









论文:A Survey of Zero-Shot Learning: Settings, Methods, and Applications / 零样本学习综述:设定、方法和应用
作者:WEI WANG, VINCENT W. ZHENG, HAN YU and CHUNYAN MIAO
发表刊物:ACM Transactions on Intelligent Systems and Technology
发表年度:2019
下载地址:https://dl.acm.org/doi/abs/10.1145/3293318
Abstract / 摘要
大多数机器学习方法关注这样的分类任务:样本所属的类别对应的实例在训练过程中是已知的。实际上,很多应用需要在从未见过类对应的实例的情况下对样本进行分类。零样本学习是一类强大的学习范式,在零样本学习设定中,训练样本所属类别集合和测试样本所属的类别集合是不相交的。本文中,作者提供了一个关于零样本学习的综述研究。首先,作者介绍了零样本学习的概况,根据模型优化过程中使用数据的不同,将零样本学习进一步划分为三种学习设定;其次,作者描述了现有的零样本学习研究中使用到的不同的语义空间;第三,作者对现有的零样本学习方法进行分类并介绍了每个类别中的代表性方法;第四,作者讨论了零样本学习的应用;最后,作者提出了零样本学习未来的研究方向。
1 INTRODUCTION / 介绍
有监督分类方法在研究中取得了成功并且被应用到许多领域,尤其是近些年随着深度学习技术的快速发展,有监督分类方法取得了进一步进步。但是这种学习范式有一些固有的限制:
- 在有监督分类任务中,需要每个类别有足够的训练样本;
- 学习到的分类器只能对训练样本所属的类别进行分类,不具备对以前没有见过的类别进行分类的能力;
但是在实际应用中,为每个类别收集足够多的训练样本是很困难的,而且会出现测试样本的所属的类别不包含在训练样本所属的类别中的情况。为了解决这些问题,学者们提出了基于不同学习范式的方法:为了解决每一个类别只有少量训练样本可用情况下的分类问题,提出了小样本学习/单样本学习方法,在为只有少量样本的类别学习分类器时,会用到其他类别中包含的知识;为了解决对以前没有见过的类别进行分类的问题,学者们进行了一系列研究。
在上述学习范式中,如果测试样本所属的类别在模型训练过程中没有出现,那么学习到的分类器就无法确定测试样本的标签。但是,在许多实际应用场景中,我们往往需要模型具备这种能力,以下是一些典型应用场景:
- 目标类数量较大:比如在目标检测和行为识别任务中,目标类别数量过多,从而导致一些类别没有标记样本;
- 目标类比较稀少:比如在细粒度的目标检测任务中,要识别不同种子开出的花,为每个花种采集花的图片是很困难的,而且对于一些比较稀有的花种,获取不到标记样本;
- 目标类随时间变化:比如在识别一个特定系列或品牌的产品图片时,由于该系列或品牌中会不断推出新产品,实时收集这些标记样本是很困难的;
- 目标类样本获取成本太高:在一些特定的任务中,获取标记样本是很昂贵而且很耗时的,比如在图像语义分割问题中,需要对训练数据中的图像进行像素级的标记。
在上述应用中,有很多类别没有标记样本,但我们希望分类器具备对这些类别进行识别的能力,基于这个考虑,学者们提出了零样本学习的概念。零样本学习的目的就是实现对没有标记样本的类别的有效识别。近年来,出现了一大批零样本学习在计算机视觉、自然语言处理和普适计算中的研究工作。
1.1 Overview of Zero-Shot Learning / 零样本学习概述

从定义中我们可以看出,零样本学习的基本思想是把训练样本中包含的知识迁移到测试样本分类任务中,因此零样本学习可以视为迁移学习问题。在迁移学习中,在针对目标域中特定任务构建模型时,会将源域和源任务中包含的知识迁移到目标域。在零样本学习中,虽然训练样本和测试样本位于同一特征空间中,但是训练样本所属的类别集合和测试样本所属的类别集合是不同的,因此零样本学习属于异构迁移学习的范畴。
零样本学习通过引入辅助信息的方式解决未知类无标记样本的问题,每个未知类都需要有辅助信息,而且辅助信息要与特征空间中的实例相关联。引入辅助信息的方法是受人类认知的启发,人类可以在语义背景知识的帮助下完成零样本学习。常见的辅助信息是未知类的语义信息,语义信息构成的空间称为语义空间,语义空间也是一个实数空间。可见类和未知类在语义空间中的向量表示称为类原型,类原型函数输入类标签并输出相应的类原型。

