









自编码器(AutoEncoder),也称自编码模型,是一种基于无监督学习的数据维度压缩和特征表示方法,目的是对一组数据学习出一种表示。1986年 Rumelhart 提出自编码模型用于高维复杂数据的降维。由于自动编码器通常应用于无监督学习,所以不需要对训练样本进行标记。自动编码器在图像重构、聚类、降维、自然语言翻译等方面应用广泛。
1. 数据表示
数据表示(Data Representation)是使用另一种形式呈现原始数据的方法,这一技术也被称为隐式表示(Latent Representation)或者转码(Coding)。
- 原始数据为
[
2
,
4
,
6
,
8
,
10
]
[2,4,6,8,10]
[2,4,6,8,10]:
我们可以使用文字以2开头,以10结尾的偶数列来表示该原始数据,也可以使用 [ x , 2 x , 3 x , 4 x , 5 x ] [x,2x,3x,4x,5x] [x,2x,3x,4x,5x] 且 x = 2 x=2 x=2 来表示该原始数据。 - 原始数据为
[
′
苹
果
′
,
′
梨
′
,
′
百香
果
′
]
['苹果','梨','百香果']
[′苹果′,′梨′,′百香果′]:
我们可以使用序列 [ 0 , 1 , 2 ] [0,1,2] [0,1,2] 来表示该原始数据,也可以使用水果这一概括性的词汇来表示原始数据。
很显然,一个数据的数据表示并不是唯一的,且这种表示可以是精确的、也可以是有些模糊的,甚至可以看起来与原始数据毫不相关,但无论如何,数据表示的结果必须携带原始数据上大部分的信息。广义地表示,只要数据B是以另一种形式呈现数据A、并且数据B上携带数据A大部分的信息,我们就可以说B是A的数据表示。同时,“另一种形式”既可以是文字-数字这样不同类别的数据之间的形式差异,也可以是数字-数字这样相同类别,但不同大小、不同数量的数据之间的形式差异。在实际计算当中,当数据B是数据A的数据表示时,数据B通常是从数据A总结出的规律、或直接在数据A上计算得出的新数据。
根据以上数据表示的广义定义可以得知,我们非常熟悉的数据编码(独热编码、顺序编码等操作)、特征提取、升维降维、Embedding等方法都可以囊括到数据表示领域当中。在这领域当中,使用机器学习或深度学习手段令算法自己求解出数据表示结果的领域被称之为表征学习。自编码器是表征学习中极具特色的代表架构。为了实现数据表示的功能,自编码器能够“接收数据A,并输出另一种形式的数据B”,因此自编码器是为“生产新数据”而生的架构。
2. 自编码器模型简介
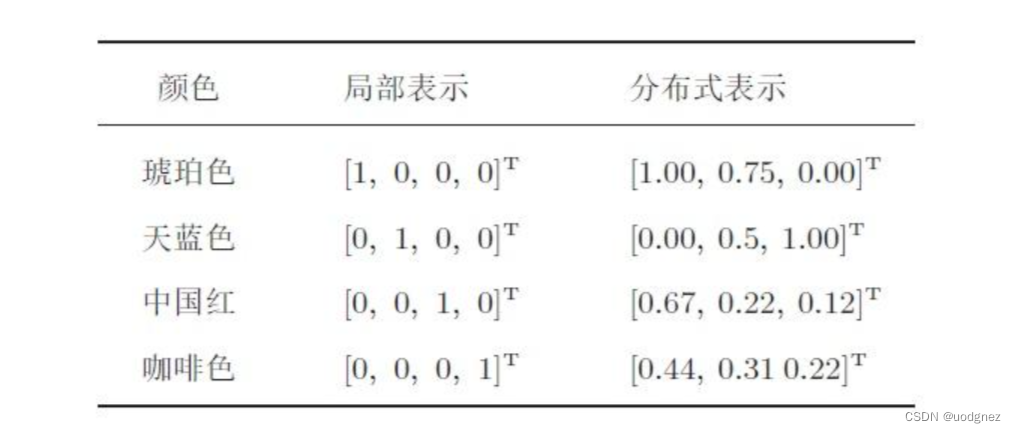
最初的自编码器是一个三层网络结构,即输入层、中间隐藏层以及输出层,其中输入层和输出层的神经元个数相同。如下图所示:
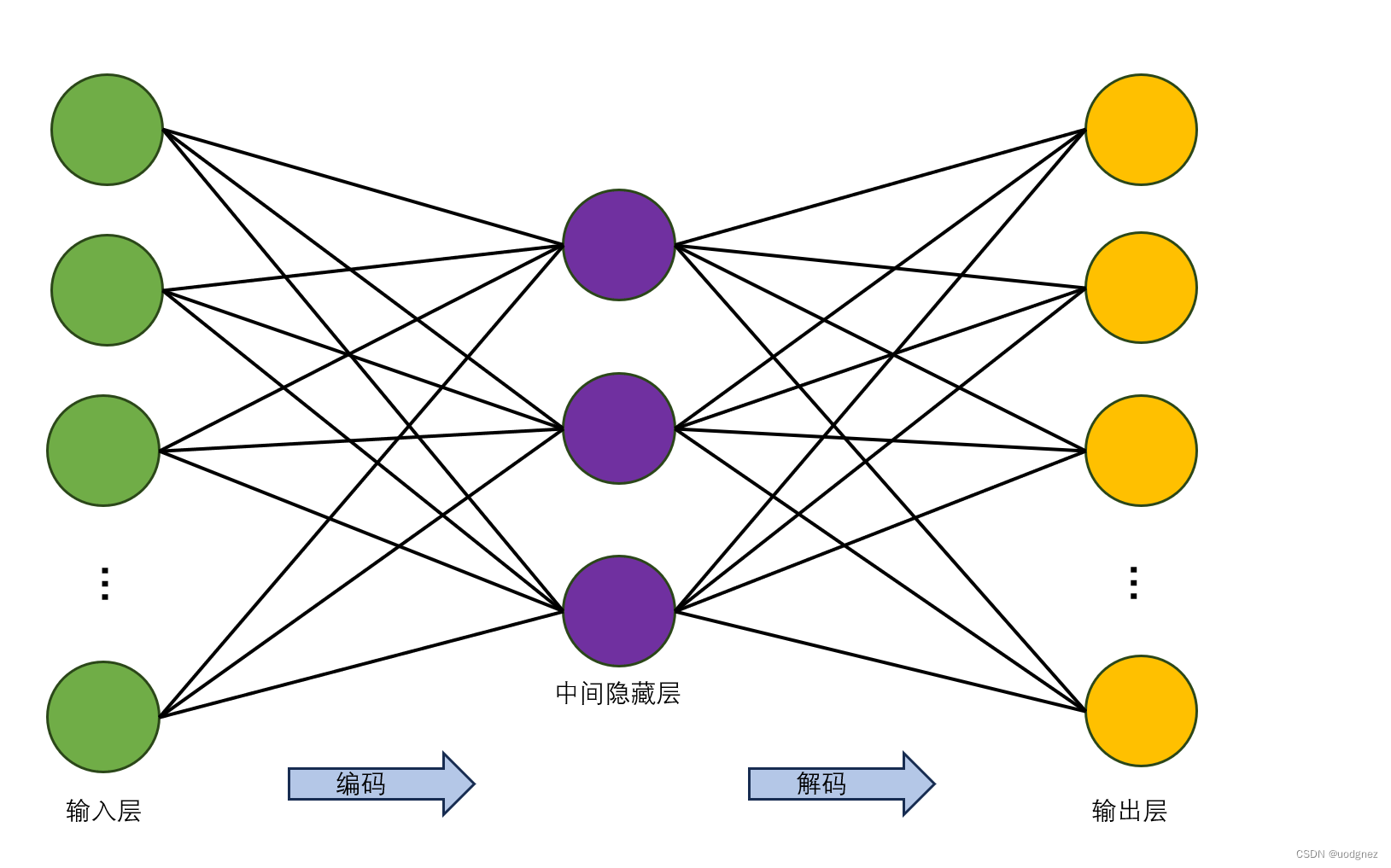
深度自编码器是将自编码器堆积起来,可以包含多个中间隐藏层。由于其可以有更多的中间隐藏层,所以对数据的表示和编码能力更强,而且在实际应用中也更加常用。如下图所示:

