









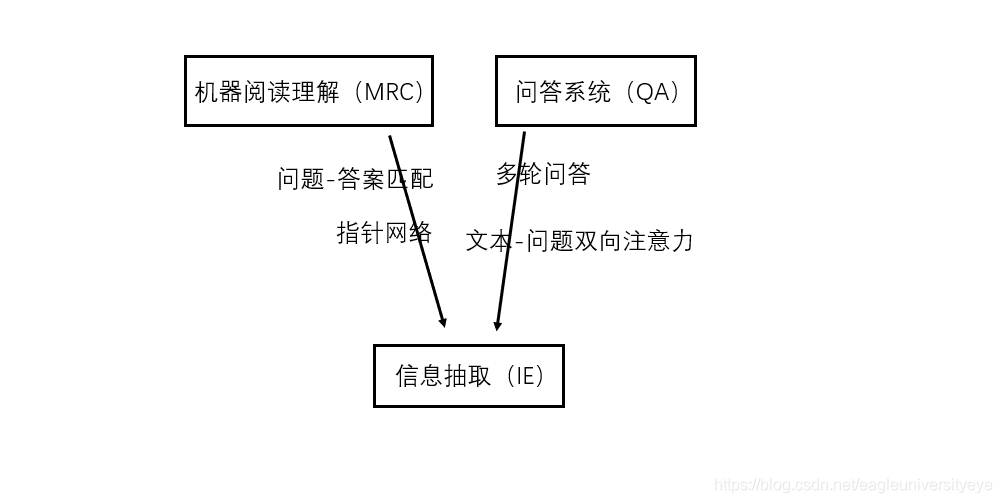
一 机器阅读理解(MRC)、问答系统(QA)与信息抽取
最近实体关系抽取任务和命名实体识别任务的SOTA模型排行榜中,有很多模型使用到了机器阅读理解(MRC)和问答系统(QA)中思想和方法,如HBT、ETL-span、Multi-turn QA和BERT_MRC等,MRC和QA中的思想和方法的使用,让这些模型相比于传统方法有很大提升。
在实体关系抽取任务中,最新的一些模型,如HBT和ETL-span,用到了MRC中经常使用的指针网络方法,通过多层标注序列解决实体重叠问题;Multi-turn QA则使用了问答系统的思想,通过问答的形式一步一步抽取出主体、客体和关系,这些模型在多个数据集上都达到了SOTA效果。相比于传统的使用LSTM+CRF抽取特征做序列标注,这些借鉴了MRC和QA技术的模型,无论是在抽取结果的准确性还是对重叠实体关系的召回率方面,都有大幅度的提升。
而在命名实体识别任务中,也有像BERT_MRC这样的模型,同时融合了MRC和QA领域的诸多思想方法,在多个数据集上达到了SOTA效果。
本文以信息抽取为核心,主要探讨一下MRC和QA中经常使用到的思想方法在信息抽取任务(包括实体关系抽取和命名实体识别)中的应用。
二 MRC概述
在分析MRC和QA在IE中的应用之前,先对MRC做一个简单的概述,由于我对QA了解的不多,就不详细介绍QA了,只分析一下QA中的一些方法是怎么应用到信息抽取中的。
MRC概述
Neural Machine Reading Comprehension: Methods and Trends是一篇MRC领域的综述论文,这篇论文对MRC领域的任务目标,使用到的各种方法和思想和发展前景做了非常详细的描述。这里摘取其中一部分对MRC做一个简要的介绍,如果想对MRC有更深入的了解,推荐先去认真阅读一下这篇论文。
1 MRC的发展历程
MRC的任务是让机器根据给定的内容回答问题。在1970年代MRC就已经被提出,但是,由于那时的数据集规模都比较小,而且主要使用基于规则的方法,所以性能很差,难以投入实用。这一情况在深度学习方法投入使用之后有了改观。基于深度学习方法的机器阅读理解,称为神经机器阅读理解,目前正在迅速发展。
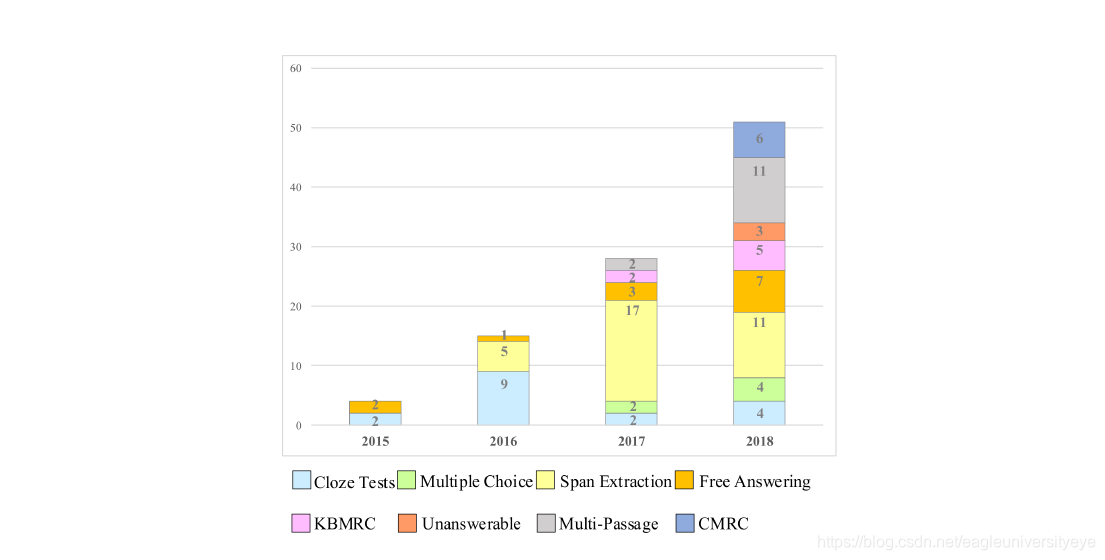
上图是2015年-2018年期间,和MRC领域的各个细分任务相关的论文数量,可以看出,最近几年MRC领域的论文数呈几何级数式增长,这一领域正在迅速发展。
2 任务&评测标准
MRC的任务根据答案形式可以分为四类:完形填空、多项选择、片段抽取、自由作答
给定上下文 C C C ,一个词或实体 a ( a ∈ C ) a(a∈C) a(a∈C) 被移除,完形填空任务要求模型使用正确的词或实体进行填空,最大化条件概率 P ( a ∣ C − { a } ) P(a|C-\{a\}) P(a∣C−{a})。