1.2 Learning Setting / 学习设定
在零样本学习设定中,由于训练样本和测试样本的分布是不同的,导致在训练样本上训练的模型在测试样本上的性能会衰减,这被称为领域漂移现象。通过在训练过程中引入关于测试样本的信息,可以有效缓解领域漂移现象,这种学习范式被称为直推式学习。基于直推式学习的程度,将现有关于零样本学习的研究可以分为三类:


在CIII设定下,由于在模型学习过程中没有引入测试样本的信息,所以该设定下的一些方法一般会面临严重的领域漂移问题,但由于模型不是针对特定未知类和测试样本进行优化的,会导致该设定下的方法具有较好的泛化能力;在CTII设定下,模型训练过程中使用了未知类原型信息,领域漂移问题会得到缓解,但模型对于新的未知类的泛化能力也会受限;在CTIT设定下,模型训练过程中引入了特定未知类和测试样本的信息,因此该设定下的方法能够更好地缓解领域漂移问题,但模型对新的未知类的泛化能力也最差。
2 SEMANTIC SPACES / 语义空间
语义空间包含类别的语义信息,是零样本学习中的一个重要概念,当前研究中使用了多种语义空间。根据语义空间是如何被构建的,可以将语义空间分为人工语义空间和机器语义空间。语义空间分类如下图所示。

2.1 Engineered Semantic Spaces / 人工语义空间
在人工语义空间中,语义空间的每个维度都是由人设计的,人工语义空间包括属性空间、词汇空间、关键词空间等。
- 属性空间:由一组描述类别的属性构成的语义空间,是零样本学习中最常用的一种属性空间,属性空间的每一维代表类别在该属性上的取值,可以是0/1,也可以是表示类别有某个属性的置信水平的是实数值。
- 词汇空间:由一组词汇构成的语义空间。
- 关键词空间:由一组从类别的文本描述中抽取的关键词构成的语义空间,语义空间的每一维度对应一个关键词,类别的文本描述往往要从网络空间中获取。
- 此外还有一些针对特定问题的语义空间。
人工语义空间的优势在于其能够在语义空间和类原型的构建过程中融入人类领域知识,缺点在于严重依赖于人工标注。
2.2 Learned Semantic Spaces / 学习到的语义空间
在机器语义空间中,空间的每一维不是由人类设计的,类原型往往是通过一些机器学习算法得到的,而且这些类原型中的每个维度没有显式含义,类的语义信息包含在整个类原型向量中。用于提取类原型的模型可以是预训练模型,也可以是针对零样本学习问题专门训练的模型。机器语义空间包括标签嵌入空间、文本嵌入空间、图像表示空间等。
- 标签嵌入空间:通过对类别标签的嵌入构成的语义空间,这类语义空间的构建往往依赖于自然语言处理中的词嵌入技术。现有的研究采用了诸如Word2Vec、GloVe等词嵌入技术,而且一般在如Wikipedia、Flickr的大型语料库中训练词嵌入模型。一般为一个类标签生成一个类原型,也有研究为一个类标签生成多个类原型。
- 文本嵌入空间:使用对类别的文本描述的嵌入构成的语义空间,这类语义空间的构建往往也依赖于自然语言中的嵌入学习技术。
- 图像表示空间:通过从属于某个类别的图像中抽取信息构成的语义空间。以视频行为识别任务为例,我们可以从搜索引擎中找到某个动作对应的图像,然后使用预训练模型从图像中抽取特征,将属于某个动作的图像特征融合构成该动作的类原型。
机器语义空间的优势在于语义空间的构建过程不依赖于人力,缺点是类原型的每个维度的含义不明确。
3 METHODS / 方法
作者将零样本学习方法分为两类:基于分类器的方法和基于实例的方法,其中基于分类器的方法的关注点在于如何直接为未知类学习分类器,而基于实例的方法的关注点在于如何获取属于未知类的标记样本并使用这些样本进行分类器学习。零样本学习方法的分类框架如下图所示。作者主要考虑标准的小样本学习设定,即只考虑一个语义空间,将每个类表示成语义空间中的一个类原型。将在3.3节讨论有多个语义空间或一个类有多个类原型的情况。
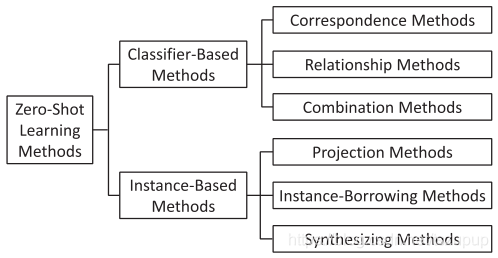
3.1 Classifier-Based Methods / 基于分类器的方法
基于构建分类器的方法的不同,作者进一步将基于分类器的方法分为三个类别:基于一致性的方法、基于关系的方法和基于组合的方法。现有的基于分类器的方法一般采取1-vs-剩余的方式训练零样本学习分类器,即为每个未知类学习一个二分类器。

