







寒假里因为项目需要用到YOLOv3,在网上找了很多linux下的配置教程,很多博主的博客里已经讲得很详细了,我这边重点将说明一下linux下的yolov3的封装,因为要给别人用,不可能提供源码的,都是封装成动态链接库给别人使用,而我在封装的过程中发现网络上的教程尤其是在linux下的封装并没有很详细,我这边在做一个补充说明,希望能帮助更多人少走弯路,也是对自己第一次独立完成这些工作做一个记录。
一、Linux下基于CPU&GPU部署YOLOv3训练和测试自己的数据
1、制作数据集
准备数据图像,我用的是jpg格式的,用labelImg工具进行标注,只要把data文件夹下的predefined_classes.txt改成自己的类别就好了。标注完成每一张图就会生成对应的xml文件。
](https://img-blog.csdnimg.cn/20200307135306991.png)
labelImg这个工具网上都能下载到,如果找不到,我保存到百度网盘里了,链接:https://pan.baidu.com/s/17BbDw6RTzaFgsKhcow5lQQ
提取码:e6h6
在根目录下创建自己的数据文件夹VOCdevkit,其中在创建文件夹VOC2007,并在VOC2007文件夹中继续创建三个文件夹Annotations(放每张图像的标注信息xml文件)、JPEGImages(放图像文件)、ImageSets(其中再建一个文件夹Main存放训练图像和验证图像的文件名(不包含后缀))。【文件夹名称可以自取,只要后面写路径的时候注意一下就行】
目录结构如下:
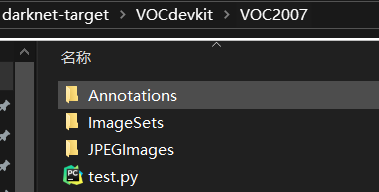
将test.py文件放入VOC2007文件夹下,并运行
python test.py #运行test.py
之后会在ImageSets/Main文件夹下的四个txt文件,生成的txt中内容如下,均为图像名称。
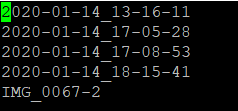
test.py文件如下:
###### test.py
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
2、Linux下部署YOLOv3
(1)下载Darknet工程文件,并把上一步骤制作的VOCdevkit文件夹放进来。
git clone https://github.com/pjreddie/darknet #下载项目
(2)将labels.py文件放在darknet根目录下,并运行
####### labels.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'trainval'), ('2007', 'test'), ('2007', 'val')]
#类别名称,根据需要进行修改
classes = ["chest", "upper_body", "whole_body"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
python labels.py #运行labels.py
运行完成之后,在根目录下生成四个txt文件:2007_train.txt,2007_trainval.txt,2007_test.txt,2007_val.txt,分别存放训练集和验证集中图片的完整路径,内容大概长这样。

采用如下命令合并文件:
cat 2007_train.txt 2007_trainval.txt > train.txt`
(3)创建obj.names,存放所有类别
在项目的data文件夹下创建obj.names,输入自己训练集中所有类别名称,我这边一共三类,就写三行。
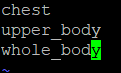
(4)创建obj.data,存放相关文件路径
在项目的cfg文件夹下创建obj.data,其中保存了训练集、验证集、类别名称文件、权重存放文件等的路径,可参考原本就有的coco.data的写法,修改其中的路径即可,我这边改成了这样。
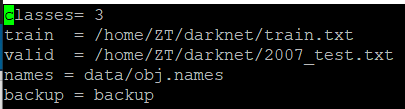
(5)创建yolov3-obj.cfg
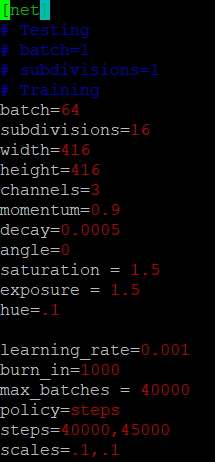
在项目的cfg文件夹下创建yolov3-obj.cfg,其中是整个网络的配置信息,可复制原来的yolov3.cfg文件然后做修改,修改的部分如下:
- 修改batch=64,subdivisions=16
- 修改三处 (每个[yolo]和每个[yolo]的前一层[convolutional]),根据实际情况修改
修改 [yolo] 层的classes=3 (类别总数)
修改 [convolutional] 层的filters=24
【注意】filters=3 * (5 + classes) - 最后一行修改random=1(多尺度输出)
- 有需要还可以修改训练图像的宽高、学习率、最大迭代次数等。

(6)下载预训练模型darknet53.conv.74,开始训练
wget https://pjreddie.com/media/files/darknet53.conv.74 #下载预训练模型
./darknet detector train cfg/obj.data cfg/yolov3-obj.cfg darknet53.conv.74
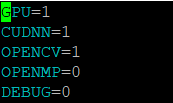
