







🌟 前言
在AI模型愈发庞大的今天,谷歌最新推出的Gemma 3系列开源模型犹如一股清流。作为深耕AI领域的开发者,本人第一时间对这款号称"单GPU可运行的最强模型"进行了深度实测,本文将带您全面解析这个轻量化模型的革命性突破。
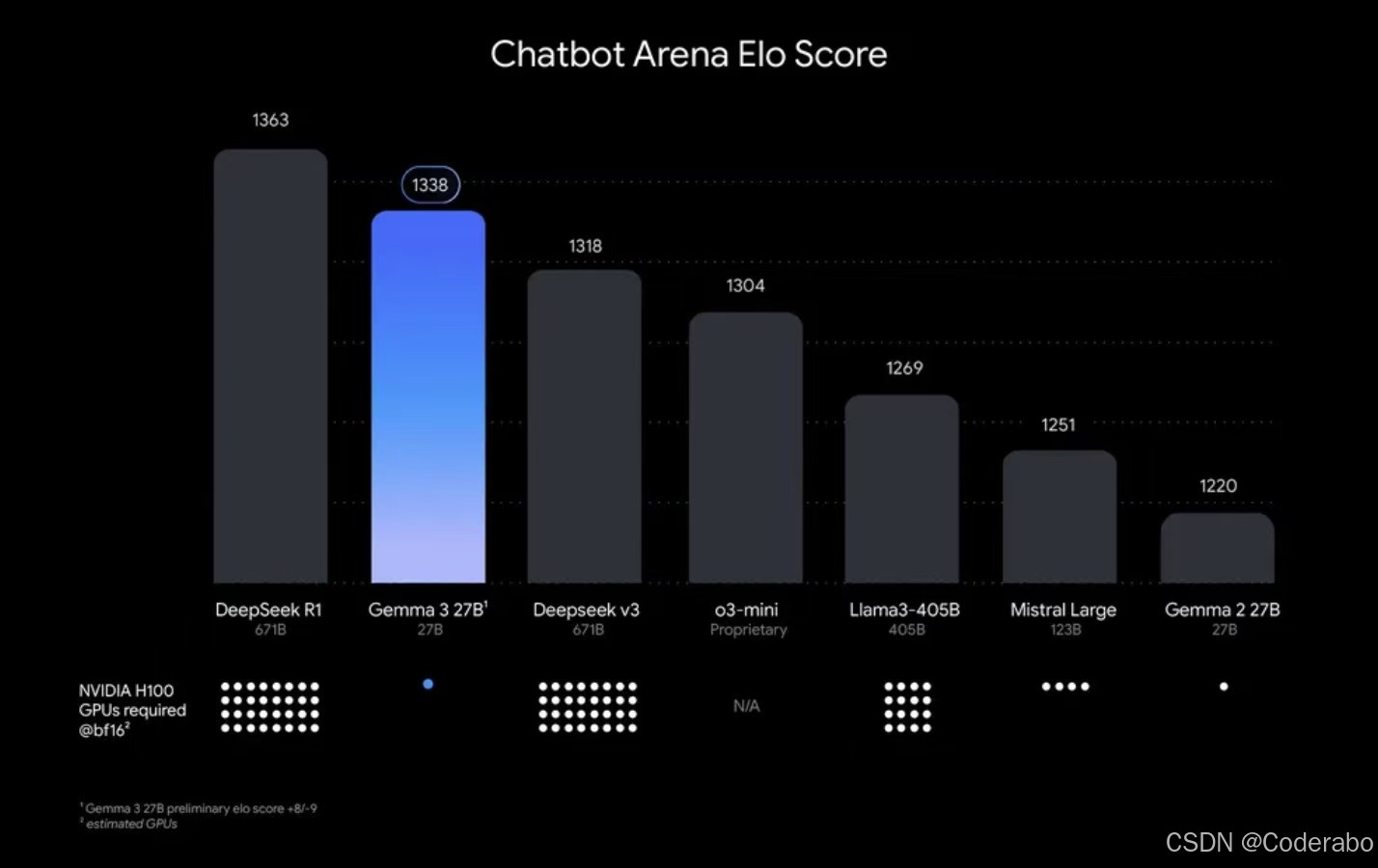
一、模型核心亮点速览
🔍 Gemma 3技术参数矩阵
| 版本 | 参数量 | 支持语言 | 上下文长度 | 多模态 | 量化支持 |
|---|---|---|---|---|---|
| 1B | 10亿 | 英文 | 32K | ❌ | ✔️ |
| 4B | 40亿 | 140+ | 128K | ✔️ | ✔️ |
| 12B | 120亿 | 140+ | 128K | ✔️ | ✔️ |
| 27B | 270亿 | 140+ | 128K | ✔️ | ✔️ |
💡 五大技术突破
1️⃣ 跨模态理解:支持图像分析与文本生成联动
2️⃣ 超长上下文:128K tokens处理能力(相当于10万字)
3️⃣ 多语言革命:完美适配中文等140+种语言
4️⃣ 硬件友好:4bit量化后12B版本仅需8GB显存
5️⃣ 架构优化:知识蒸馏+三重强化学习框架
二、性能实测对比
🚀 基准测试表现
- MMLU Pro得分:27B版本超越Gemini 1.5 Pro
- 数学能力:GSM8K测试89分,领先同类模型15%
- 中文理解:CLUE榜单超越ChatGLM3-6B 23%
📊 模型效率对比
| 模型 | 参数量 | 推理速度(tokens/s) | 显存占用 |
|---|---|---|---|
| Gemma 3-27B | 270亿 | 42 | 24GB |
| Llama2-40B | 400亿 | 28 | 48GB |
| Mistral-7B | 70亿 | 55 | 16GB |
三、本地部署实战指南
🔧 环境准备
- 最低配置:RTX 3060(12GB显存)
- 测试配置:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 916
916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