在语义空间中,每个类别有一个对应的类原型,因此类原型可以视为该类别的表示;同时,在特征空间中,每个类别对应一个二分类器,该二分类器也可以视为类别的表示。一致性方法的目的是学习这两种类别表示之间的一致性函数。在一致性方法中,一致性函数将类别
的类原型
作为输入,输出该类别对应的二分类器
中的参数
,即
。在得到一致性函数之后,对于未知类别
和其类原型
,可以构建其对应的二分类器
。
总结一下,一致性方法的一般性流程为:
1、使用可用数据学习一致性函数;
2、对于每个未知类和其类原型
,在一致性函数
已知的情况下,构建类别对应的二分类器
;
3、使用构建的未知类对应的二分类器集合,对测试样本
进行分类。

基于关系的方法旨在通过已经学习到的可见类的分类器以及类别之间的关系为未知类构建分类器。在特征空间中,我们可以使用训练数据构建可见类的分类器集合;我们可以通过类原型之间的关系或其他方法得到可见类与未知类之间的联系。基于关系的方法的基本工作流程如下:
1、基于可用数据构建可见类的分类器集合
;
2、通过计算类原型或其他方法构建可见类和未知类之间的关系;
3、基于已有的未知类与可见类之间的关系和可见类的分类器集合
,构建未知类的分类器集合
,对测试样本
进行分类。
基于组合的方法的基本思想是通过组合构成类的属性对应的分类器构建未知类的分类器。在基于组合的方法中,将类别视为属性的组合,类别在语义空间中的类原型中每一维度对应一个特定属性,根据属性是否存在标记为1或0。该方法的基本工作流程为:
1、基于可用数据,构建属性分类器集合;
2、通过推理框架,基于属性分类器集合,构建未知类的分类器集合。
3.2 Instance-Based Methods / 基于实例的方法
基于实例的方法首先为未知类获取标记实例,而后使用这些实例学习零样本分类器。根据实例来源的不同,可以将基于实例的方法进一步分为基于映射的方法、基于实例借用的方法和合成方法。

基于映射的方法通过将特征空间中的实例和语义空间中的原型映射到同一个空间中来获取未知类的标记实例。该方法把特征空间中的特征表示视为类别在特征空间中的实例,把语义空间中的类原型视为类别在语义空间中的实例,通过将这两个空间中的实例映射到同一空间中,可以获取到未知类的一个有标记样本。该方法的基本工作流程为:
1、特征空间中的实例
和语义空间
中的类原型
被映射到同一空间
中:
;
2、在映射空间中构建分类器:由于每个未知类在映射空间中只有一个标记实例,即其类原型在映射空间中的映射,故采用1-近邻分类器构建分类模型。
此外,映射空间可以是多样化的:可以是语义空间、可以是特征空间、可以是另一个空间或几个空间。

