










这是新增识别物体训练前的一个预处理过程。你的额外标注要建立在模型已经具备的识别能力的基础上。
0.参考资料:
1.主要参考源:
Tutorial: Importing Local YOLO Pre-Annotated Images to Label Studio | Label Studio
2.备用的label-studio-converter文档:
1.安装label转换工具
pip install label-studio-converter
2.将原有的coco数据集放在C:根目录下:例如:

2.1 classes.txt的内容为
classes的列表,每个物体一行,不允许有同名文件。注意,yolo的classid是从0开始的。缺省的class_id有80个,即:0~79,第一个用户自定义class_id=80。
person
bicycle
car
2.2 image, labels不再拆分为训练和验证
3.转换
这一步会借助label-studio-converter工具(pip install安装)来进行实际的yolo label->label studio格式的.json .xml文件格式转换。
注意,命令行中,images在classes.txt文件所在目录中单独列出,然后, -i的参数是 classes.txt所在目录。 -i 指向的目录结构,需要把images和labels分别分文件夹放置,然后把classes.txt放在这个文件夹的根目录。--image-root-url指向的目标是需要在Label studio中能够访问到的图片源,请参考4.2节。
#!/bin/bash
#label-studio-converter import yolo -i /dataset/before_import -o output.json --image-root-url "/data/local
#-files/?d=dataset/before_import/images"
# the directory should be:
# /dataset/before_import
# /dataset/before_import/classes.txt
# /dataset/before_import/images
# /dataset/before_import/labels
label-studio-converter import yolo -i /git/dataset/moonpie/images -o output.json --image-root-url "/data/local
-files/?d=dataset/before_import/images"C:\Users\twica>label-studio-converter import yolo -i /dataset/before_import -o output.json --image-root-url "/data/local
-files/?d=dataset/before_import/images"
INFO:root:Reading YOLO notes and categories from C:\dataset\before_import
INFO:root:Found 81 categories
INFO:root:Converting labels from C:\dataset\before_import\labels
INFO:root:image extensions->, ['.jpg']
INFO:root:Saving Label Studio JSON to C:\Users\twica\output.json1. Create a new project in Label Studio
2. Use Labeling Config from "C:\Users\twica\output.label_config.xml"
3. Setup serving for images
E.g. you can use Local Storage (or others):
https://labelstud.io/guide/storage.html#Local-storage
See tutorial here:
https://github.com/HumanSignal/label-studio-converter/tree/master?tab=readme-ov-file#yolo-to-label-studio-converter4. Import "C:\Users\twica\output.json" to the project
4.导入
4.1 导入label-config
这个需要把output.label_config.xml,手工粘贴进来

4.2 设置工程的image src源
注意这里要设置为文件源,注意,我是把label_studio部署在windows系统的,这里的目录结构更明显。这里的源,只需要指向图片文件夹本身。

4.3 import
 4.4 导入后
4.4 导入后

5. 进阶 - 使用模型生成yolo标签,然后重新导入label-studio
最终的混合标注数据集:
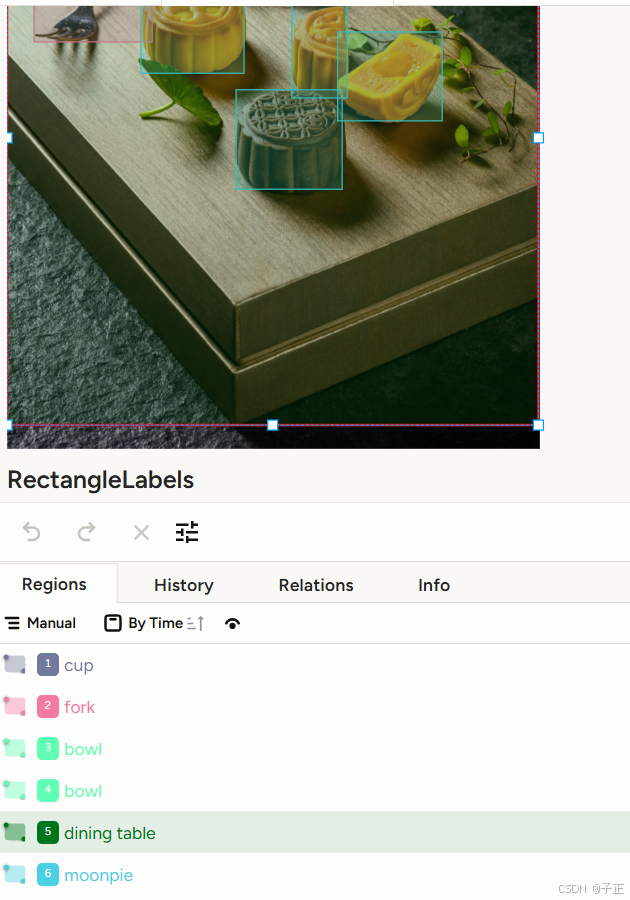
只描述一下工作量,不再附上代码:
- 使用yolo detect.py工具调用多个.pt工具进行标记(比如yolo11s.pt预训练模型),然后还有单独的特定物体的训练集的.pt模型。生成yolo格式的标记文件。
- 标记文件的classesid重新规划。modified and merge.
- 针对merge之后的yolo标记文件进行上述转换。merge的yolo标记文件示例:
附录A 混合标注yolo格式的label.txt
注意这里的标记实际是有问题的。如果只新增了一个待识别物体,它的classid应该是80,而不是81。一旦这里设置为81,则实际的classes.txt文件应该包含82行才对。82个classes.
devcontainers@LAPTOP-0BJBKJGQ:/git/dataset/moonpie/images/labels$ cat Cake9.txt
55 0.679134 0.346854 0.15093 0.196628
55 0.501391 0.58123 0.147194 0.195507
55 0.679892 0.574384 0.156641 0.193863
55 0.33148 0.357971 0.152468 0.196884
55 0.330766 0.574022 0.154556 0.191562
55 0.160202 0.576827 0.164656 0.196943
55 0.501387 0.351655 0.141083 0.205394
55 0.674795 0.149105 0.147664 0.207623
55 0.339976 0.154799 0.139387 0.197028
60 0.503871 0.503981 0.979967 0.983309
55 0.853498 0.350365 0.165343 0.19789
55 0.86647 0.570387 0.162402 0.193435
81 0.160803 0.576713 0.159472 0.196644
81 0.33004 0.573643 0.148516 0.189898
81 0.501294 0.580369 0.143412 0.191946
81 0.501001 0.351631 0.137057 0.201614
81 0.515014 0.850536 0.145317 0.219617
81 0.679284 0.346961 0.14827 0.190701
81 0.68753 0.849333 0.151887 0.223992
81 0.679555 0.573725 0.153101 0.193082
81 0.340212 0.153363 0.133932 0.19493
81 0.498815 0.147943 0.134052 0.195807
81 0.8381 0.140529 0.152241 0.199529
81 0.331765 0.357309 0.14806 0.193367
81 0.177596 0.15824 0.152942 0.196422
81 0.854053 0.351927 0.161736 0.1959
81 0.674657 0.147272 0.143009 0.203568
81 0.145352 0.832953 0.166784 0.213355
81 0.163286 0.359973 0.160709 0.191367
81 0.862673 0.569785 0.166771 0.191214
81 0.872219 0.855528 0.17271 0.221026
81 0.324842 0.84606 0.15045 0.223207


















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