如果是GPU训练,只需要修改Makefile文件即可,修改完之后使用命令“make”进行编译,然后再使用以上命令进行训练。
修改如下:
(7)用训练好的模型检测
经过漫长的等待,训练完成之后,在darknet目录下有一个backup文件夹,里面存放了训练过程中保存的weights文件,用这些weights文件来进行检测。
./darknet detector test cfg/obj.data cfg/yolov3-obj.cfg backup/yolov3-obj_10000.weights data/1.jpg
./darknet detect cfg/yolov3-obj.cfg backup/yolov3-obj_10000.weights data/1.jpg #(这个命令默认使用coco.names,修改coco.names为自己的类别名称就OK了)
三、可能出现的问题
1、训练过程
还有一个darknet版本,是darknet完整的工程https://github.com/AlexeyAB/darknet
如果使用的是这个版本,那么Makefile中就有更多的参数可供选择,比如:
GPU加速:GPU=1, CUDNN=1, CUDNN_HALF=1(支持算力70以上的显卡)
CPU加速:OPENMP=1(多线程),AVX/AVX2=1(指令集)
2、测试过程
(1)问题描述: error while loading shared libraries: libcudart.so.10.2 cannot open shared object file: No such file or directory
解决方法(选个有sudo权限的用户):sudo cp /usr/local/cuda-10.2/lib64/libcudart.so.10.2 /usr/local/lib/libcudart.so.10.2 && sudo ldconfig
二、Linux下YOLOv3的封装
封装这部分,我才用的是darknet完整工程目录下的linux的部分,这个完整的工程里他已经把YOLOv3封装好了,接口是yolo_v2_class.hpp,作者已经把它封装成了一个类,但因为工程的需要,我需要提供给比人一个有固定格式的头文件,所以我就在这个封装好的类的基础上进行了相当于是再次封装,把其中的一部分功能取出来单独构成一个.h和.cpp。

上图展示了它的接口文件yolo_v2_class.hpp中的一部分,把加载网络的部分写在了类的构造函数中,也就是说每检测一次就会加载一遍网络,在实际的工程中会比较耗时,因此我把这部分摘出来,定义成一个全局变量,这样当重复检测多张图像的时候,整个模型只加载一次。
下面进行linux下的封装操作,我的具体做法:将原来在include文件夹下的yolo_v2_class.hpp文件移动到src文件夹下,并在src文件夹下添加以下文件:yolo_init.h,yolo_init.cpp,yolo_proc.cpp
在include文件夹下添加以下文件:yolo_proc.h,yolo_data.h
其中yolo_init.h、yolo_init.cpp实现了加载模型的功能;
yolo_proc.h、yolo_proc.cpp实现了具体的检测功能以及对检测结果的一些处理;
yolo_data.h中定义了需要使用到的一些数据结构。
//yolo_data.h
#ifndef _YOLO_DATA_H_
#define _YOLO_DATA_H_
#pragma pack(push)
#pragma pack(1)
//因为yolo默认检测用的是coco.names,如需改变则需要修改源码,所以我这边直接在coco.names里改成了自己的类别
//参数定义
#define NET_COCO "coco.names" //模型类别文件
#define NET_CFG "yolov3-obj.cfg" //模型配置文件
#define NET_WEIGHTS "yolov3-obj_10000.weights" //模型权重文件
// 类别的定义
enum TYPE
{
TYPE_CHEST = 0x00,
TYPE_UPPER_BODY,
TYPE_WHOLE_BODY,
TYPE_TOTAL_NUM
};
// 检测的结果
typedef struct tagTYPE_RESULT {
int x1, x2, y1, y2;
TYPE type;
}TYPE_RESULT;
#pragma pack(pop)
#endif
//yolo_init.h
#ifndef _YOLO_INIT_H_
#define _YOLO_INIT_H_
#include "yolo_v2_class.hpp"
Detector initalize_yolo();
#endif
//yolo_init.cpp
#include <iostream>
#include "yolo_init.h"
#include "yolo_data.h"
using namespace std;
Detector initalize_yolo() {
const char* names_file = NET_COCO;
const char* cfg_file = NET_CFG;
const char* weights_file = NET_WEIGHTS;
Detector detector(cfg_file, weights_file, 0); //初始化检测器
