







前言
垃圾邮件作为英特网中最具有争议的副产品,对于企业邮箱用户的影响首先就在于给日常办公和邮箱管理者带来额外负担。根据不完全统计,在高效的反垃圾环境下仍然有80%的用户每周需要耗费10分钟左右的时间处理垃圾邮件,而对于中国多数企业邮件应用仍处于低效率反垃圾环境的情况下,这个比例更是呈现数十倍的增长,如图1-1 所示,中国垃圾邮件的总量已经达到全球第三。对于企业邮件服务商而言,垃圾邮件的恶意投送,还会大量占用网络资源,使得邮件服务器85%的系统资源在用于处理垃圾邮件的识别,不仅资源浪费极其严重,甚至可能导致网络阻塞瘫痪,影响企业正常业务邮件的沟通。
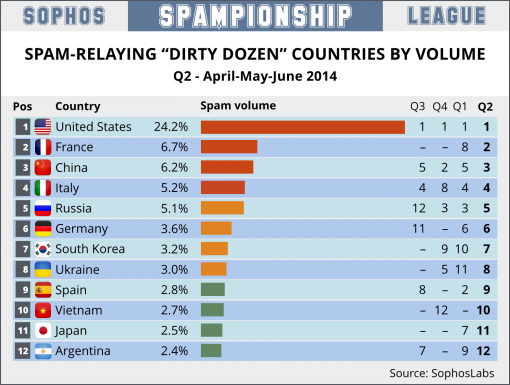
世界垃圾邮件最多国家排行
本文主要以垃圾邮件识别为例,介绍常见的文本处理方法以及常见的文本处理相关的机器学习算法。上半部主要介绍垃圾邮件识别使用的数据集,介绍使用的特征提取方法,包括词袋模型和TF-IDF模型、词汇表模型。本文下半部主要介绍使用的模型以及对应的验证结果,包括朴素贝叶斯、支持向量基和深度学习。
数据集
垃圾邮件识别使用的数据集为Enron-Spam数据集,Enron-Spam数据集是目前在电子邮件相关研究中使用最多的公开数据集,其邮件数据是安然公司(Enron Corporation, 原是世界上最大的综合性天然气和电力公司之一,在北美地区是头号天然气和电力批发销售商)150位高级管理人员的往来邮件。这些邮件在安然公司接受美国联邦能源监管委员会调查时被其公布到网上。
机器学习领域使用Enron-Spam数据集来研究文档分类、词性标注、垃圾邮件识别等,由于Enron-Spam数据集都是真实环境下的真实邮件,非常具有实际意义。
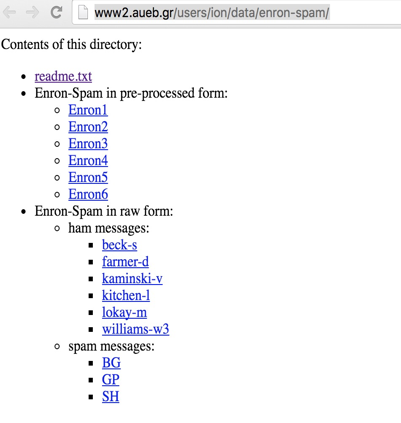
Enron-Spam数据集主页
Enron-Spam数据集合如图所示使用不同文件夹区分正常邮件和垃圾邮件。
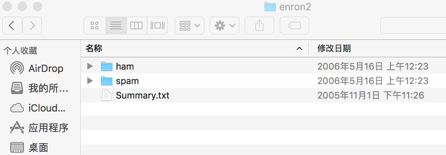
Enron-Spam数据集文件夹结构
正常邮件内容举例如下:
Subject: christmas baskets
the christmas baskets have been ordered .
we have ordered several baskets .
individual earth – sat freeze – notis
smith barney group baskets
rodney keys matt rodgers charlie
notis jon davis move
team
phillip randle chris hyde
harvey
freese
faclities
垃圾邮件内容举例如下:
Subject: fw : this is the solution i mentioned lsc
oo
thank you ,
your email address was obtained from a purchased list ,
reference # 2020 mid = 3300 . if you wish to unsubscribe
from this list , please click here and enter
your name into the remove box . if you have previously unsubscribed
and are still receiving this message , you may email our abuse
control center , or call 1 – 888 – 763 – 2497 , or write us at : nospam ,
6484 coral way , miami , fl , 33155 ” . 2002
web credit inc . all rights reserved .