给定上下文 C C C,问题 Q Q Q,候选答案列表 A = { a 1 , a 2 . . . , a n } A=\{a_1,a_2...,a_n\} A={a1,a2...,an},多项选择任务要求模型从A中选择正确的答案 a i a_i ai,最大化条件概率 P ( a i ∣ C , Q , A ) P(a_i|C,Q,A) P(ai∣C,Q,A)。与完形填空任务的区别就是答案不再局限于单词或实体,并且候选答案列表是必须要提供的。

尽管完形填空和多项选择一定程度上可以机器阅读理解的能力,但是这两个任务有一定的局限性。首先,单词或实体可能不足以回答问题,需要完整的句子进行回答;其次,在很多情形是没有提供候选答案的。所以片段抽取任务应运而生。
给定上下文 C C C 和问题 Q Q Q ,其中 C = { t 1 , t 2 . . . , t n } C=\{t_1,t_2...,t_n\} C={t1,t2...,tn} ,片段抽取任务要求模型从 C C C中抽取连续的子序列 a = { a 1 , a 2 . . . , a n } ( 1 ≤ i ≤ i + k ≤ n ) a=\{a_1,a_2...,a_n\}(1≤i≤i+k≤n) a={a1,a2...,an}(1≤i≤i+k≤n) 作为正确答案,最大化条件概率 P ( a ∣ C , Q ) P(a|C,Q) P(a∣C,Q) 。

对于答案局限于一段上下文是不现实的,为了回答问题,机器需要在多个上下文中进行推理并总结答案。自由回答任务是四个任务中最复杂的,也更适合现实的应用场景。
给定上下文 C C C 和问题 Q Q Q,在自由回答任务中正确答案可能不是 C C C中的一个子序列, 或
,自由回答任务需要预测正确答案 a a a,并且最大化条件概率 P ( a ∣ C , Q ) P(a|C,Q) P(a∣C,Q)。