return detector;
}
//yolo_proc.h
#ifndef _YOLO_PROC_H_
#define _YOLO_PROC_H_
#include "yolo_data.h"
#pragma GCC visibility push(default)
//检测函数
int Recognition(const char *filename, TYPE_RESULT *pRes);
#pragma GCC visibility pop
#endif
//yolo_proc.cpp
#include <iostream>
#include <fstream>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <algorithm>
#include <string>
#include <opencv2/opencv.hpp>
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/highgui/highgui_c.h"
#include "yolo_init.h"
#include "yolo_data.h"
#include "yolo_proc.h"
using namespace std;
Detector detector = initalize_yolo(); //加载模型为全局变量
//以下这两段代码均为yolo项目中的源码
cv::Scalar obj_id_to_color(int obj_id) {
int const colors[6][3] = { { 1,0,1 },{ 0,0,1 },{ 0,1,1 },{ 0,1,0 },{ 1,1,0 },{ 1,0,0 } };
int const offset = obj_id * 123457 % 6;
int const color_scale = 150 + (obj_id * 123457) % 100;
cv::Scalar color(colors[offset][0], colors[offset][1], colors[offset][2]);
color *= color_scale;
return color;
}
void draw_boxes(cv::Mat mat_img, std::vector<bbox_t> result_vec, std::vector<std::string> obj_names,
int current_det_fps = -1, int current_cap_fps = -1)
{
int const colors[6][3] = { { 1,0,1 },{ 0,0,1 },{ 0,1,1 },{ 0,1,0 },{ 1,1,0 },{ 1,0,0 } };
char* buff = new char[256];
for (auto& i : result_vec) {
cv::Scalar color = obj_id_to_color(i.obj_id);
cv::rectangle(mat_img, cv::Rect(i.x, i.y, i.w, i.h), color, 4);
if (obj_names.size() > i.obj_id) {
std::string obj_name = obj_names[i.obj_id];
if (i.track_id > 0) obj_name += " - " + std::to_string(i.track_id);
cv::Size const text_size = getTextSize(obj_name, cv::FONT_HERSHEY_COMPLEX_SMALL, 1.2, 2, 0);
int max_width = (text_size.width > i.w + 2) ? text_size.width : (i.w + 2);
max_width = std::max(max_width, (int)i.w + 2);
//max_width = std::max(max_width, 283);
std::string coords_3d;
if (!std::isnan(i.z_3d)) {
std::stringstream ss;
ss << std::fixed << std::setprecision(2) << "x:" << i.x_3d << "m y:" << i.y_3d << "m z:" << i.z_3d << "m ";
coords_3d = ss.str();
cv::Size const text_size_3d = getTextSize(ss.str(), cv::FONT_HERSHEY_COMPLEX_SMALL, 0.8, 1, 0);
int const max_width_3d = (text_size_3d.width > i.w + 2) ? text_size_3d.width : (i.w + 2);
if (max_width_3d > max_width) max_width = max_width_3d;
}
cv::rectangle(mat_img, cv::Point2f(std::max((int)i.x - 1, 0), std::max((int)i.y - 35, 0)),
cv::Point2f(std::min((int)i.x + max_width, mat_img.cols - 1), std::min((int)i.y, mat_img.rows - 1)),