稀疏自编码器,是在原有自编码器的基础上,对隐层单元施加稀疏性约束,这样会得到对输入数据更加紧凑的表示,在网络中仅有小部分神经元会被激活。常用的稀疏约束是使用
L1
\text{L1}
L1 范数约束,目的是让不重要的神经元的权重为0。
卷积自编码器是使用卷积层搭建获得的自编码网络。当输入数据为图像时,由于卷积操作可以从图像数据中获取更丰富的信息,所以使用卷积层作为自编码器隐藏层,通常可以对图像数据进行更好的表示。在实际应用中,用于处理图像的自动编码器的隐藏层几乎都是基于卷积的自编码器。在卷积自编码器的编码器部分,通常可以通过池化层负责对数据进行下采样,卷积层负责对数据进行表示,而解码器则通常使用可以对特征映射进行上采样的操作来完成。
特性:
- 输出层的神经元数量往往与输入层的神经元数量一致;
- 网络架构往往呈对称性,且中间结构简单、两边结构复杂。
3. 基于线性层的自编码模型(降维和重构)
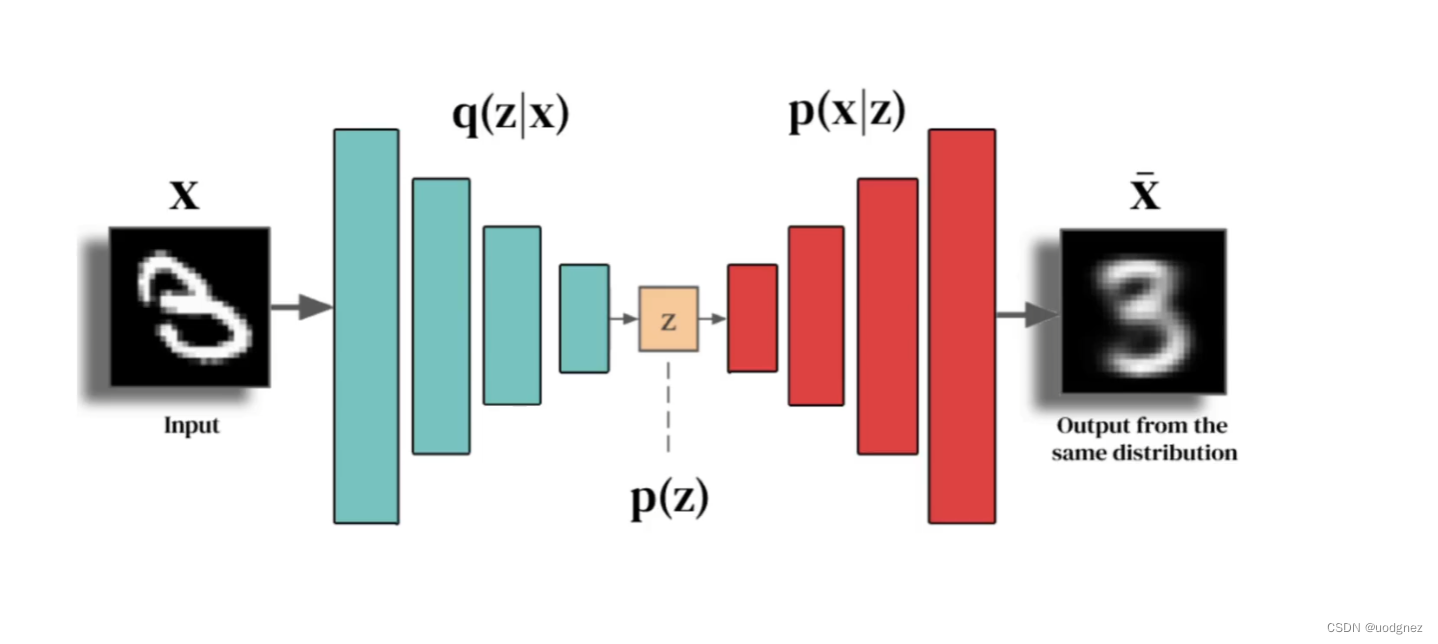
在进行编码的过程中,神经元的数量逐渐减少,主要是便于降维后数据分布情况的可视化,并分析手写字体经过编码后在空间的分布规律。在解码器中神经元的数量逐渐增加,会从特征编码中重构原始图像。
任务:
- 使用手写字体数据集,利用自编码模型对数据降维和重构;
- 使用编码降维后的数据特征+SVM分类器进行分类,将分类的结果和使用其他降维方法+SVM的预测结果进行比较
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
导入需要的包:
## 导入本章所需要的模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import hiddenlayer as hl
from sklearn.manifold import TSNE
from sklearn.svm import SVC
from sklearn.decomposition import PCA
from sklearn.metrics import classification_report,accuracy_score
import torch
from torch import nn
import torch.nn.functional as F
import torch.utils.data as Data
import torch.optim as optim
from torchvision import transforms
from torchvision.datasets import MNIST
from torchvision.utils import make_grid
数据准备:
## 使用手写体数据
## 准备训练数据集
train_data = MNIST(
root = "./data/MNIST", # 数据的路径
train = True, # 只使用训练数据集
transform = transforms.ToTensor(),