Enron-Spam数据集对应的网址为:http://www2.aueb.gr/users/ion/data/enron-spam/
特征提取
方法一:词袋模型
文本特征提取有两个非常重要的模型:
词集模型:单词构成的集合,集合中每个元素都只有一个,也即词集中的每个单词都只有一个
词袋模型:如果一个单词在文档中出现不止一次,并统计其出现的次数(频数)
两者本质上的区别,词袋是在词集的基础上增加了频率的纬度,词集只关注有和没有,词袋还要关注有几个。
假设我们要对一篇文章进行特征化,最常见的方式就是词袋。
导入相关的函数库
>>> from sklearn.feature_extraction.text import CountVectorizer
实例化分词对象
>>> vectorizer = CountVectorizer(min_df=1)
>>> vectorizer
CountVectorizer(analyzer=…’word’, binary=False, decode_error=…’strict’,
dtype=<… ‘numpy.int64′>, encoding=…’utf-8′, input=…’content’,
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern=…’(?u)\\b\\w\\w+\\b’,
tokenizer=None, vocabulary=None)
将文本进行词袋处理
>>> corpus = [
... 'This is the first document.',
... 'This is the second second document.',
... 'And the third one.',
... 'Is this the first document?',
... ]
>>> X = vectorizer.fit_transform(corpus)
>>> X
<4×9 sparse matrix of type ‘<… ‘numpy.int64′>’
with 19 stored elements in Compressed Sparse … format>
获取对应的特征名称
>>> vectorizer.get_feature_names() == (
… ['and', 'document', 'first', 'is', 'one',
... 'second', 'the', 'third', 'this'])
True
获取词袋数据,至此我们已经完成了词袋化。但是对于程序中的其他文本,如何可以使用现有的词袋的特征进行向量化呢?
>>> X.toarray()
array([[0, 1, 1, 1, 0, 0, 1, 0, 1],
[0, 1, 0, 1, 0, 2, 1, 0, 1],
[1, 0, 0, 0, 1, 0, 1, 1, 0],
[0, 1, 1, 1, 0, 0, 1, 0, 1]]…)
我们定义词袋的特征空间叫做词汇表vocabulary。
vocabulary=vectorizer.vocabulary_
针对其他文本进行词袋处理时,可以直接使用现有的词汇表。
>>> new_vectorizer = CountVectorizer(min_df=1, vocabulary=vocabulary)
在本例中,将整个邮件包括正文当成一个字符串处理,其中回车和换行需要过滤掉。
def load_one_file(filename):
x=“”
with open(filename) as f:
for line in f:
line=line.strip(‘\n’)
line = line.strip(‘\r’)
x+=line
return x
遍历指定文件夹下全部文件,加载数据。
def load_files_from_dir(rootdir):
x=[]
list = os.listdir(rootdir)
for i in range(0, len(list)):
path = os.path.join(rootdir, list[i])
if os.path.isfile(path):
v=load_one_file(path)
x.append(v)
return x
Enron-Spam数据集的数据分散在6个文件夹Enron1到Enron6,正常文件在ham文件夹下,垃圾邮件在spam文件夹下,依次记载全部数据。
def load_all_files():
ham=[]
spam=[]
for i in range(1,7):
path=”../data/mail/enron%d/ham/” % i
print “Load %s” % path
ham+=load_files_from_dir(path)
path=”../data/mail/enron%d/spam/” % i
print “Load %s” % path
spam+=load_files_from_dir(path)
return ham,spam
使用词袋模型,向量化正常邮件和垃圾邮件样本,其中ham文件夹下的样本标记为0,标记为正常邮件,spam文件夹下的样本标记为1,标记为垃圾邮件。
def get_features_by_wordbag():
ham, spam=load_all_files()
x=ham+spam
y=[0]*len(ham)+[1]*len(spam)
vectorizer = CountVectorizer(
decode_error=’ignore’,
strip_accents=’ascii’,
max_features=max_features,
stop_words=’english’,
max_df=1,
min_df=1 )
print vectorizer
x=vectorizer.fit_transform(x)
x=x.toarray()
return x,y
CountVectorize函数比较重要的几个参数为:
decode_error,处理解码失败的方式,分为‘strict’、‘ignore’、‘replace’三种方式
strip_accents,在预处理步骤中移除重音的方式
max_features,词袋特征个数的最大值
stop_words,判断word结束的方式
max_df,df最大值
min_df,df最小值
binary,默认为False,当与TF-IDF结合使用时需要设置为True
本例中处理的数据集均为英文,所以针对解码失败直接忽略,使用ignore方式,stop_words的方式使用english,strip_accents方式为ascii方式。
方法二:TF-IDF模型
文本处理领域还有一种特征提取方法,叫做TF-IDF模型(term frequency–inverse document frequency,词频与逆向文件频率)。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索应用,作为文件与用户查询之间相关程度的度量或评级。
