









1 大人,时代变了! 赶快把自有业务的本地AI“模型”训练起来!
1.1 背景
目前AI已经大行其道,chatGPT、DeepSeek等如雨后春笋般涌现出来,笔者做为一个守旧派和顽固派,一直认为AI只是雕虫小技,根本没有办法和人写的代码相提并论,在chatGPT已经大火几年之后仍然一直无动于衷,只是在最近才慢慢使用了豆包查点资料,然后再接触Kimi、DeepSeek等AI工具和模型。
使用AI的对话问答模式,相对原来的搜索引擎,得到的结果更精练, 不会像百度、必应之类的搜索引擎,搜索到结果后还要逐页去人工筛选,AI的回答就是干干净净你要的东西,这比搜索引擎效率高太多了!
提要求让AI生成些小的代码片段,如:“给我写一个vbs获取文件扩展名的函数”,生成的代码质量也非常不错,直接拿来就能用,连测试代码也一并写好!
总结一句话:大人,时代变了,现在投降是代价最小的时候!
问题来了:目前这些AI工具,都是基于通用模型, 如果用来做一些其他业务场景的事,效果就不会太好,此时就需要训练自己的本地模型了!
注意:在训练自己的本地模型前,请首先有一个概念,如果没有充足的硬件资源,请不要尝试在本地部署DeepSeek-R1模型,该模型至少需要60G的显存,GPU也是NVidia H100规格的,且是多卡分布式!
使用线上+线下协作的方式,可能是普通人训练自己业务场景的最优选择!
1.2 准备工作
-
注册硅基流动账号: 硅基流动注册
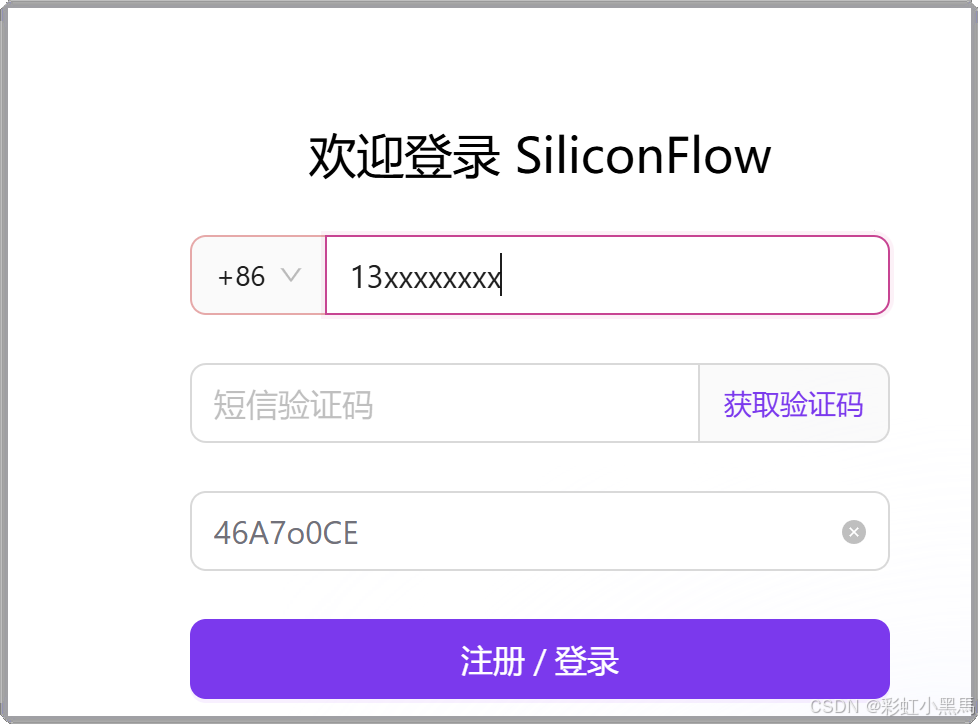
-
下载
CherryStudio:下载CherryStudio
注:目前常用的AI客户端只有CherryStudio工具的知识库支持训练本地素材
1.3 训练本地知识库
比如:作者偶尔会写点EverEdit的宏脚本(js语法),由于EverEdit有自己的API,所以AI必须先学习EverEdit的API。
1.3.1 在CherryStudio中配置密钥
配置密钥是为了能够让CherryStudio使用AI供应商(这里是硅基流动)的模型
-
步骤1:在
siliconflow网站登录后,拷贝自己的密钥,如下图所示:
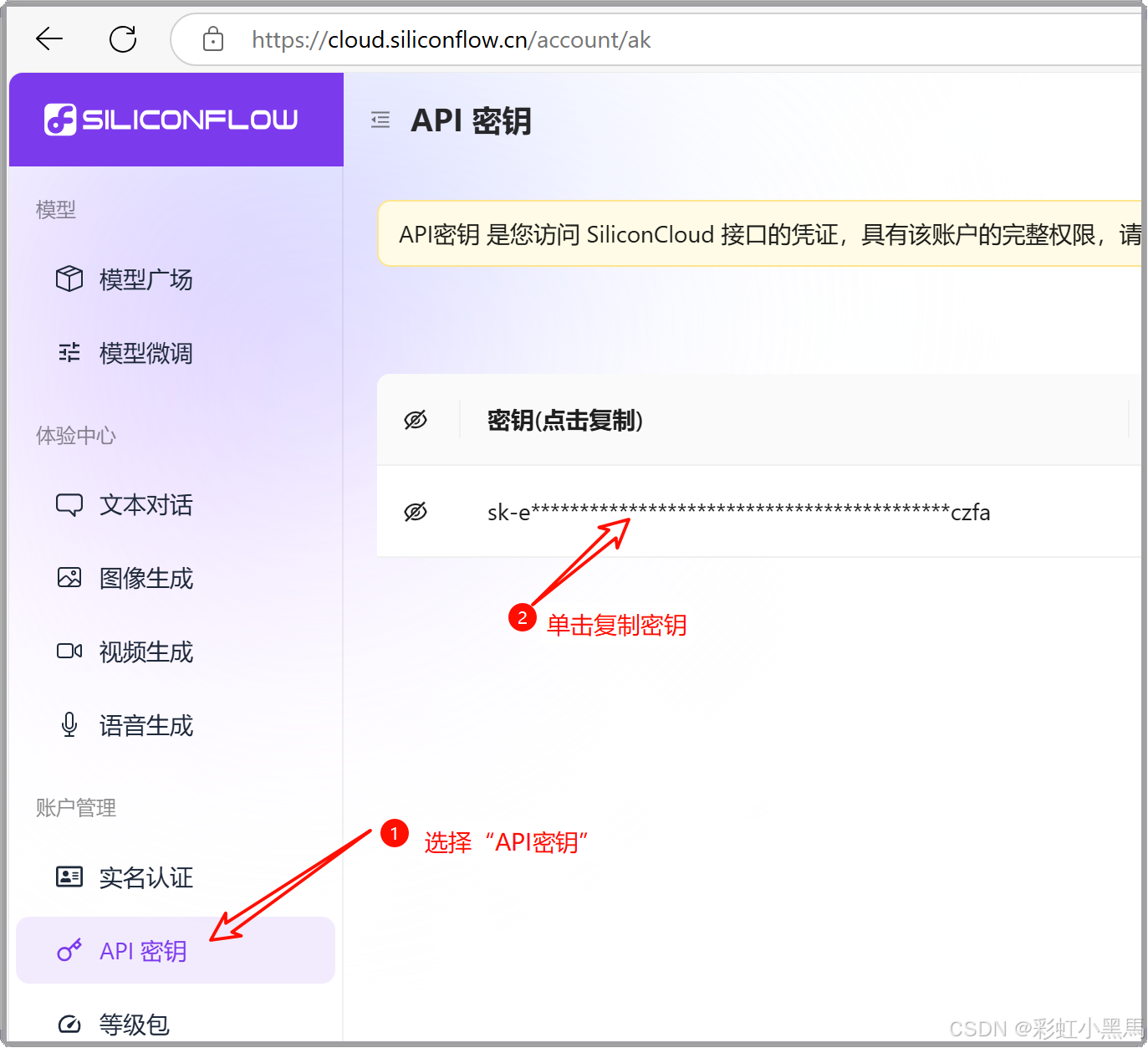
-
步骤2:在
CherryStudio中配置密钥,如下图所示:
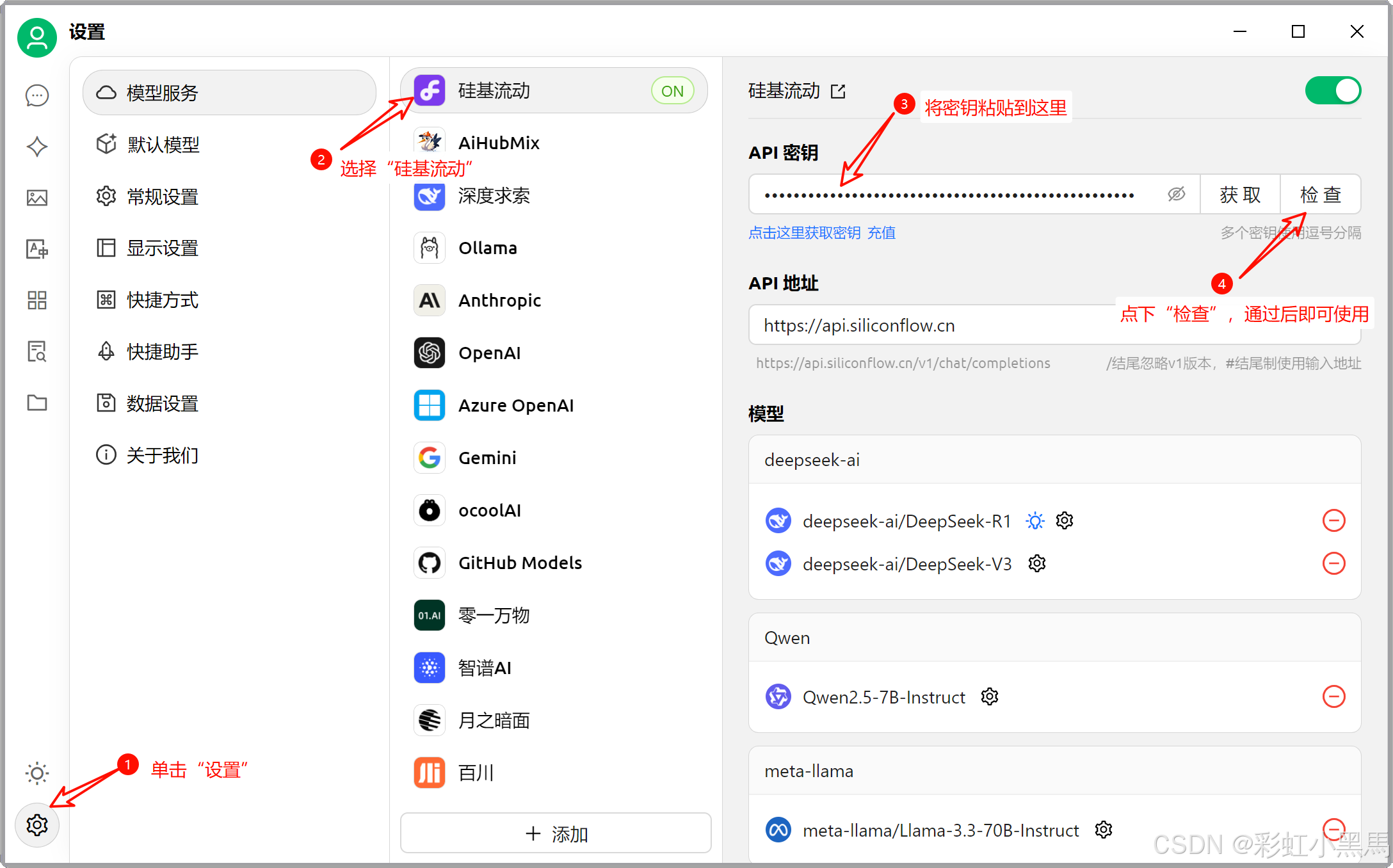
1.3.2 在CherryStudio中训练本地知识库
训练本地知识库的目的:将自有业务知识消化成知识库,结合在线AI(如:DeepSeek),以解答自有业务领域的问题,而避免投入大量硬件训练完整的专有本地模型。
比如:我偶尔要写EverEdit宏脚本,因此我要训练关于EverEdit的API的本地知识库。
-
在
CherryStudio中新建本地知识库,如下图所示:
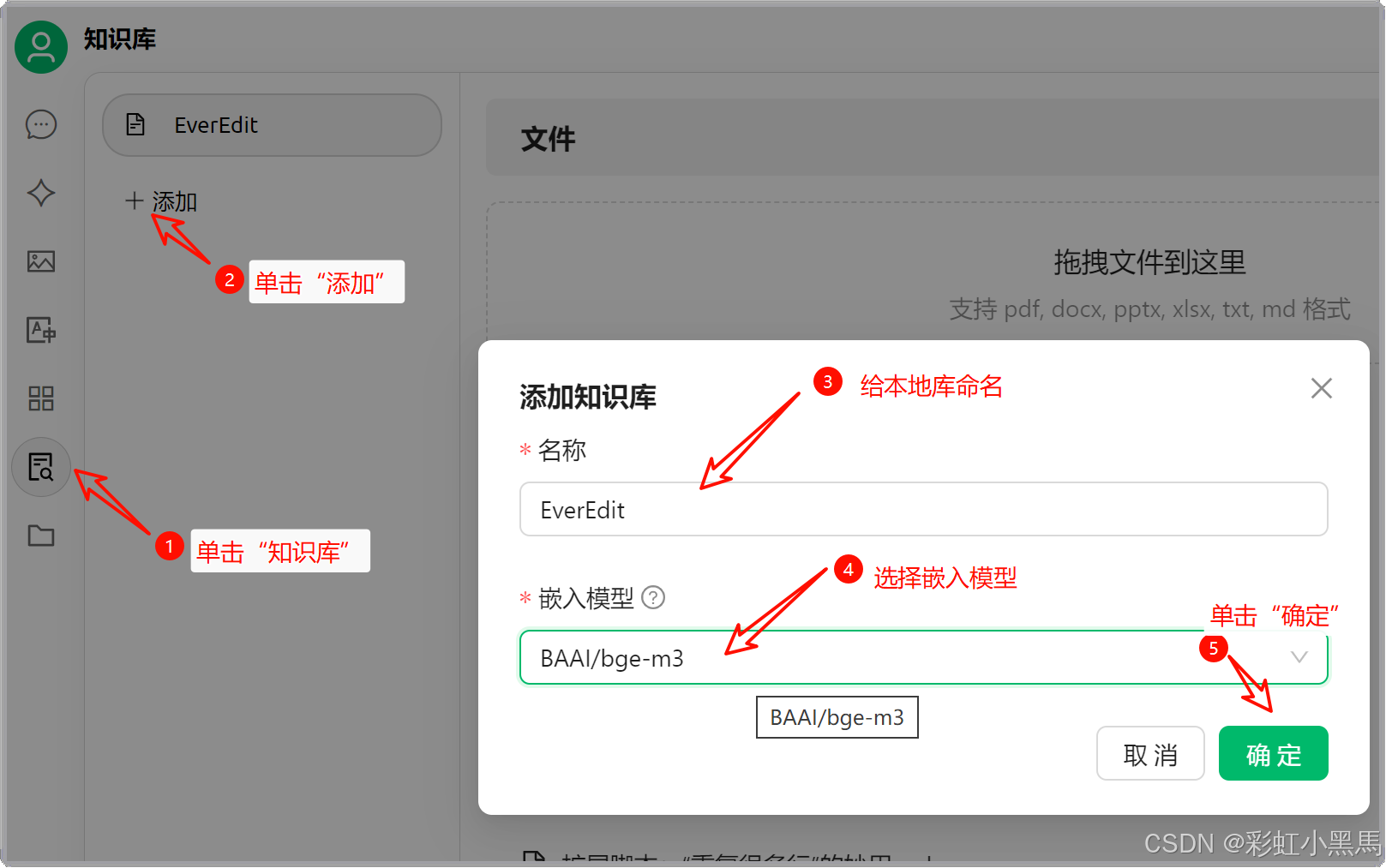
-
将自有业务相关的文档丢到
知识库中进行消化(近似动作),如下图所示:

消化完成后,会出现绿色的“√”符号
1.3.3 在CherryStudio中使用本地知识库(自有业务)和DeepSeek在线模型生成自有业务相关代码或答案