基于实例借用的方法通过借用训练集中的实例来为未知类寻找标记实例。 基于实例借用的方法基于类别间的相似性工作,比如,在图像目标识别任务中,我们想要为类别“卡车”学习一个分类器但却没有卡车的图像,那么我们可以“借用”汽车和公共汽车的图像,因为这两类车和卡车相似,将这两类车的图像作为正例训练分类器即可得到卡车的分类器。注意以上做法和人类认知世界的过程很相像,人类可能从未看到过某些类别的实例,但他们可能看到过一些相似类别的实例,通过对这些相似类别的实例的学习,人类可以做到识别未知类别。基于实例借用的方法的基本流程为:
1、对于每个未知类,从可见类对应的训练样本中抽取一些实例作为未知类的实例;
2、基于抽取的“未知类实例”,训练未知类的分类器,并对测试样本进行分类。
注意既可以从所有可见类中“借用”样本,也可以只从部分可见类中“借用”样本,一般根据类原型间的相似性抽取可见类集合。

合成方法的基本思想是通过合成一些伪实例的形式为未知类构造标记实例。合成方法的基本流程为:
1、为每个未知类合成一些伪实例;
2、通过合成的伪实例,为每个未知类训练分类器,并对测试样本进行分类。
注意为未知类构造伪实例时,往往也需要用到可见类和未知类原型之间的相似性,当未知类有了伪实例后,可以将可见类和未知类实例放在一起以有监督学习的方式进行训练。
3.3 Discussions / 讨论
本节主要比较各类方法的性能、优缺点,以及特定数据设定下的零样本学习方法,此外,还介绍了多标签零样本学习以及广义零样本学习的概念。
1)不同方法的性能比较
现有的零样本学习方法往往是面向不同领域的不同问题而构建的,在统一的实验设定下的对比发现,在每一类学习设定下,没有方法能够在某个数据集上的性能显著优于其他方法,这表明在所有的分类任务中,没有方法能够取得最好的结果。作者通过对比不同的研究发现,在CIII设定下和在CTII设定下方法的性能没有太大差异,然而,在CTIT设定下方法的性能显著优于CIII设定和CTII设定,这表明,与CIII设定下的方法相比较,CTII方法并没有充分利用未知类原型中的信息;对于CTIT设定下的方法,由于其包含了关于未知类原型和测试样例的有效信息,因此能或得更好的性能。
2)不同方法的优缺点
基于分类器的方法和基于实例的方法采取不同的策略解决零样本分类问题:基于分类器的方法直接从可用数据中学习未知类的分类器,而基于实例的方法通过为未知类构建标记实例,而后通过构造的实例为未知类学习分类器,两类方法下每种方法的具体比较如下:
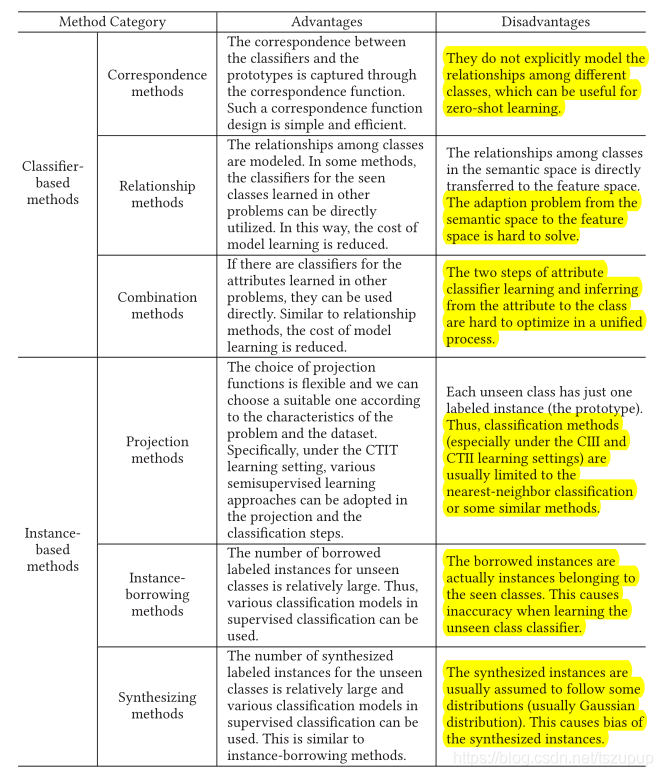
3)特定数据设定下的方法
在不同的数据设定下,会存在零样本学习的各种变体。
1)训练实例的不同设定:比如在训练数据中出现了既不属于可见类又不属于未知类的额外训练样本;
2)语义空间的不同设定:存在多个语义空间
4)多标签零样本学习
指在零样本学习设定下,每个实例对应超过1个标签,现有研究一般将每个标签独立对待或利用标签之间的关系进行建模。
5)广义零样本学习
在传统的零样本学习设定中,训练样例所属的类别和测试样例所属的类别是不相交的,然而在实际场景中,这种问题设定是不现实的,在许多应用中,训练样例和测试样例都会出现了测试阶段,这一问题被称为广义零样本学习问题,这一问题比传统的零样本学习问题更具挑战性,尽管目前有这方面的研究,但它们的效果往往都没有零样本学习设定下的好,因此需要构建在广义零样本学习设定下表现出更好性能的算法。
4 APPLICATIONS / 应用
零样本学习在许多领域都有应用。
1)Computer Vision / 计算机视觉
