







【大模型】 端侧大模型 Qwen/Qwen2.5-1.5B-Instruct
Qwen2.5-1.5B-Instruct 模型介绍
就 Qwen2.5 语言模型而言,所有模型都在我们最新的大规模数据集上进行了预训练,该数据集包含多达 18T tokens。相较于 Qwen2,Qwen2.5 获得了显著更多的知识(MMLU:85+),并在编程能力(HumanEval 85+)和数学能力(MATH 80+)方面有了大幅提升。此外,新模型在指令执行、生成长文本(超过 8K 标记)、理解结构化数据(例如表格)以及生成结构化输出特别是 JSON 方面取得了显著改进。 Qwen2.5 模型总体上对各种system prompt更具适应性,增强了角色扮演实现和聊天机器人的条件设置功能。与 Qwen2 类似,Qwen2.5 语言模型支持高达 128K tokens,并能生成最多 8K tokens的内容。它们同样保持了对包括中文、英文、法文、西班牙文、葡萄牙文、德文、意大利文、俄文、日文、韩文、越南文、泰文、阿拉伯文等 29 种以上语言的支持。 我们在下表中提供了有关模型的基本信息。
Qwen2.5-1.5B-Instruct 模型特征:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Architecture: transformers with RoPE, SwiGLU, RMSNorm, Attention QKV bias and tied word embeddings
- Number of Parameters: 1.54B
- Number of Paramaters (Non-Embedding): 1.31B
- Number of Layers: 28