color, CV_FILLED, 8, 0);
putText(mat_img, obj_name, cv::Point2f(i.x, i.y - 16), cv::FONT_HERSHEY_COMPLEX_SMALL, 1.2, cv::Scalar(0, 0, 0), 2);
if (!coords_3d.empty()) putText(mat_img, coords_3d, cv::Point2f(i.x, i.y - 1), cv::FONT_HERSHEY_COMPLEX_SMALL, 0.8, cv::Scalar(0, 0, 0), 1);
}
}
if (current_det_fps >= 0 && current_cap_fps >= 0) {
std::string fps_str = "FPS detection: " + std::to_string(current_det_fps) + " FPS capture: " + std::to_string(current_cap_fps);
putText(mat_img, fps_str, cv::Point2f(10, 20), cv::FONT_HERSHEY_COMPLEX_SMALL, 1.2, cv::Scalar(50, 255, 0), 2);
}
}
int Recognition(const char *filename, TYPE_RESULT *pRes)
{
string names_file = "coco.names";
vector<std::string> obj_names;
ifstream ifs(names_file.c_str());
string line;
while (getline(ifs, line)) obj_names.push_back(line);
cv::Mat image = cv::imread(filename);
if (image.empty()) {
throw std::runtime_error("file not found");
}
//-------------------------开始检测----------------------------
vector<bbox_t> result_vec = detector.detect(filename);
//-----------------------处理检测结果---------------------------
TYPE_RESULT* last_result = (TYPE_RESULT*)malloc(sizeof(TYPE_RESULT));
if (result_vec.size() == 0) {
(*last_result).x1 = 0;
(*last_result).y1 = 0;
(*last_result).x2 = image.cols;
(*last_result).y2 = image.rows;
cout << "未检测出目标!" << endl;
}
else{
int max_area = 0;
cv::Rect max_rect;
unsigned int max_rect_id = 0;
float max_rect_prob = 0.0;
for (size_t i = 0; i < result_vec.size(); i++) {
cout << "x = " << result_vec[i].x << " y = " << result_vec[i].y << " width = " << result_vec[i].w << " height = " << result_vec[i].h << " prob = " << result_vec[i].prob << " obj_id = " << result_vec[i].obj_id << endl;
// 抠出目标部分并保存在ROI-results文件夹中,文件名格式为“类别-置信度.jpg”
if ((result_vec[i].x + result_vec[i].w) > image.cols)
result_vec[i].w = image.cols - result_vec[i].x;
if ((result_vec[i].y + result_vec[i].h) > image.rows)
result_vec[i].h = image.rows - result_vec[i].y;
cv::Rect rect(result_vec[i].x, result_vec[i].y, result_vec[i].w, result_vec[i].h); //目标所在的矩形框
int area = result_vec[i].w * result_vec[i].h;
cout << "rect_area = " << area << endl;
//判断是否是最大的矩形框
if (max_area < area) {
max_area = area;
max_rect = rect;
max_rect_id = result_vec[i].obj_id;
max_rect_prob = result_vec[i].prob;
//将最大边界框的信息值赋值给结构体指针
(*last_result).x1 = result_vec[i].x;
(*last_result).y1 = result_vec[i].y;
