






需求:
关注博主(300-1000名)在更新视频时,一分钟之内收到通知,并自动下载发布的视频
大家知道APP虽然上重点关注博主,但名额只有几名,远达不到批量(300+)关注的通知,要实现批量实时监控,只有获得关注列表,去轮询。
实现逻辑:
一,web页面登录获取自已的账户,同时保存cookie,secUid和uid以及关注博主数量(信息隐藏在js中)
二,判断是否首次运行:
A:首次运行:保存关注列表到本地,(secUid和uid和作品数)
B:非首次运行:对比关注博主数:不同时加入新关注数量(每次轮询都会运行,在程序运行时,新关注的博主也会加入监控)
三,开始轮询
1,对比作品数,若:
1a:减少(博主删除了作品),则更新本地作品数
2a:增加 (发布了新品作品),则去主页校验,:
2aa:如果发布作品大于当时间,且主页列表没有新增作品,则为定时发布作务,将其时间发布记录,到点通知下载,同时更新本地记录:
2ab:发现新作品:
a,校验过滤:是否视频,竖屏,时长等,符合则:通知,下载,更新本地记录)
b,不符合更新本地作品数记录
第一步 获取用户信息 secUid和uid和作品数实现如下:
import datetime
import json
import os
import random
import re
import time
import webbrowser
from time import sleep
from urllib import parse
from loguru import logger
from configobj import ConfigObj
import execjs
import requests
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from win10toast import ToastNotifier
requests.packages.urllib3.disable_warnings()
from selenium import webdriver
from bs4 import BeautifulSoup
# import Util
# 指定浏览器打开网页
firefoxPath = r"C:\Program Files\Mozilla Firefox\firefox.exe"
webbrowser.register('firefox', None, webbrowser.BackgroundBrowser(firefoxPath))
# 浏览器设置
option = webdriver.ChromeOptions()
# 以最高权限运行
option.add_argument('--no-sandbox')
# 开发者模式的开关,设置一下,打开浏览器就不会识别为自动化测试工具了
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('--ignore-certificate-errors')
option.add_argument('--ignore-ssl-errors')