download= True # 第一次需下载
)
## 将图像数据转化为向量数据
train_data_x = train_data.data.type(torch.FloatTensor) / 255.0
train_data_x = train_data_x.reshape(train_data_x.shape[0],-1) # [nums,28*28]
train_data_y = train_data.targets
# train_data = Data.TensorDataset(train_data_x)
## 定义一个数据加载器
train_loader = Data.DataLoader(
dataset = train_data_x, ## 使用的数据集
batch_size = 64, # 批处理样本大小
shuffle = True, # 每次迭代前打乱数据
num_workers = 2, # 使用两个进程
)
## 对测试数据集进行导入
test_data = MNIST(
root = "./data/MNIST", # 数据的路径
train = False, # 使用测试数据集
transform = transforms.ToTensor(),
download= True
)
test_data_x = test_data.data.type(torch.FloatTensor) / 255.0
test_data_x = test_data_x.reshape(test_data_x.shape[0],-1)
test_data_y = test_data.targets
print("训练数据集:",train_data_x.shape)
print("测试数据集:",test_data_x.shape)
训练数据集: torch.Size([60000, 784])
测试数据集: torch.Size([10000, 784])
可视化部分图像数据
## 可视化一个batch的图像内容
## 获得一个batch的数据
for step, b_x in enumerate(train_loader):
if step > 0:
break
im = make_grid(b_x.reshape((-1,1,28,28)))
im = im.data.numpy().transpose((1,2,0))
plt.figure()
plt.imshow(im)
plt.axis("off")
plt.show()
搭建网络:
class EnDecoder(nn.Module):
def __init__(self):
super(EnDecoder,self).__init__()
## 定义Encoder
self.Encoder = nn.Sequential(
nn.Linear(784,512),
nn.Tanh(),
nn.Linear(512,256),
nn.Tanh(),
nn.Linear(256,128),
nn.Tanh(),
nn.Linear(128,3),