(*last_result).x2 = result_vec[i].x + result_vec[i].w;
(*last_result).y2 = result_vec[i].y + result_vec[i].h;
if (result_vec[i].obj_id == 0) {
(*last_result).type = TYPE_CHEST;
}
if (result_vec[i].obj_id == 1) {
(*last_result).type = TYPE_UPPER_BODY;
}
if (result_vec[i].obj_id == 2) {
(*last_result).type = TYPE_WHOLE_BODY;
}
}
}
draw_boxes(image, result_vec, obj_names);
cv::namedWindow("test", CV_WINDOW_NORMAL);
cv::imshow("test", image);
cv::waitKey(2000);
//------------处理结果:抠出图像中的目标部分,保存下来-----------------
cv::Mat ROI = image(max_rect); //抠出的部分
char* buff = new char[256];
string str = string(filename).substr(string(filename).find_last_of('/') + 1, string(filename).rfind(".") - (string(filename).find_last_of('/') + 1));
sprintf(buff, "%d-%f-%s", max_rect_id, max_rect_prob, str.c_str());
std::string prefix = "ROI-results/"; //保存检测到的目标的文件夹
if (access(prefix.c_str(), F_OK) == -1) //如果文件夹不存在
mkdir(prefix.c_str(), S_IRWXU); //则创建
string strImgSavePath = "ROI-results/" + string(buff) + ".jpg";
imwrite(strImgSavePath, ROI);
delete[] buff;
memcpy(pRes, last_result, sizeof(TYPE_RESULT));
return 0;
}
}
在src中添加test.cpp文件用于测试,内容如下:
//test.cpp
#include <iostream>
#include <opencv2/opencv.hpp>
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/highgui/highgui_c.h"
#include "yolo_proc.h"
#include "yolo_data.h"
using namespace std;
int printResult(TYPE_RESULT* pRes) {
cout << "\ntype = " << pRes->type << " x1 = " << pRes->x1 << " y1 = " << pRes->y1 << " x2 = " << pRes->x2 << " y2 = " << pRes->y2 << endl;
if (pRes->type == TYPE_CHEST) {
cout << "TYPE_CHEST" << endl;
}
if (pRes->type == TYPE_UPPER_BODY) {
cout << "TYPE_UPPER_BODY" << endl;
}
if (pRes->type == TYPE_WHOLE_BODY) {
cout << "TYPE_WHOLE_BODY" << endl;
}
return 0;
}
int main() {
TYPE_RESULT* pRes = (TYPE_RESULT*)malloc(sizeof(TYPE_RESULT));
const char *filename = "/home/1.jpg";
Recognition(filename, pRes);
printResult(pRes);
return 0;
}
修改项目文件夹下的Makefile文件,具体修改如下几个部分:
- 设置LIBSO=1 ,用于生成动态库
LIBSO=1
#………………………………
#这里修改动态库的名字,必须是lib开头
LIBNAMESO=libyolo.so
- 添加以下定义,用于生成静态库
#静态库的名字也必须是lib开头
ALIB=libyolo.a
AR=ar
ARFLAGES=rcs
- 修改OBJ,也就是在“OBJ=”后面直接加上你自己添加的文件.o
OBJ=yolo_proc.o yolo_init.o yolo_v2_class.o ……
- 修改DEPS,即
DEPS = $(wildcard src/*.h) $(wildcard src/*.hpp) Makefile include/darknet.h include/yolo_data.h include/yolo_proc.h
此处src中有.hpp是因为要把yolo_v2_class.hpp包含进去
- 修改all的依赖关系文件,即在最后添加静态库的名字