- 打开知识库开关,并选择本地知识库,如下图所示:
在CherryStudio的导航栏选择“助手”按钮,切换到助手模式
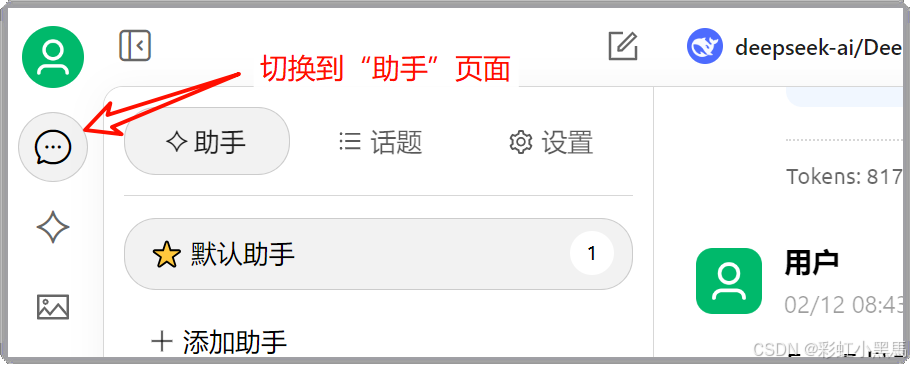
在界面的底部聊天窗口中选择本地知识库

-
提出问题并解答,如下图所示:
-
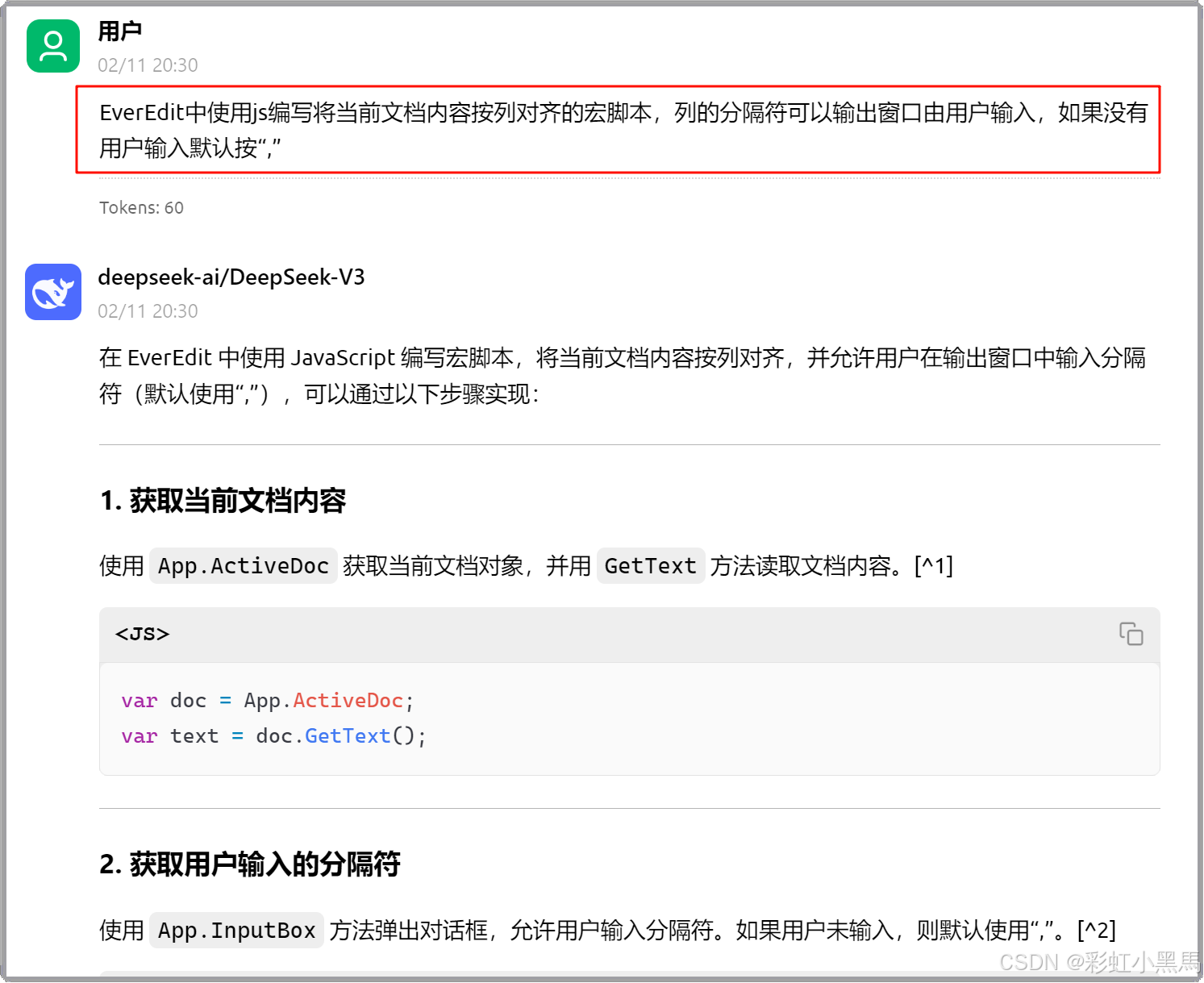
用户提出问题让AI解答
-
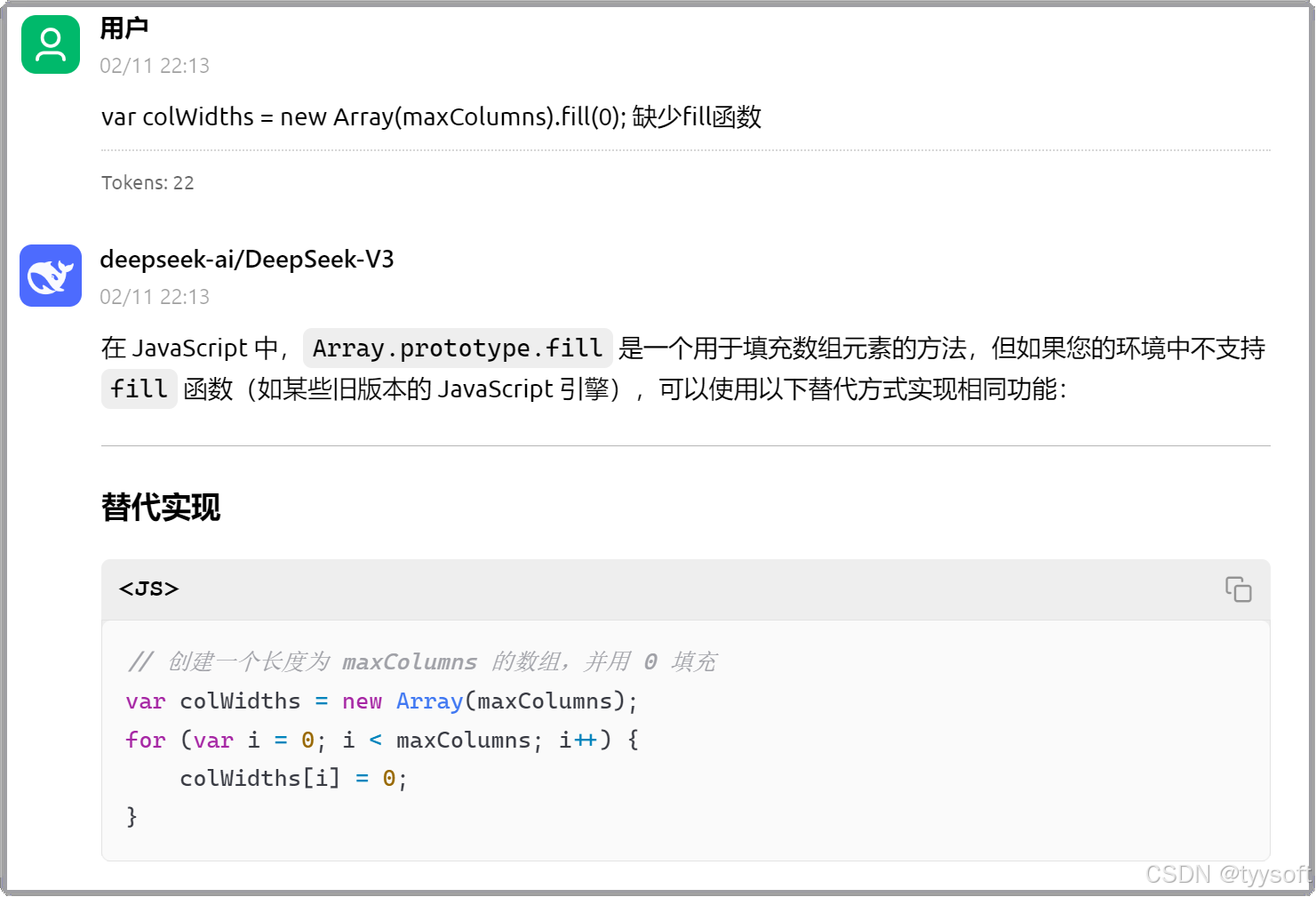
出现问题,让AI修正
-
还有问题,继续让AI修正
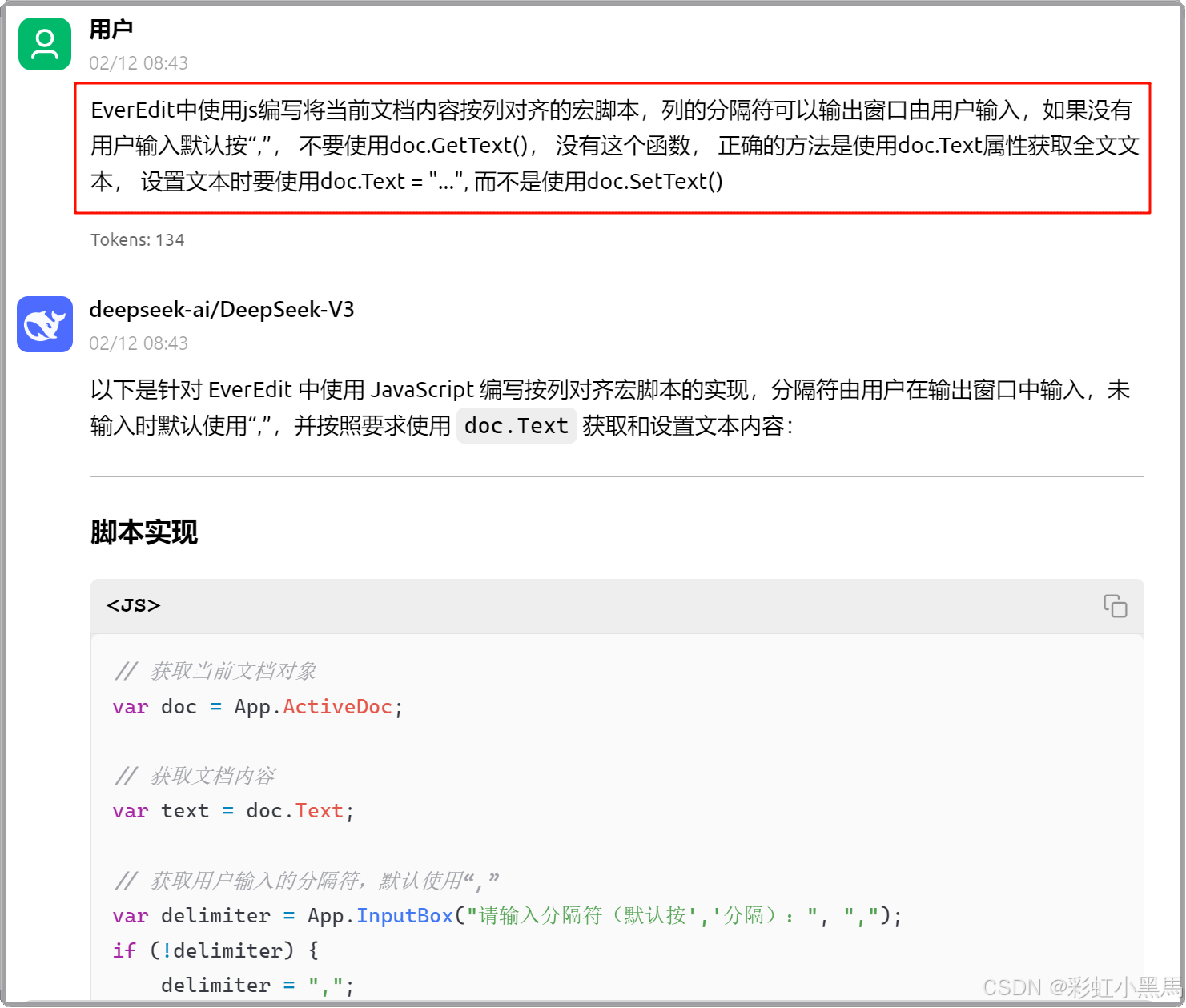
注:后面还有很多让AI修正的步骤,这里不一一列举。
4. 最终AI生成的代码// 获取当前文档对象 var doc = App.ActiveDoc; // 获取文档内容 var text = doc.Text; // 获取用户输入的分隔符,默认使用“,” var delimiter = App.ShowInputBox("请输入分隔符(默认按','分隔):", "分隔符输入"); if (!delimiter) { delimiter = ","; } // 获取制表符宽度 var tabWidth = doc.TabStop; // 按换行符拆分文档内容 var lines = text.split("\n"); var columns = []; for (var i = 0; i < lines.length; i++) { columns.push(lines[i].split(delimiter)); } // 计算字符串的显示宽度(中文字符占2,中文符号“和”占1,英文字符占1,Tab键按制表符宽度计算) function getDisplayWidth(str) { var width = 0; for (var i = 0; i < str.length; i++) { var char = str.charAt(i); // 使用 str.charAt(i) 获取字符 if (char === "\t") { // 计算 Tab 宽度,对齐到下一个制表符位置 [^1] width += tabWidth - (width % tabWidth); } else if (char === "“" || char === "”") { width += 1; // 中文符号“和”占1个宽度 } else { var charCode = str.charCodeAt(i); if (charCode >= 0 && charCode <= 127) { width += 1; // 英文字符或半角字符 } else { width += 2; // 中文字符或全角字符 } } } return width; } // 计算每列的最大显示宽度 var maxWidths = []; for (var i = 0; i < columns.length; i++) { for (var j = 0; j < columns[i].length; j++) { var width = getDisplayWidth(columns[i][j]); if (!maxWidths[j] || width > maxWidths[j]) { maxWidths[j] = width; } } } // 生成对齐后的文本(在分隔符后面多填充1个空格) var alignedText = ""; for (var i = 0; i < columns.length; i++) { for (var j = 0; j < columns[i].length; j++) { var cell = columns[i][j]; // 添加单元格内容 alignedText += cell; // 在分隔符后面填充空格(多填充1个空格) if (j < columns[i].length - 1) { var cellWidth = getDisplayWidth(cell); var padding = ""; for (var k = 0; k < maxWidths[j] - cellWidth; k++) { padding += " "; } alignedText += delimiter + " " + padding; // 分隔符后多填充1个空格 } } if (i < columns.length - 1) { alignedText += "\n"; } } // 将对齐后的内容写回文档 doc.Text = alignedText;- 脚本执行后的效果
对齐前:

脚本执行列对齐后:
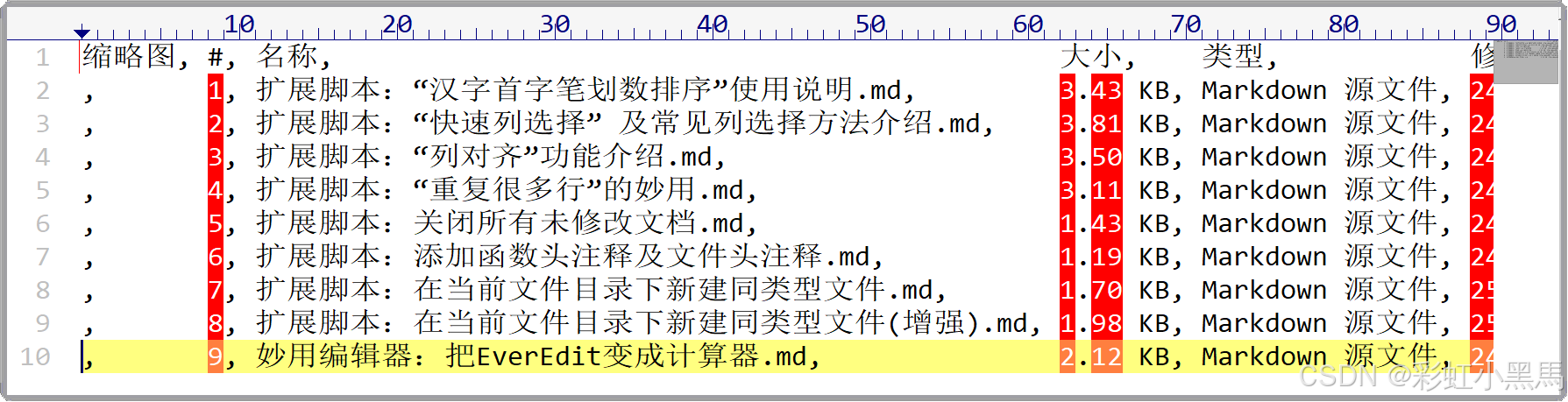
哇!是不是很整齐!这都是AI自己写的脚本哦!
-
作者声明:本文用于记录和分享作者的学习心得,可能有部分文字或示例来源自豆包AI,由于本人水平有限,难免存在表达错误,欢迎留言交流和指教!
Copyright © 2022~2025 All rights reserved.

















 1199
1199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