nn.Tanh(),
)
## 定义Decoder
self.Decoder = nn.Sequential(
nn.Linear(3,128),
nn.Tanh(),
nn.Linear(128,256),
nn.Tanh(),
nn.Linear(256,512),
nn.Tanh(),
nn.Linear(512,784),
nn.Sigmoid(),
)
## 定义网络的向前传播路径
def forward(self, x):
encoder = self.Encoder(x)
decoder = self.Decoder(encoder)
return encoder,decoder
## 输出我们的网络结构
edmodel = EnDecoder()
print(edmodel)
EnDecoder(
(Encoder): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): Tanh()
(2): Linear(in_features=512, out_features=256, bias=True)
(3): Tanh()
(4): Linear(in_features=256, out_features=128, bias=True)
(5): Tanh()
(6): Linear(in_features=128, out_features=3, bias=True)
(7): Tanh()
)
(Decoder): Sequential(
(0): Linear(in_features=3, out_features=128, bias=True)
(1): Tanh()
(2): Linear(in_features=128, out_features=256, bias=True)
(3): Tanh()
(4): Linear(in_features=256, out_features=512, bias=True)
(5): Tanh()
(6): Linear(in_features=512, out_features=784, bias=True)
(7): Sigmoid()
)
)
使用训练数据进行训练:
# 定义优化器
optimizer = torch.optim.Adam(edmodel.parameters(), lr=0.003)
loss_func = nn.MSELoss() # 损失函数
# 记录训练过程的指标
history1 = hl.History()
# 使用Canvas进行可视化
canvas1 = hl.Canvas()
train_num = 0
val_num = 0
## 对模型进行迭代训练,对所有的数据训练EPOCH轮
for epoch in range(10):
train_loss_epoch = 0
## 对训练数据的迭代器进行迭代计算
for step, b_x in enumerate(train_loader):
## 使用每个batch进行训练模型
_,output = edmodel(b_x) # 在训练batch上的输出