# # 指定缓存位置
# option.add_argument(r'--disk-cache-dir=G:\python项目\凌风抖音监控还原\cache')
# option.add_argument(r'--user-data-dir=G:\python项目\凌风抖音监控还原\cache')
# 处理SSL证书错误问题
option.add_argument('--ignore-certificate-errors')
option.add_argument('--ignore-ssl-errors')
# 忽略无用的日志
option.add_experimental_option("excludeSwitches", ['enable-automation', 'enable-logging'])
option.add_argument('--no-sandbox') # 给予root执行权限
s = Service('chromedriver.exe')
tplt = "{0:{3}^22}\t{1:^8}\t{2:^8}"
today = str(datetime.date.today())
video_save_lv = f"D:\\监控视频下载\\{today}"
if not os.path.exists(video_save_lv):
os.mkdir(video_save_lv)
def get_secUid():
"""
登录获取UID
:return:
"""
global headers
browser = webdriver.Chrome(service=s, options=option)
url = 'https://www.douyin.com/user/self'
# cookie 登录
if os.path.exists("cookies.txt"):
# 从9828_cookies.txt文件读取cookies
with open("cookies.txt") as f2:
cookies = json.loads(f2.read())
# 使用cookies登录
browser.get(url)
for cook in cookies:
browser.add_cookie(cook)
# 刷新页面
browser.refresh()
while True:
sleep(5)
if "用户名" in browser.title:
break
else:
browser.get(url)
user_input = input("登录:")
# 获取cookie
cookies = browser.get_cookies()
print(cookies)
with open("cookies.txt", "w") as f:
f.write(json.dumps(cookies))
# 存储header供requests使用
headers = {'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/116.0"}
cookies = browser.get_cookies()
cookie_string = ''
for cookie in cookies:
cookie_string = cookie_string + cookie['name'] + '=' + cookie['value'] + ';'
headers['cookie'] = cookie_string