- Number of Attention Heads (GQA): 12 for Q and 2 for KV
- Context Length: Full 32,768 tokens and generation 8192 tokens
发布时间
2024年9月份
模型测评
- Qwen2.5-0.5B/1.5B/3B 表现:
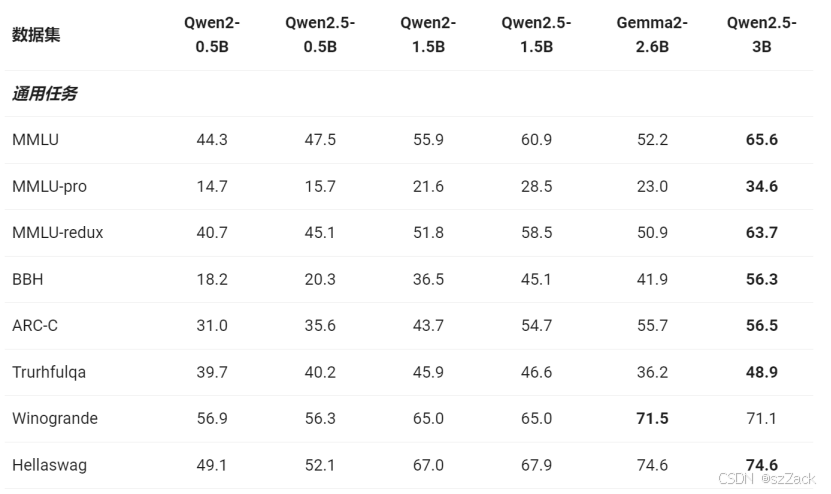
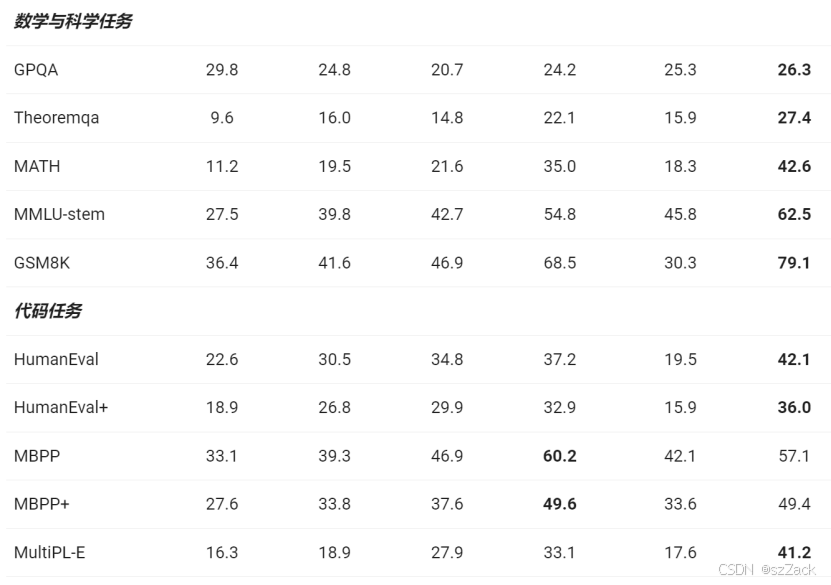
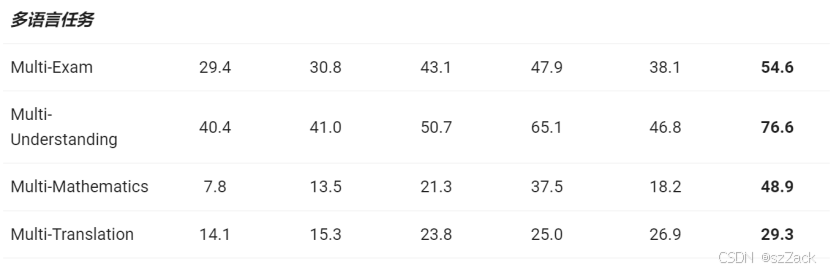
- Qwen2.5-0.5B/1.5B-Instruct 表现:
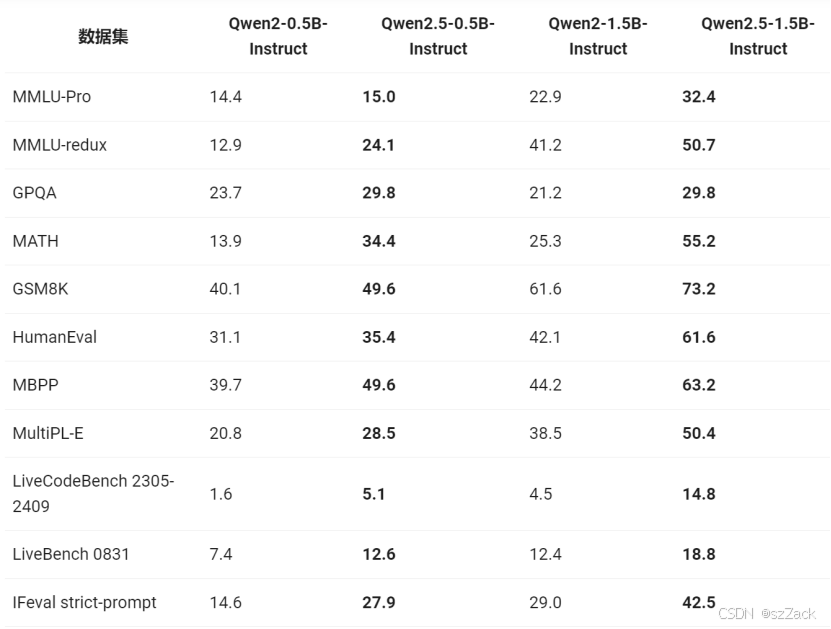
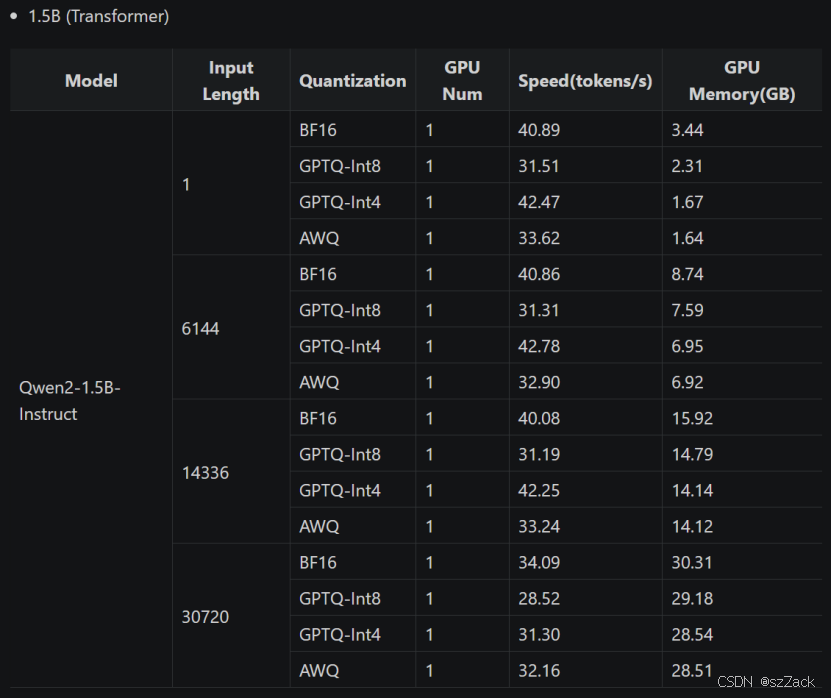
推理性能

运行环境安装
pip install transformers==4.45.2
运行模型
- with transformers:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-1.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
下载
model_id: Qwen/Qwen2.5-1.5B-Instruct
下载地址:https://hf-mirror.com/Qwen/Qwen2-VL-2B-Instruct 不需要翻墙
开源协议
License: apache-2.0



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