loss = loss_func(output, b_x) # 平方根误差
optimizer.zero_grad() # 每个迭代步的梯度初始化为0
loss.backward() # 损失的后向传播,计算梯度
optimizer.step() # 使用梯度进行优化
train_loss_epoch += loss.item() * b_x.size(0)
train_num = train_num + b_x.size(0)
## 计算一个epoch的损失
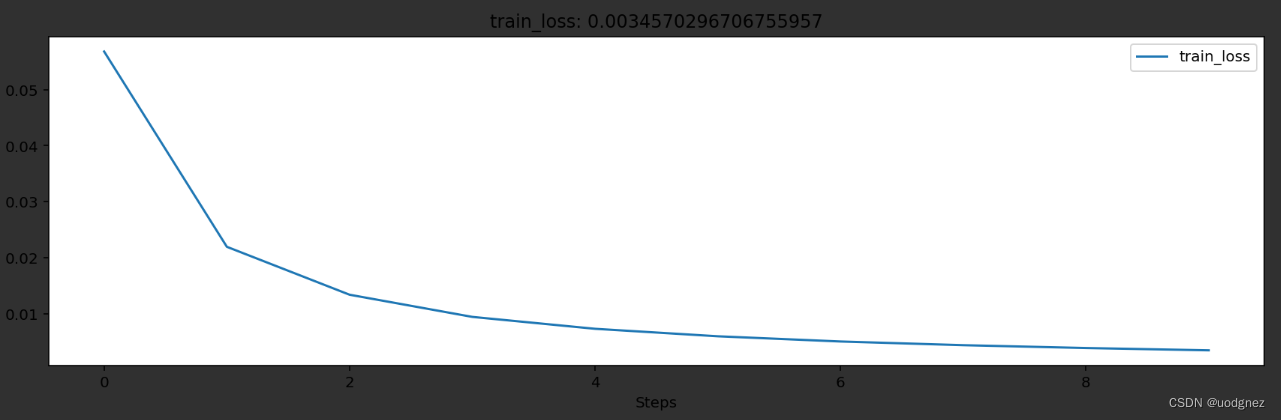
train_loss = train_loss_epoch / train_num
## 保存每个epoch上的输出loss
history1.log(epoch,train_loss=train_loss)
# 可视网络训练的过程
with canvas1:
canvas1.draw_plot(history1["train_loss"])
可视化部分测试集编码前后的图像:
## 预测测试集前100张图像的输出
edmodel.eval()
_,test_decoder = edmodel(test_data_x[0:100,:])
## 可视化原始后的图像
plt.figure(figsize=(6,6))
for ii in range(test_decoder.shape[0]):
plt.subplot(10,10,ii+1)
im = test_data_x[ii,:]
im = im.data.numpy().reshape(28,28)
plt.imshow(im,cmap=plt.cm.gray)
plt.axis("off")
plt.show()
## 可视化编码后的图像
plt.figure(figsize=(6,6))
for ii in range(test_decoder.shape[0]):
plt.subplot(10,10,ii+1)
im = test_decoder[ii,:]
im = im.data.numpy().reshape(28,28)
plt.imshow(im,cmap=plt.cm.gray)
plt.axis("off")
plt.show()

网络的编码特征可视化:
## 将3个纬度的特征进行可视化
edmodel.eval()
TEST_num = 500
test_encoder,_ = edmodel(test_data_x[0:TEST_num,:])
test_encoder_arr = test_encoder.data.numpy()
fig = plt.figure(figsize=(12,8))
ax1 = Axes3D(fig)
X = test_encoder_arr[:,0]
Y = test_encoder_arr[:,1]
Z = test_encoder_arr[:,2]
ax1.set_xlim([min(X),max(X)])