headers['referer'] = "https://www.xxx.com/user/self?showTab=record"
headers['TE'] = "trailers"
headers['Sec-Fetch-Dest'] = "empty"
headers['Sec-Fetch-Mode'] = "cors"
headers['Sec-Fetch-Site'] = "same-origin"
headers['Host'] = "www.douyin.com"
# 获取 secUid, uid, 关注数量
res = re.findall('<script id="RENDER_DATA" type="application/json">(.*?)</script>', browser.page_source)[0]
res = requests.utils.unquote(res)
secUid = json.loads(res)['app']['user']['info']['secUid']
uid = str(json.loads(res)['app']['user']['info']['uid'])
followingCount = json.loads(res)['app']['user']['info']['followingCount']
logger.info(f"secUid:{secUid}, uid: {uid} 关注博主:{followingCount}")
# print(secUid)
browser.quit()
return (secUid, followingCount, uid, headers)第二步 开始轮询:
def check_index(url_list):
"""
开始检查的作品数的主程序
:param url_list: 用户作品列表数
:return:
"""
count = 1 # 计数开始
while True:
start_time = datetime.datetime.now() # 计时开始
# 打开本地json文件读取上次检查信息
if get_all_following_list(url_list):
count += 1
sleep(random.randint(5, 10))
end_time = datetime.datetime.now() # 计时结束
# 处理输出时间格式
count_time = str(end_time - start_time)
count_time = count_time.split(":", 1)[-1]
count_time = count_time.split(".", 1)[0]
# count_time = round(count_time, 2)
logger.info(f"【{count}】轮监控中,耗时: 【{count_time}】 {str(datetime.datetime.now().time())[:8]}\n")
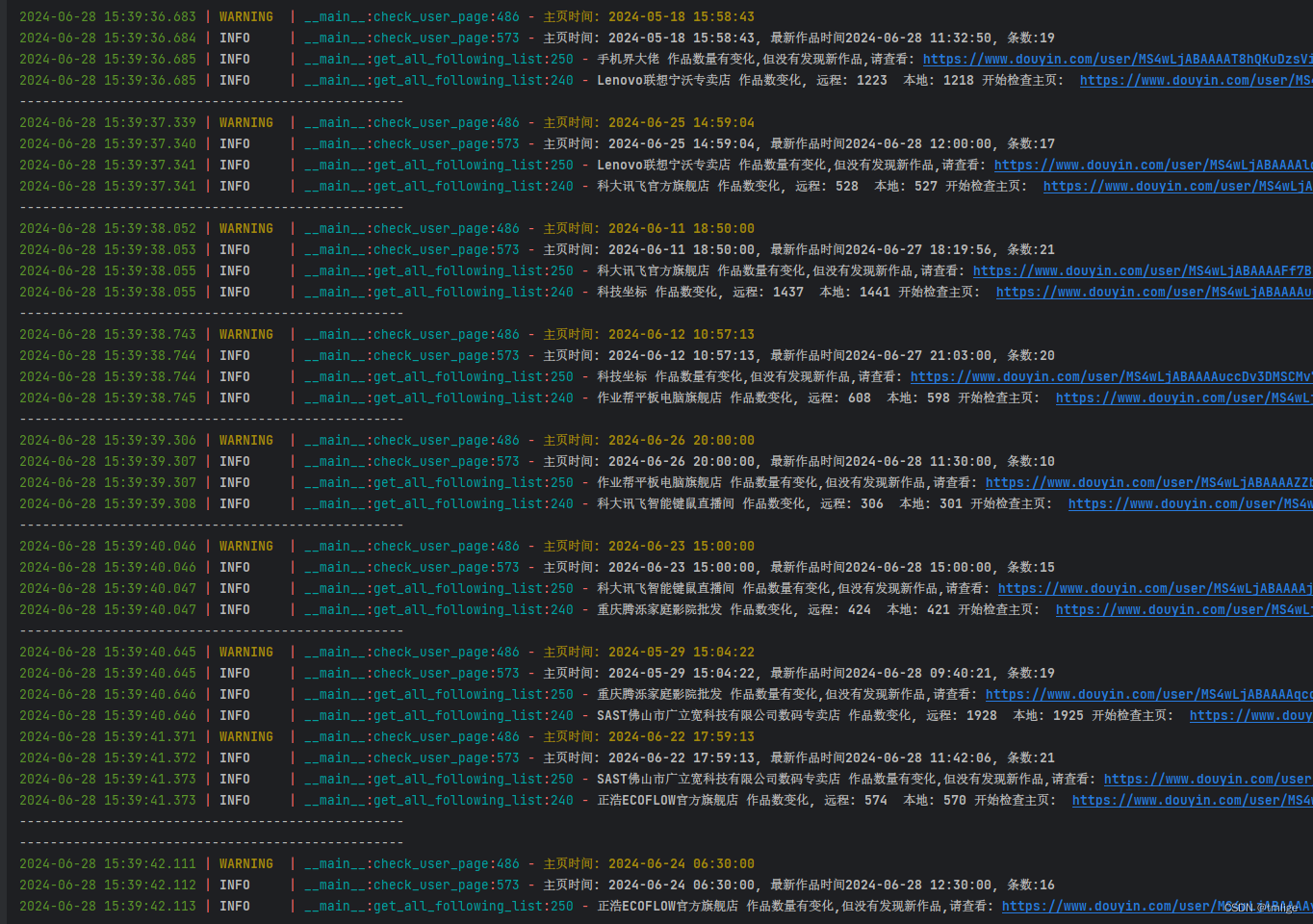
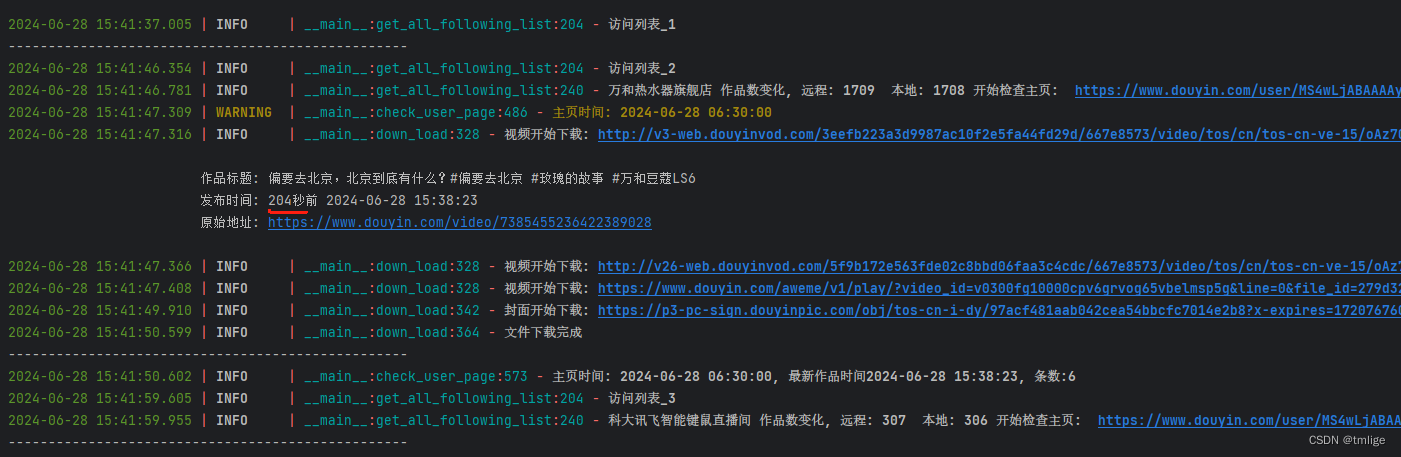
print("-"*50)实现效果如下:


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