all: $(OBJDIR) backup results setchmod $(EXEC) $(LIBNAMESO) $(APPNAMESO) $(ALIB)
- 修改生成动态链接库的命令,即需要添加依赖关系文件
$(LIBNAMESO): $(OBJDIR) $(OBJS) include/yolo_data.h include/yolo_proc.h src/yolo_proc.cpp
$(CPP) -shared -std=c++11 -fvisibility=hidden -DLIB_EXPORTS $(COMMON) $(CFLAGS) $(OBJS) -o $@ $(LDFLAGS)
#其中test.cpp为自己创建的测试文件
$(APPNAMESO): $(LIBNAMESO) include/yolo_data.h include/yolo_proc.h src/test.cpp
$(CPP) -std=c++11 $(COMMON) $(CFLAGS) -o $@ src/test.cpp $(LDFLAGS) -L ./ -l:$(LIBNAMESO)
- 添加生成静态库的命令
$(ALIB): $(OBJS)
$(AR) $(ARFLAGES) $@ $^
- 在最后的删除命令中,最后添加静态库名
clean:
rm -rf $(OBJS) $(EXEC) $(LIBNAMESO) $(APPNAMESO) $(ALIB)
到此,Makefile均修改完毕,cd到darknet目录下,直接make,就可以生成libyolo.so和libyolo.a文件了。
那么对于生成的.so和.a文件如何使用?下面实例:
- 新建一个项目文件夹SO,在SO文件夹下
新建lib文件夹:将libyolo.a和libyolo.so文件复制到lib文件夹下
新建src文件夹:将test.cpp复制到src文件夹下
新建include文件夹,将yolo_data.h、yolo_proc.h复制到include文件夹下
将yolov3-obj.cfg、coco.names、yolov3-obj_10000.weights复制到SO文件夹下
新建CMakeLists.txt,内容如下:
#CMakeLists.txt
cmake_minimum_required(VERSION 2.8) #cmake最低版本
#项目信息
project(SO)
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -pthread -fopenmp")
#add_definitions(-std=c++11 -lpthread)
ADD_DEFINITIONS(-DOPENCV)
# find opencv
find_package(OpenCV 3.4.3 REQUIRED)
find_package(Threads REQUIRED)
message(${OpenCV_INCLUDE_DIRS})
#include路径
include_directories(${OpenCV_INCLUDE_DIRS})
include_directories(${PROJECT_SOURCE_DIR}/include)
#需要链接的库文件目录
link_directories(${PROJECT_SOURCE_DIR}/lib)
# 测试静态库,静态库的路径
find_library(libNJUST_TARGET_TYPE.a ${PROJECT_SOURCE_DIR}/lib/)
#测试动态库,动态库路径
#find_library(libNJUST_TARGET_TYPE.so ${PROJECT_DOURCE_DIR}/lib/)
#查找src目录下所有源文件,将名称保存到DIR_DRC变量
aux_source_directory(./src/ DIR_SRC)
#制定生成目标SO
add_executable(SO ${DIR_SRC})
#设置要链接的库的名称,测试静态库
target_link_libraries(SO ${OpenCV_LIBS} libNJUST_TARGET_TYPE.a ${CMAKE_THREAD_LBS_INIT})
#设置要链接的库的名称,测试动态库
#target_link_libraries(SO ${OpenCV_LIBS} libNJUST_TARGET_TYPE.so ${CMAKE_THREAD_LBS_INIT})
#message(STATUS "OpenCV_LIBS: ${OpenCV_LIBS}")
- cd到SO文件夹,用命令编译CMakeLists.txt:
cmake .
之后会生成Makefile文件,再用命令进行编译:
make
之后会生成可执行文件SO,用命令执行:
./SO
封装到此结束。
按上面的流程来,如果在生成动态链接库和静态链接库的时候没出现error,.so和.a文件顺利生成,那么代码上应该没什么问题,代码有问题的话在生成的时候会报错,对着问题改就好了。
测试的时候,如果运行的过程中出现很多关于函数未定义的问题,一般都是CMakeLists.txt中没配置好第三方库,比如我当时配置OpenCV的时候包含目录、路径啥的写的都是对的,但还是一直报错,所有使用到OpenCV的函数都报了函数未定义的错误,后来我网上查了好久,才知道原来是没添加OpenCV的版本导致的错误,添加上OpenCV的版本就行了,当时的服务器上有好几个OpenCV的版本,所以出现了版本不匹配的问题,头秃噢!