ax1.set_ylim([min(Y),max(Y)])
ax1.set_zlim([min(Z),max(Z)])
for ii in range(test_encoder.shape[0]):
text = test_data_y.data.numpy()[ii]
ax1.text(X[ii],Y[ii,],Z[ii],str(text),fontsize=8,
bbox=dict(boxstyle="round",facecolor=plt.cm.Set1(text), alpha=0.7))
plt.show()
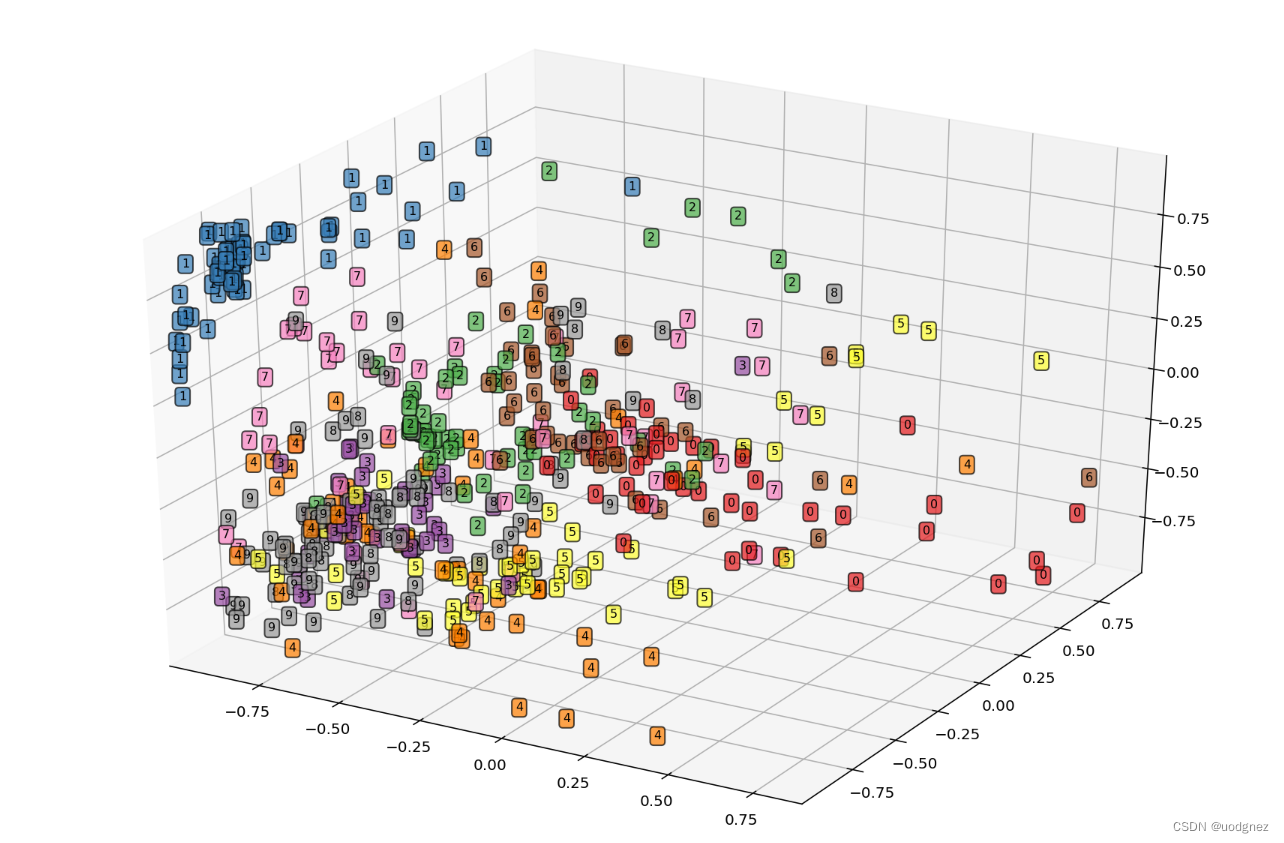
自编码后的特征+SVM VS PCA降维+SVM分类的效果对比:
## 自编码后的特征训练集和测试集
train_ed_x,_ = edmodel(train_data_x)
train_ed_x = train_ed_x.data.numpy()
train_y = train_data_y.data.numpy()
test_ed_x,_ = edmodel(test_data_x)
test_ed_x = test_ed_x.data.numpy()
test_y = test_data_y.data.numpy()
print(train_ed_x.shape)
print(train_y.shape)
(60000, 3)
(60000,)
## PCA降维获得的训练集和测试集前3个主成分
pcamodel = PCA(n_components=3,random_state=10)
train_pca_x= pcamodel.fit_transform(train_data_x.data.numpy())
test_pca_x = pcamodel.transform(test_data_x.data.numpy())
print(train_pca_x.shape)
(60000, 3)
## 使用自编码数据建立分类器,训练和预测
encodersvc = SVC(kernel="rbf",random_state=123)
encodersvc.fit(train_ed_x,train_y)
edsvc_pre = encodersvc.predict(test_ed_x)
print(classification_report(test_y,edsvc_pre))
print("模型精度",accuracy_score(test_y,edsvc_pre))
precision recall f1-score support
0 0.93 0.96 0.95 980
1 0.97 0.98 0.97 1135
2 0.88 0.87 0.87 1032
3 0.74 0.87 0.80 1010
4 0.75 0.70 0.72 982
5 0.86 0.73 0.79 892
6 0.92 0.91 0.92 958
7 0.93 0.85 0.89 1028
8 0.79 0.78 0.78 974
