









我们在做推荐或者信息检索任务时经常需要比较项目嵌入和项目嵌入之间或者用户嵌入和项目嵌入之间的相似度,然后进行推荐。余弦相似度的计算公式如下:
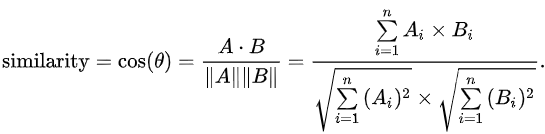
余弦相似度cosine similarity和余弦距离cosine distance是相似度度量中常用的两个指标,我们可以用sklearn.metrics.pairwise下的cosine_similarity和paired_distances函数分别计算两个向量之间的余弦相似度和余弦距离,效果如下:
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity, paired_distances
x = np.array([[0.26304135, 0.91725843, 0.61099966, 0.40816231, 0.93606288, 0.52462691]])
print(x)
y = np.array([[0.03756129, 0.50223667, 0.66529424, 0.57392135, 0.20479857, 0.27286363]])
print(y)
# 余弦相似度
simi = cosine_similarity(x, y)
print('cosine similarity:', simi)
# 余弦距离 = 1 - 余弦相似度
dist = paired_distances(x, y, metric='cosine')
print('cosine distance:', dist)
这里可以看到,余弦相似度 + 余弦距离 = 1。
我们试一下用cosine_similarity和paired_distances函数分别计算多个向量与一个向量的余弦相似度和余弦距离,效果如下:
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity, paired_distances
x = np.array([[0.26304135, 0.91725843, 0.61099966, 0.40816231, 0.93606288, 0.52462691], [0.26304135, 0.91725843, 0.61099966, 0.40816231, 0.93606288, 0.52462691]])
print(x)
y = np.array([[0.03756129, 0.50223667, 0.66529424, 0.57392135, 0.20479857, 0.27286363]])
print(y)
# 余弦相似度
simi = cosine_similarity(x, y)
print('cosine similarity:', simi)
# 余弦距离 = 1 - 余弦相似度
dist = paired_distances(x, y, metric='cosine')
print('cosine distance:', dist)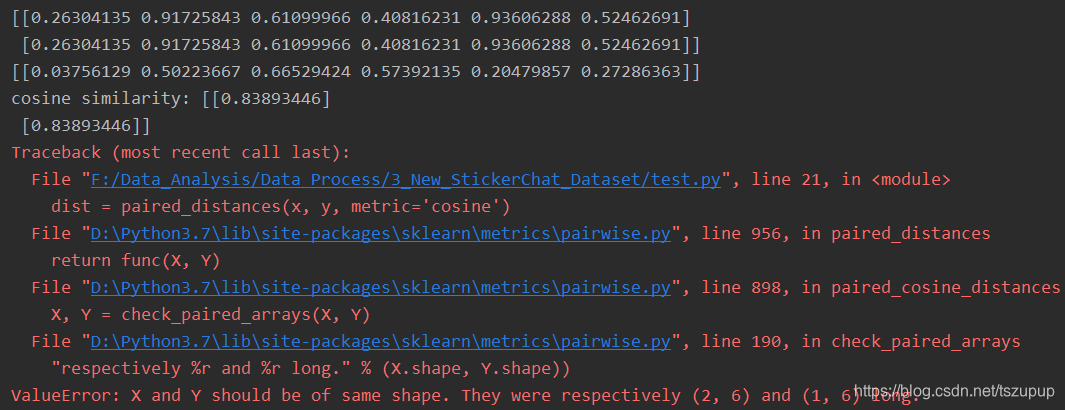
可以看到这里余弦相似度可以正常计算,但在计算余弦距离时报错。
现在我们自己写程序批量计算多个向量与多个向量之间的余弦相似度和余弦距离,效果如下:
def distCosine(x, y):
"""
:param x: m x k array
:param y: n x k array
:return: m x n array
"""
xx = np.sum(x ** 2, axis=1) ** 0.5
x = x / xx[:, np.newaxis]
yy = np.sum(y ** 2, axis=1) ** 0.5
y = y / yy[:, np.newaxis]
dist = 1 - np.dot(x, y.transpose()) # 1 - 余弦距离
return dist
x = np.random.rand(10, 6)
print(x)
y = np.random.rand(5, 6)
print(y)
dist = distCosine(x, y)
print(dist)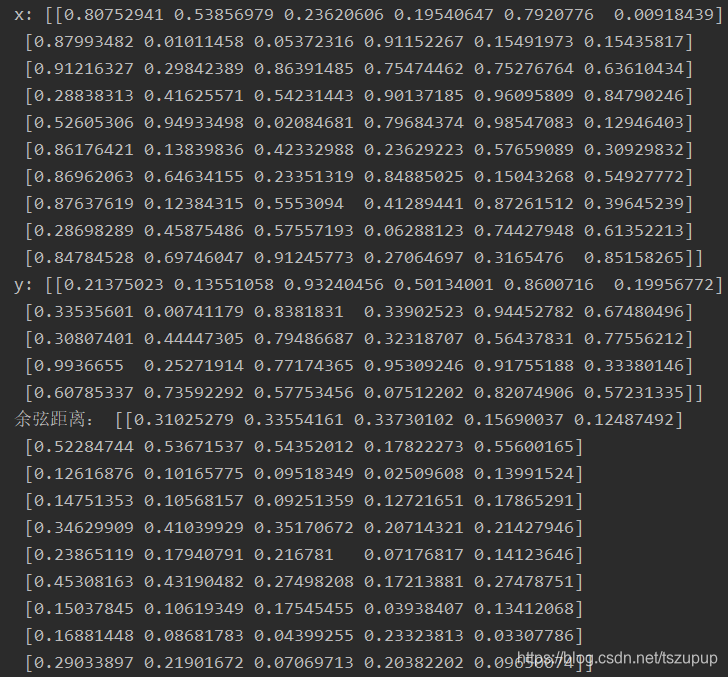
我们测试一下写的程序计算的余弦距离是否和paired_distances函数计算的一致,以第一行为例:
import numpy as np
from sklearn.metrics.pairwise import paired_distances
# x
x1 = np.array([[0.80752941, 0.53856979, 0.23620606, 0.19540647, 0.7920776, 0.00918439]])
x10 = np.array([[0.84784528, 0.69746047, 0.91245773, 0.27064697, 0.3165476, 0.85158265]])
# y
y1 = np.array([[0.21375023, 0.13551058, 0.93240456, 0.50134001, 0.8600716, 0.19956772]])
y5 = np.array([[0.60785337, 0.73592292, 0.57753456, 0.07512202, 0.82074906, 0.57231335]])
# 余弦距离 = 1 - 余弦相似度
dist1_1 = paired_distances(x1, y1, metric='cosine')
print('cosine distance:', dist1_1)
dist10_5 = paired_distances(x10, y5, metric='cosine')
print('cosine distance:', dist10_5)
可以看出计算结果是正确的,请放心使用。

















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