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF(Term Frequency,词频),词频高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF * IDF。TF表示词条在文档d中出现的频率。IDF(inverse document frequency,逆向文件频率)的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。
在Scikit-Learn中实现了TF-IDF算法,实例化TfidfTransformer即可。
>>> from sklearn.feature_extraction.text import TfidfTransformer
>>> transformer = TfidfTransformer(smooth_idf=False)
>>> transformer
TfidfTransformer(norm=…’l2′, smooth_idf=False, sublinear_tf=False, use_idf=True)
TF-IDF模型通常和词袋模型配合使用,对词袋模型生成的数组进一步处理。
>>> counts = [[3, 0, 1],
… [2, 0, 0],
… [3, 0, 0],
… [4, 0, 0],
… [3, 2, 0],
… [3, 0, 2]]
…
>>> tfidf = transformer.fit_transform(counts)
>>> tfidf
<6×3 sparse matrix of type ‘<… ‘numpy.float64′>’ with 9 stored elements in Compressed Sparse … format>
>>> tfidf.toarray()
array([[ 0.81940995, 0. , 0.57320793],
[ 1. , 0. , 0. ],
[ 1. , 0. , 0. ],
[ 1. , 0. , 0. ],
[ 0.47330339, 0.88089948, 0. ],
[ 0.58149261, 0. , 0.81355169]])
在本例中,获取完ham和spam数据后,使用词袋模型CountVectorizer进行词袋化,其中binary参数需要设置为True,然后再使用TfidfTransformer计算TF-IDF。
def get_features_by_wordbag_tdjfd():
ham, spam=load_all_files()
x=ham+spam
y=[0]*len(ham)+[1]*len(spam)
vectorizer = CountVectorizer(binary=True,
decode_error=’ignore’,
strip_accents=’ascii’,
max_features=max_features,
stop_words=’english’,
max_df=1.0,
min_df=1 )
x=vectorizer.fit_transform(x)
x=x.toarray()
transformer = TfidfTransformer(smooth_idf=False)
tfidf = transformer.fit_transform(x)
x = tfidf.toarray()
return x,y
方法三:词汇表模型
词袋模型可以很好的表现文本由哪些单词组成,但是却无法表达出单词之间的前后关系,于是人们借鉴了词袋模型的思想,使用生成的词汇表对原有句子按照单词逐个进行编码。TensorFlow默认支持了这种模型。
tf.contrib.learn.preprocessing.VocabularyProcessor (max_document_length, min_frequency=0,
vocabulary=None,
tokenizer_fn=None)
其中各个参数的含义为:
max_document_length:,文档的最大长度。如果文本的长度大于最大长度,那么它会被剪切,反之则用0填充
min_frequency,词频的最小值,出现次数小于最小词频则不会被收录到词表中
vocabulary,CategoricalVocabulary 对象
tokenizer_fn,分词函数
假设有如下句子需要处理:
x_text =[
'i love you',
'me too'
]
基于以上句子生成词汇表,并对’i me too’这句话进行编码。
vocab_processor = learn.preprocessing.VocabularyProcessor(max_document_length)
vocab_processor.fit(x_text)
print next(vocab_processor.transform(['i me too'])).tolist()
x = np.array(list(vocab_processor.fit_transform(x_text)))
print x
运行结果为:
本文主要以垃圾邮件识别为例,介绍常见的文本处理方法以及常见的文本处理相关的机器学习算法。上半部主要介绍垃圾邮件识别使用的数据集,介绍使用的特征提取方法,包括词袋模型和TF-IDF模型、词汇表模型。[1, 4, 5, 0]
[[1 2 3 0]
[4 5 0 0]]
整个过程如图 所示。
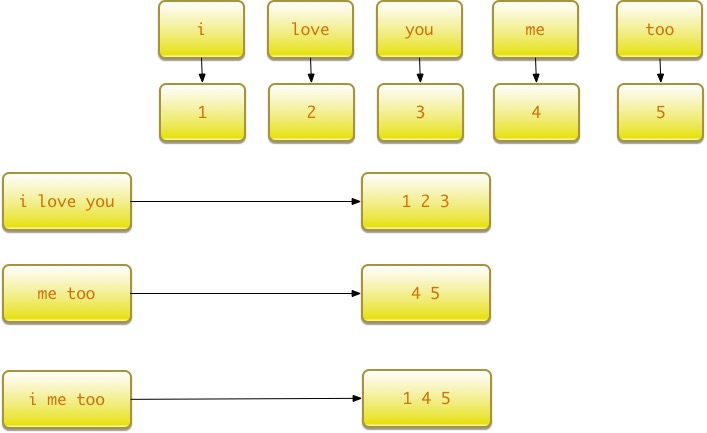
使用词汇表模型进行编码
在本例中,获取完ham和spam数据后,通过VocabularyProcessor函数对数据集进行处理,获取词汇表,并按照定义的最大文本长度进行截断处理,没有达到最大文本长度的使用0填充。
global max_document_length
x=[]
y=[]
ham, spam=load_all_files()
x=ham+spam
y=[0]*len(ham)+[1]*len(spam)
vp=tflearn.data_utils.VocabularyProcessor(max_document_length=max_document_length,
min_frequency=0,
vocabulary=None,
tokenizer_fn=None)
x=vp.fit_transform(x, unused_y=None)
x=np.array(list(x))
return x,y
小结
本文主要以垃圾邮件识别为例,介绍常见的文本处理方法以及常见的文本处理相关的机器学习算法。上半部主要介绍垃圾邮件识别使用的数据集,介绍使用的特征提取方法,包括词袋模型和TF-IDF模型、词汇表模型。想知道如何使用朴素贝叶斯、支持向量基以及深度学习的DNN、RNN、CNN识别垃圾邮件,请看下部。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