9 0.68 0.75 0.71 1009
avg / total 0.85 0.84 0.84 10000
模型精度 0.8421
## 使用PCA降维数据建立分类器,训练和预测
pcasvc = SVC(kernel="rbf",random_state=123)
pcasvc.fit(train_pca_x,train_y)
pcasvc_pre = pcasvc.predict(test_pca_x)
print(classification_report(test_y,pcasvc_pre))
print("模型精度",accuracy_score(test_y,pcasvc_pre))
precision recall f1-score support
0 0.68 0.74 0.71 980
1 0.93 0.95 0.94 1135
2 0.50 0.50 0.50 1032
3 0.65 0.66 0.65 1010
4 0.41 0.52 0.46 982
5 0.42 0.30 0.35 892
6 0.39 0.57 0.47 958
7 0.53 0.50 0.51 1028
8 0.40 0.27 0.32 974
9 0.43 0.33 0.37 1009
avg / total 0.54 0.54 0.54 10000
模型精度 0.5426
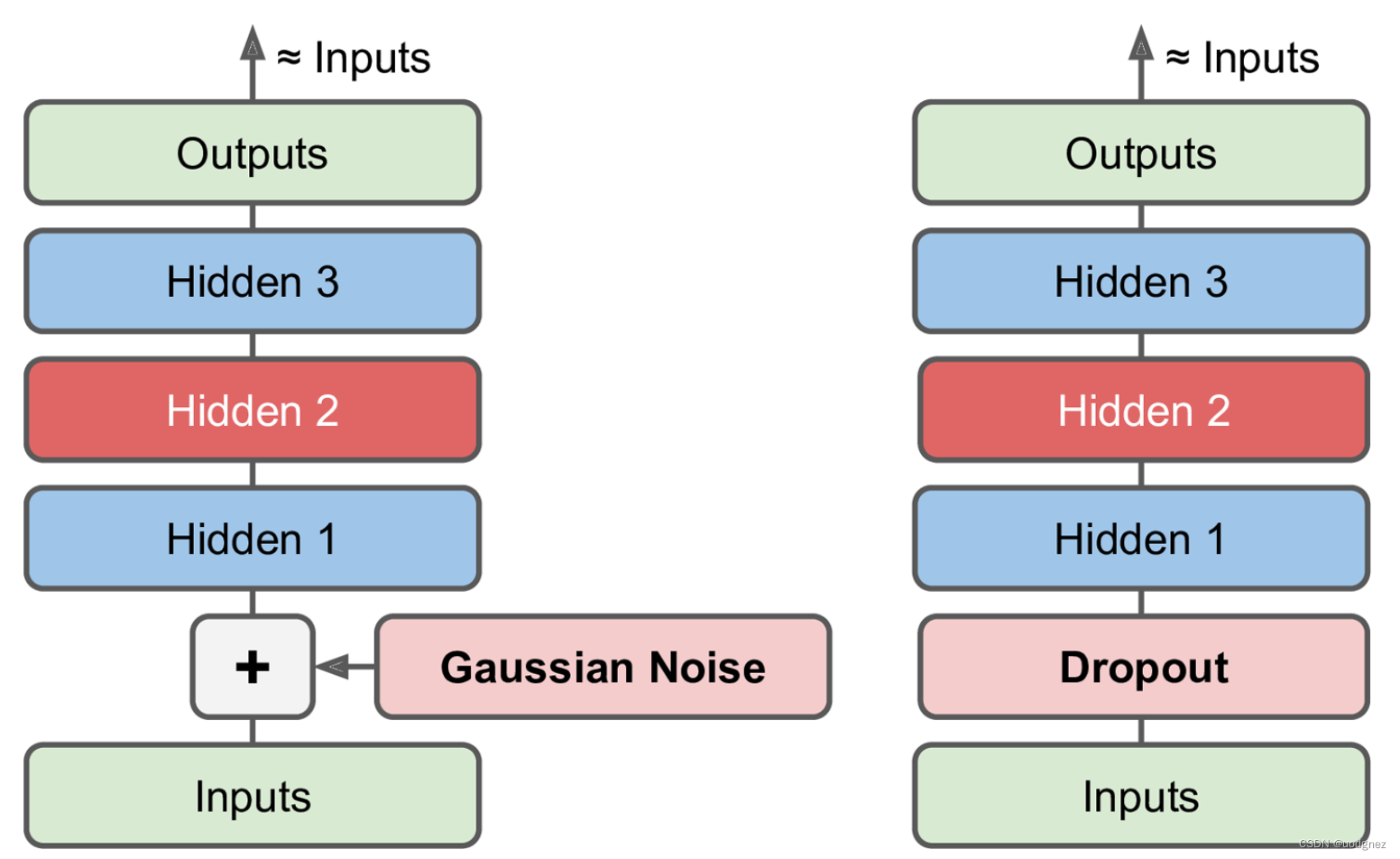
4. 去噪自编码器
基于卷积降噪自编码器的地震数据去噪(2020,石油地球物理勘探)
1.自编码器
对于无标签的输入数据,自编码器按以下方式重建输入数据:
H
=
ξ
θ
1
(
P
)
=
σ
(
W
1
P
+
b
1
)
Q
=
ξ
θ
2
(
H
)
=
σ
(
W
2
H
+
b
2
)
\begin{align} H=\xi_{\theta_1}(P)=\sigma(W_1P+b1) \tag{1} \\ Q=\xi_{\theta_2}(H)=\sigma(W_2H+b2) \tag{2} \end{align}
H=ξθ1(P)=σ(W1P+b1)Q=ξθ2(H)=σ(W2H+b2)(1)(2)
模型示意图:
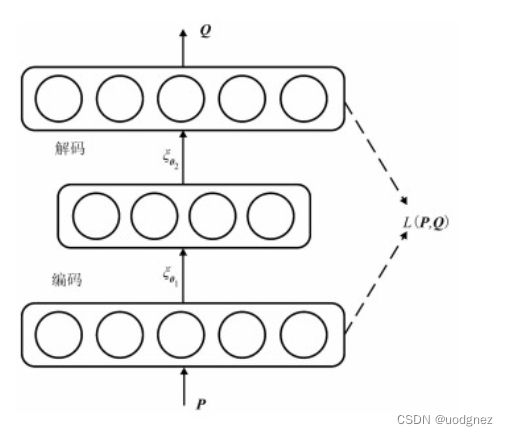
其中,
P
P
P、
H
H
H 和
Q
Q
Q 分别为输入数据、特征表达、输出数据;
σ
\sigma
σ 为 sigmoid 激活函数;
W
1
W_1
W1 与
b
1
b_1
b1 分别为输入层与隐藏层之间的权重矩阵与偏置;
W
2
W_2
W2 与
b
2
b_2
b2 分别为隐藏层与输出层之间的权重矩阵与偏置;
θ
1
=
[
W
1
,
b
1
]
\theta_1=[W_1,b_1]
θ1=[W1,b1] 和
θ
2
=
[
W
2
,
b
2
]
\theta_2=[W_2,b_2]
θ2=[W2,b2]分别为编码参数和解码参数;
ξ
θ
1
(
P
)
\xi_{\theta_1}(P)
ξθ1(P) 和
ξ
θ
2
(
