







n-gram实际上是做了一个n-1阶的马尔科夫假设。【用的方法应该是贝叶斯的概率理论】
word2vec是使用神经网络训练的一套概率语言模型。收入的参数是词向量。【这里的词向量应该是属于那种“onehot编码”的词向量吧?】。
神经概率语言模型
对于语料库C里的任意一个词w,将context(w)取为前面n-1个词(类似于n-gram),而且这n-1个词的向量是首位拼接地拼起来成为一个长向量的【规模是(n-1)*m】
现在的二元对(context(w),w)就是一个训练样本了。现在要把这个训练样本“经过”一个神经网络。
词向量在整个神经概率语言模型中发挥了什么作用?
训练时: 帮助构造目标函数的辅助参数
训练完成后: 也好像只是语言模型中的一个副产品【我们的目标是生成语言模型】
word2vec中的两个重要模型:CBOW和skip-gram
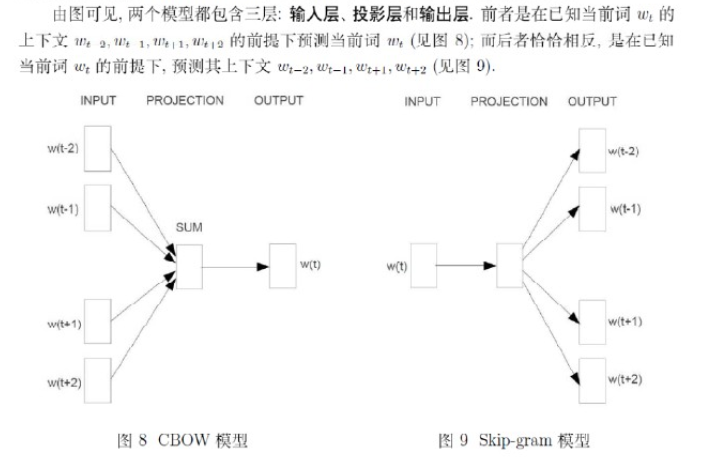
可以看出,CBOW是根据前后文推这个词的,skip-gram是根据这个词推前后文的。
目标函数如下所示:
















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