在计算机视觉领域,零样本学习被广泛应用于图片和视频分析中。
在图片分析中,零样本学习主要应用在图像识别、图像分割、人体姿势评估、行人重识别、图片检索等任务中;
在视频分析中,零样本学习主要应用在视频动作识别、零样本事件检测、零样本流检索等任务中。
2)Natural Language Processing / 自然语言处理
在自然语言处理领域,零样本学习主要应用在零样本翻译、语义句子分类、跨语言文档检索和关系抽取等任务中。
3)Others / 其他
零样本学习还被应用于普适计算、计算生物学、安全隐私等领域的特定问题中。
5 FUTURE DIRECTIONS / 未来研究方向
1)Characteristics of Input Data / 输入数据的特点
当前关于零样本学习的研究没有充分考虑到任务对应的输入数据的特点:比如在基于传感器的行为识别任务中,输入数据是时间序列数据;在图像目标检测任务中,我们不仅可以考虑整个图片的特征,还可以考虑目标各部分的信息。此外,在零样本学习建模过程中,还可以利用任务相关的多模态数据。
2)Selection of Training Data / 训练数据的选取
现有的关于零样本学习的研究设定中,训练数据和测试数据一般具有相同的数据类型和语义类型,但在实际应用中,训练集和测试集可以不同,比如训练集和测试集可以分别来自具有不同语义空间的类别。在许多应用中,来自不同数据类型或语义类型的数据往往比较容易获取。此外,在当前零样本学习研究中,训练数据对应的可见类往往是预定义的,如果算法能够主动标记训练数据,那数据标注的压力会减小很多。在引入辅助信息后,怎样在模型学习过程中融入辅助信息也很关键。
3)Selection of Maintenance of Auxiliary Information / 辅助信息的选择
辅助信息对于未知类别的分类很重要,当前一般采用类别的属性信息、语义信息等作为辅助信息,我们也可以采用一些人工定义的类别相似性信息作为辅助信息。
4)More Realistic and Application-Specific Problem Settings / 更加贴近现实的任务特定的问题设定
零样本学习研究应该往更接近现实的方向进发,比如广义的零样本学习中,测试样本可用同时来自可见类和未知类。此外,未知类集合比较大的情况下如何做分类?即大规模零样本学习问题。此外,有些问题中的训练数据和语义信息只能在线获取,因此需要零样本学习模型能够对这类数据进行分析。总之,基于任务的特点,要考虑更多任务相关的零样本学习设定。
5)Theoretical Guarantee / 理论保证
现有的零样本学习模型往往基于启发式算法,缺乏理论保障,比如缺乏对如何选择辅助信息、训练和测试过程中到的信息迁移机制、怎样保障训练和测试过程中迁移的信息的有效性等问题的理论研究。
6)Combination with Other Learning Paradigms / 与其他学习范式的融合
零样本学习可以与弱监督学习、主动学习、终身学习、哈希、强化学习等方法结合以解决特定任务。
6 CONCLUSION / 结论
本文提供了一个详尽的关于零样本学习的综述性研究,作者依次介绍了零样本学习的概况、不同设定、使用的语义空间、使用的方法以及应用。最后,作者从不同角度推荐了几个零样本学习研究方向。














 1548
1548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