H
)
\xi_{\theta_2}(H)
ξθ2(H) 分别为编码函数和解码函数。
模型训练的目的是为了优化模型参数
[
θ
1
,
θ
2
]
[\theta_1,\theta_2]
[θ1,θ2],使重建数据
Q
Q
Q 与输入数据
P
P
P 尽可能地接近,即:
[
θ
1
,
θ
2
]
=
arg
min
L
{
P
,
ξ
θ
2
[
ξ
θ
1
(
P
)
]
}
[\theta_1,\theta_2]=\arg \min L\{P,\xi_{\theta_2}[\xi_{\theta_1}(P)]\}
[θ1,θ2]=argminL{P,ξθ2[ξθ1(P)]}
L
(
∗
)
L(*)
L(∗) 表示
L
2
\text{L}2
L2范数。
- 降噪自编码器
降噪自编码器是自编码器的一个变体。与自编码器不同的是,降噪自编码器通过训练损坏的输入数据进行特征学习,其核心思想是提取数据的鲁棒性特征。
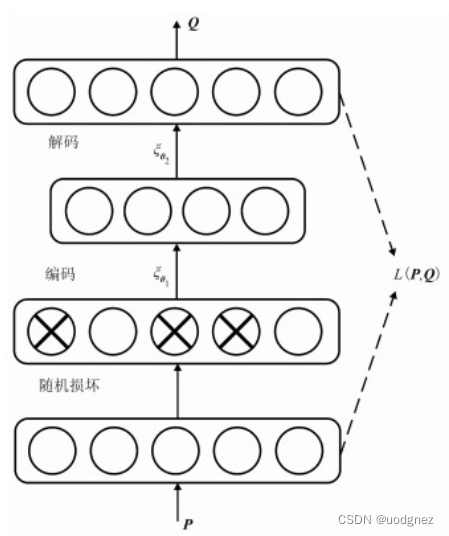
可以看出,降噪自编码器与自编码器对输入层的处理不同,降噪自编码器按照一定的概率将输入节点置0,如果这种损坏的概率为0,降噪自编码器就退化为自编码器。(或许参考了2010年的论文 Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion)
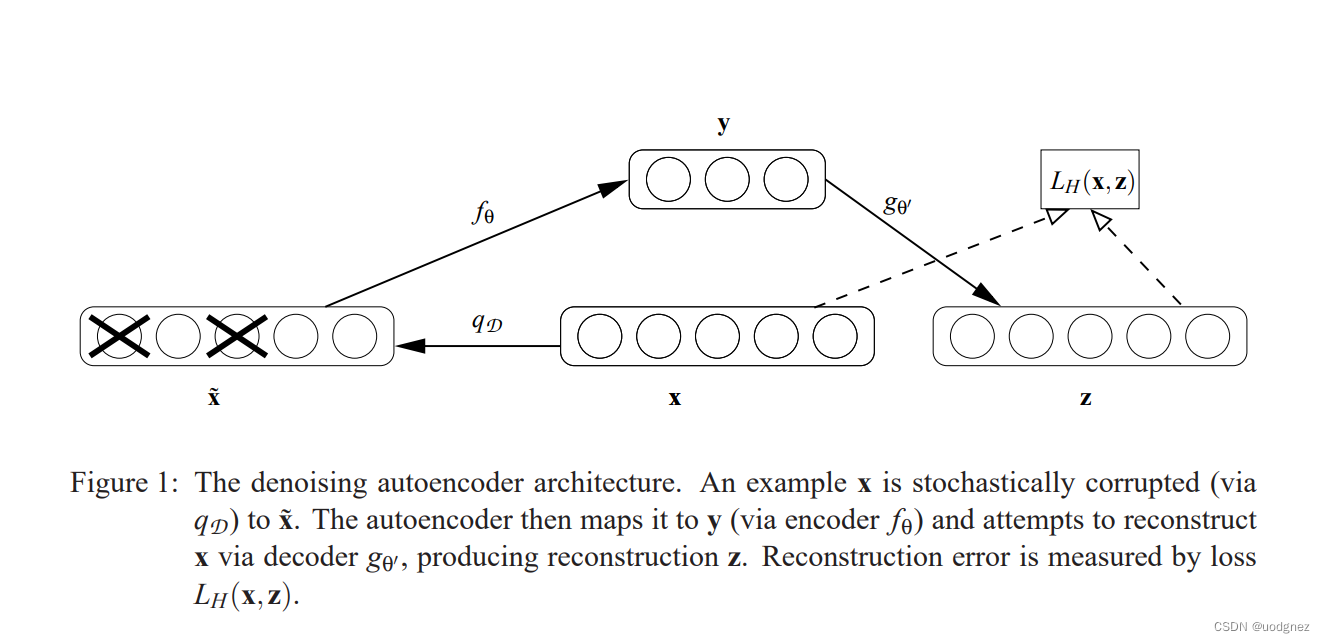
(1)(2)两种网络结构简单,层数只有3层,其中隐藏层单元数为64。
自编码器训练后得到的权重是杂乱的,含有大量噪声,而降噪自编码器训练后得到的权重含有明显的结构特征,噪声较弱(这两种自编码器的输入数据均来源于本文实验部分的合成数据,权重尺寸为48×48,降噪自编码器的损坏程度为60%)。
3.卷积降噪自编码器
使用3层卷积层和池化层作为编码框架,3层上采样层和卷积层作为解码框架。在编码框架中,卷积层作为特征提取层,用于捕捉地震数据波形特征,而池化层作为特征压缩层,一方面能够减小特征图的尺寸,降低网络计算量;另一方面能够提取重要的地震数据特征,有效降低噪声成分。本文将每层卷积层设置24个卷积核,卷积核的移动步长设置为1。因此,48×48×1的地震数据经过编码框架以后就被压缩为6×6×24的压缩特征表达。压缩特征表达保留了地震数据最重要的信息,但是丢失了大量细节信息。因此,解码框架承担着扩大特征图与恢复地震数据细节信息的任务。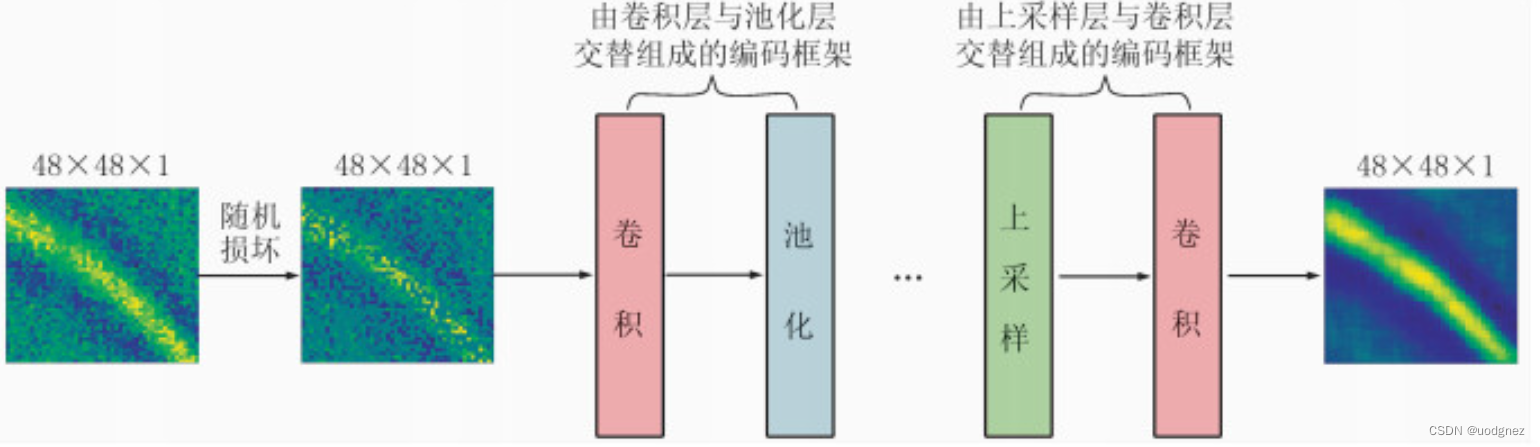
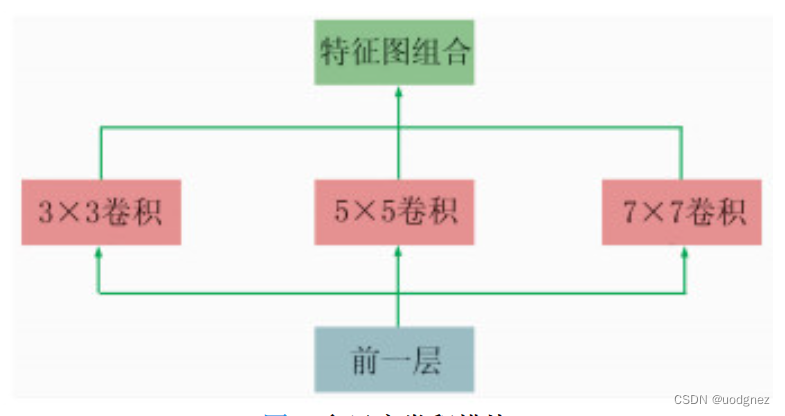
卷积为多尺度卷积:
实验结果:
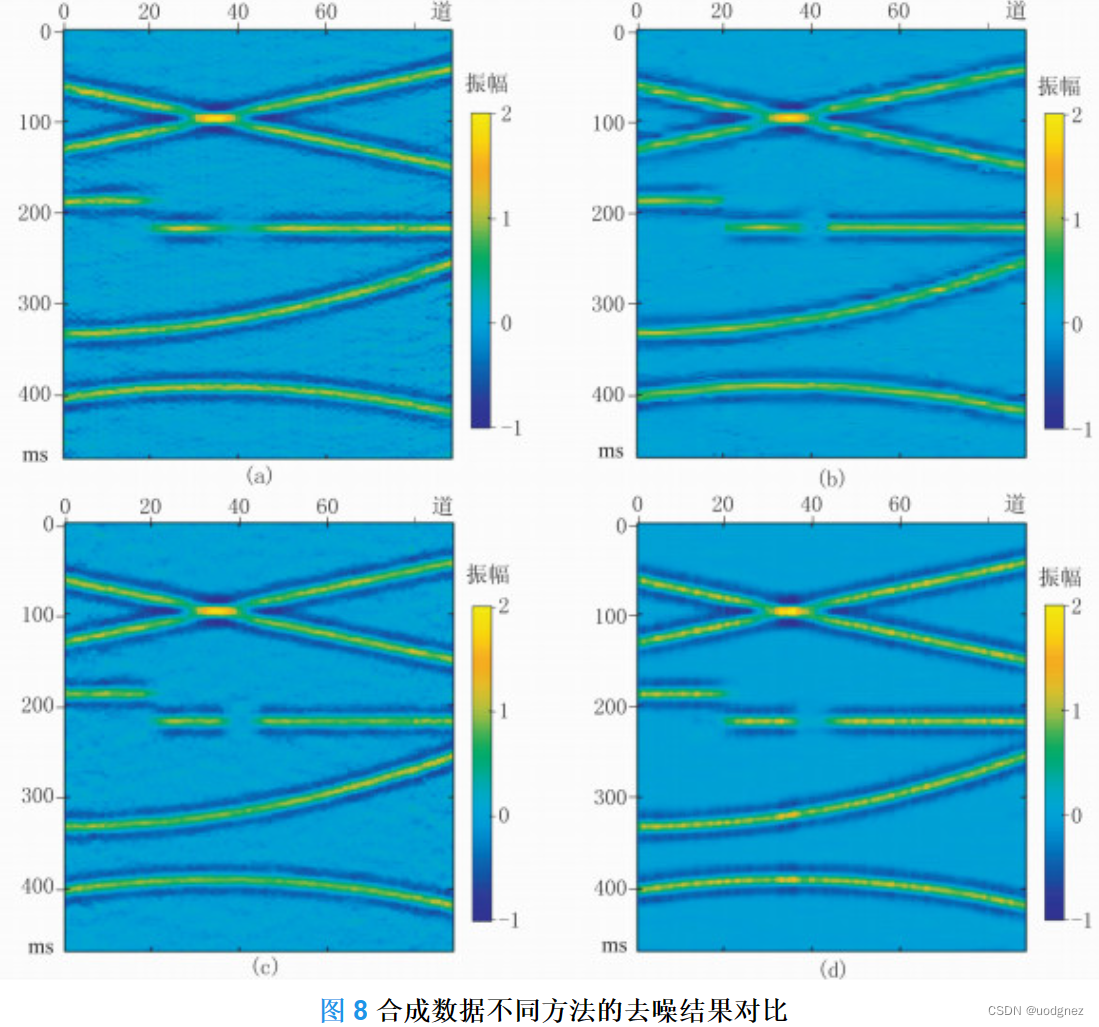
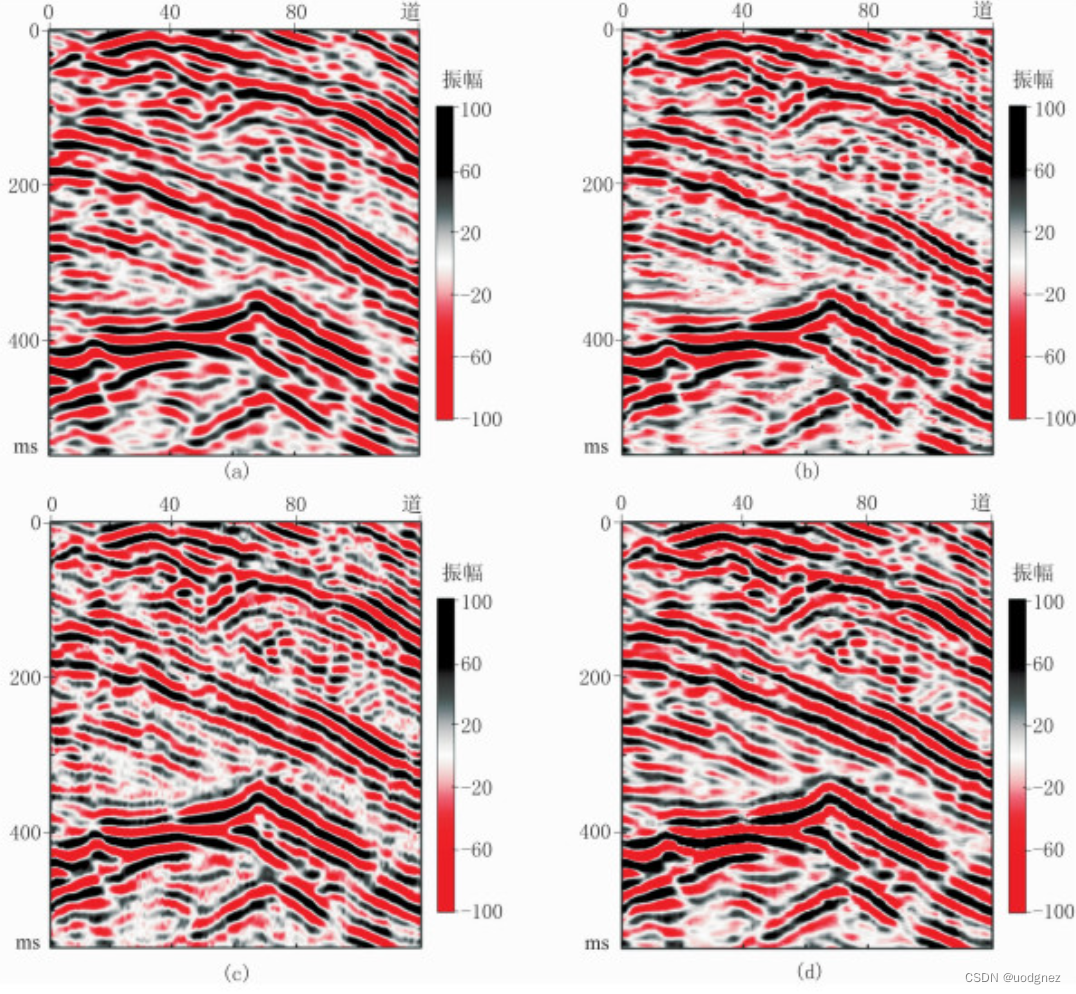















 2843
2843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