下面放上一些我出现过的问题:
1、问题: /usr/bin/ld: /home/ZT/SO/lib/libNJUST_TARGET_TYPE.a(blas.o):undefined reference to symbol ‘pthread_create@@GLIBC_2.2.5’
//lib/x86_64-linux-gnu/libpthread.so.0: 无法添加符号:DSO missing from command line
解决方法:在cmakelists.txt添加“-pthread”
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -pthread")
2、问题:/usr/bin/ld: /home/ZT/SO/lib/libNJUST_TARGET_TYPE.a(blas.o):undefined reference to symbol ‘omp_get_num_thread@@OMP_1.0’
//lib/x86_64-linux-gnu/libgomp.so.1: 无法添加符号:DSO missing from command line
解决方法:在Makefile中添加openmp链接库命令
LINKFLAGS += -fopenmp -pthread -fPIC $(COMMON_FLAGS) $(WARNINGS) -std=c++11
在CMake中和上面一样SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -openmp")
(如果要配置OpenMP的路径,就相当于把CMakeLists.txt中所有“OpenCV”出现的部分改成“OpenMP”就行了,跟配置OpenCV一样的,在我这个项目中好像直接加-openmp就行,不用再添加路径)
3、出现一堆:"xxxxcpp:对cv::String未定义的引用" “xxxxcpp:对cv::rectangle未定义的引用”“xxxxcpp:对cv::namedWindow未定义的引用”
(反正就是opencv中函数未定义的引用)
解决方法:除了要在cmakelists.txt中配置opencv之外,必须要指定opencv的版本,不同的版本可能会有冲突。
一些常用命令:
1. 添加头文件目录
INCLUDE_DIRECTORIES
语法:include_directories([AFTER|BEFORE] [SYSTEM] dir1 [dir2 ...])
它相当于g++选项中的-I参数的作用,也相当于环境变量中增加路径到CPLUS_INCLUDE_PATH变量的作用。
include_directories(../../../thirdparty/comm/include)
2. 添加需要链接的库文件目录
LINK_DIRECTORIES
语法:link_directories(directory1 directory2 ...)
它相当于g++命令的-L选项的作用,也相当于环境变量中增加LD_LIBRARY_PATH的路径的作用。
link_directories("/home/server/third/lib")
3. 查找库所在目录
FIND_LIBRARY
语法:FIND_LIBRARY(RUNTIME_LIB rt /usr/lib /usr/local/lib NO_DEFAULT_PATH)
cmake会在目录中查找,如果所有目录中都没有,值RUNTIME_LIB就会被赋为NO_DEFAULT_PATH
4. 添加需要链接的库文件路径
LINK_LIBRARIES
语法:link_libraries(library1 <debug | optimized> library2 ...)
可以链接一个,也可以多个,中间使用空格分隔.
5. 设置要链接的库文件的名称
TARGET_LINK_LIBRARIES
语法:target_link_libraries(<target> [item1 [item2 [...]]] [[debug|optimized|general] <item>] ...)
6. 为工程生成目标文件
add_executable
语法:add_executable(<name> [WIN32] [MACOSX_BUNDLE] [EXCLUDE_FROM_ALL] source1 [source2 ...])
简单的例子如下:add_executable(demo main.cpp )
7、LINK_DIRECTORIES 要放在ADD_EXECUTABLE() or ADD_LIBRARY()前面。
8、
查看opencv安装库:pkg-config opencv --libs
查看opencv安装版本:pkg-config opencv --modversion
查看linux下的opencv安装路径:sudo find / -iname "*opencv*"














 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









