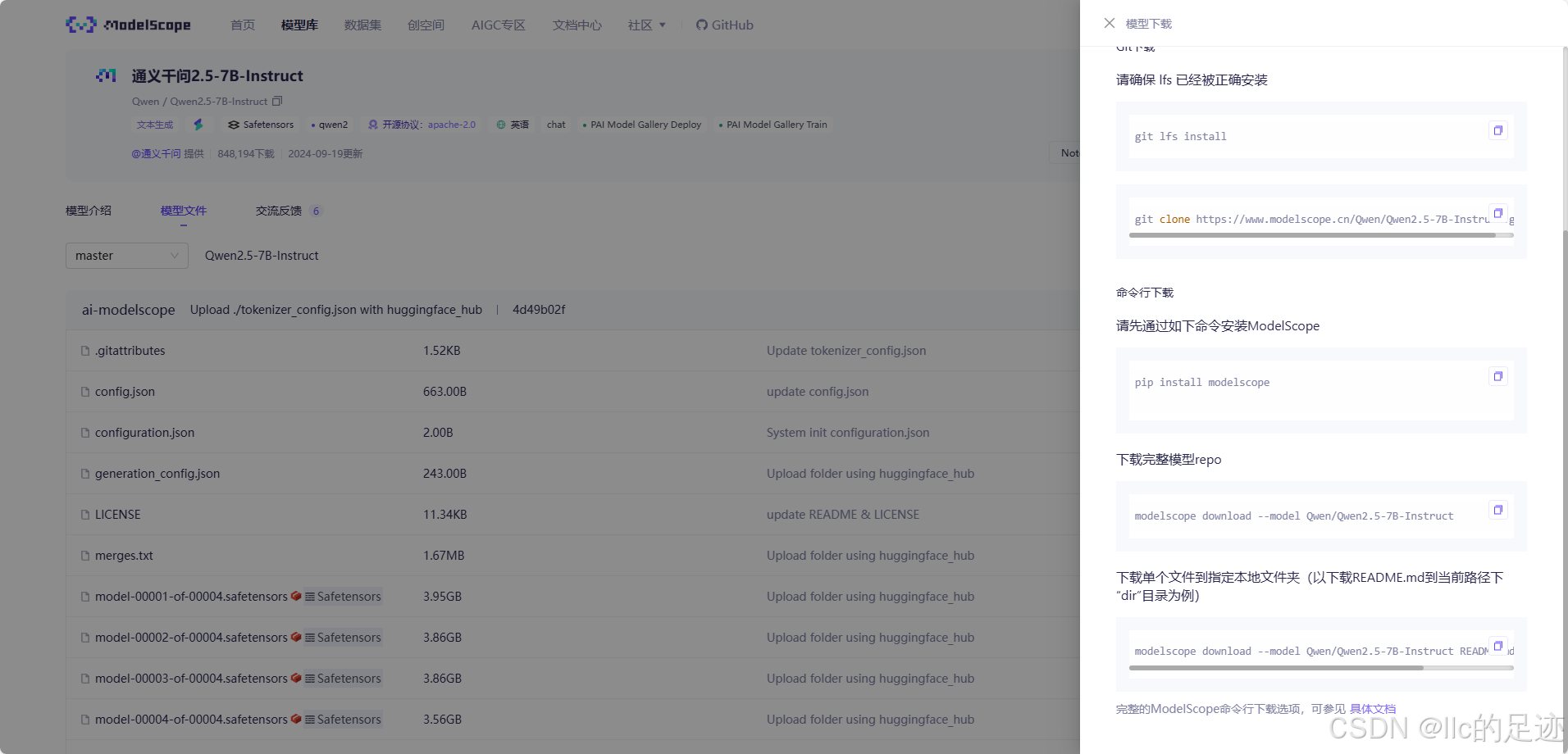
我这里采用命令行下载方式:
pip install modelscope
modelscope download --model Qwen/Qwen2.5-7B-Instruct
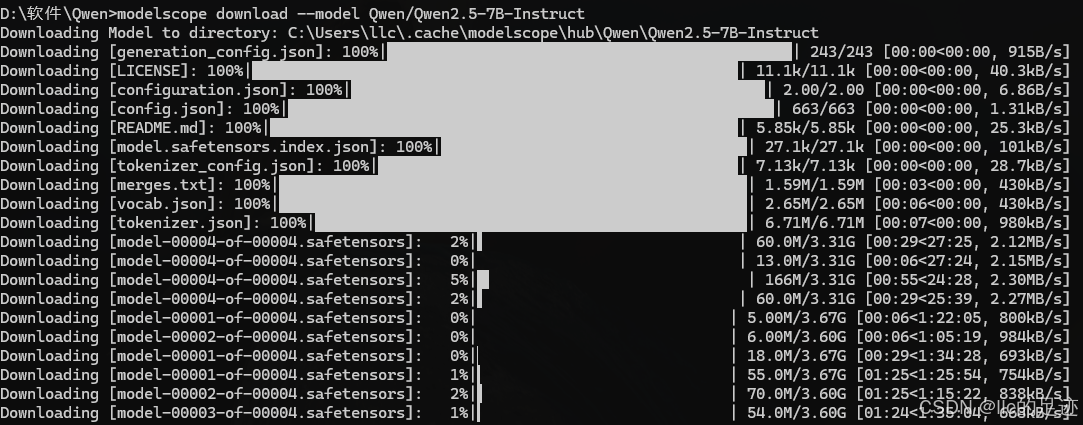
等待下载完成
docker-compose部署
version: "3"
services:
vllm:
container_name: qwen
restart: always
image: vllm/vllm-openai:v0.6.6
environment:
- NVIDIA_VISIBLE_DEVICES=all
volumes:
- ./Qwen2___5-7B-Instruct:/models
command: ["--model", "/models","--served-model-name", "qwen2.5-7b-instruct", "--gpu-memory-utilization", "0.90"]
ports:
- 2025:8000
API 调用
import openai
client = openai.OpenAI(
base_url='http://192.168.2.25:2025/v1',
api_key='NOT_NEED'
)
text = """I have an apple."""
prompt = f"""请帮我翻译:
{text}"""
predict_ret = client.chat.completions.create(
# 此处名称要和vllm中的served-model-name一致
model='qwen2.5-7b-instruct',
messages=[
{'role': 'user', 'content': prompt}
]
)
print(
predict_ret.choices[0].message.content
)


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