在五个维度上对上述四个任务进行比较:建立数据集难易程度、理解及推理程度、答案形式复杂程度、进行评估的难易程度、真实应用程度(construction, understanding, flexibility, evaluation and application)
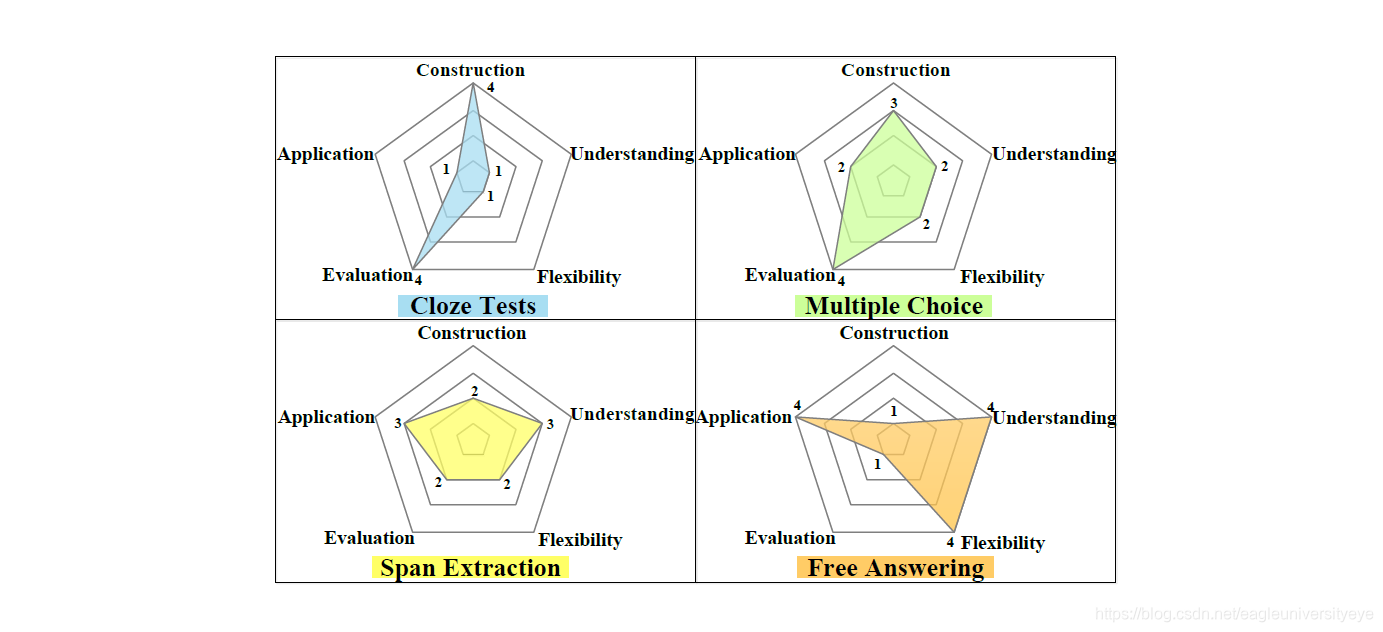
通过上图可以看出:完形填空任务容易构建数据集,容易评估,但是答案被单个单词或者实体限制,理解程度不高,和真实世界不符;多项选择任务容易评估,建立数据集不是很难,但是合成数据集和实际应用之间有差距;片段抽取任务是一个适中的选择,数据集容易建立,容易评估,但是答案被原始文本的片段限制,仍和真实世界有差距。自由作答任务最接近真实情况,理解程度最高,但是难以建立数据集,难以有效评估,是现阶段最具的挑战性的任务。
上述四个任务类型中,片段抽取和信息抽取的关系最为紧密,命名实体识别和实体关系抽取任务都是识别文本中的片段。
主要的评测标准有常见的准确率P、召回率R和F1值,在上述四个任务的前三个中,使用P、R、F1可以满足要求。但是,自由作答在评测时使用P、R、F1则不太合适,自由作答需要使用用于自动文摘评测的方法ROUGE和ROUGE-L,以及用于评价翻译性能的BLEU。
3 MRC模型的结构
在实体关系抽取中,模型可以分为pipline结构和joint结构。在MRC中,模型也有统一的结构类型,如下图所示:
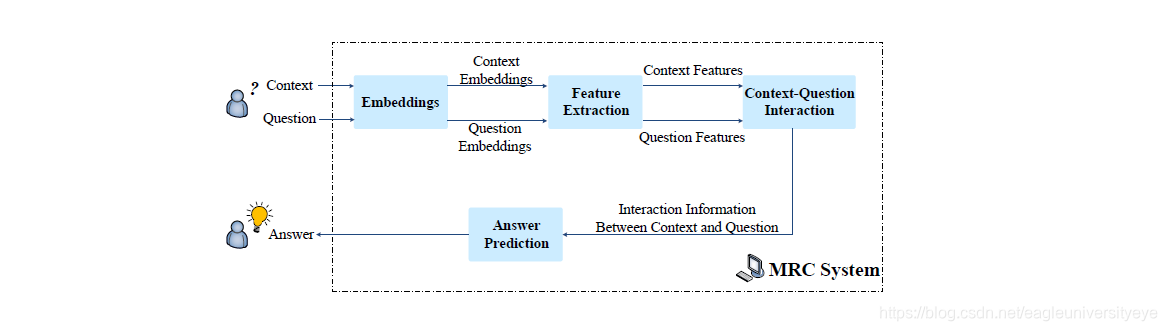
模型包含四个关键模块:Embeddings, Feature Extraction, Context-Question Interaction,Answer Prediction。
- Embeddings: 将单词映射为对应的词向量,可能还会加上POS、NER、question category等信息;
- Feature Extraction: 特征抽取层,抽取question和context的上下文信息,常用的有CNN、RNN、LSTM等;
- Context-Question Interaction: context和question之间的相关性在预测答案中起着重要作用。有了这些信息,机器就能够找出context中哪些部分对回答question更为重要。为了实现该目标,在该模块中广泛使用attention机制,单向或双向,以强调与query相关的context的部分。为了充分提取它们的相关性,context和question之间的相互作用有时会执行多跳,这模拟了人类理解的重读过程。
- Answer Prediction: 基于上述模块获得的信息整理后得出最终答案。因为MRC任务根据答案形式分为了很多种,所以该模块与不同任务相关。对于完形填空,该模块输出context中的一个单词或一个实体;对于多项选择,该模块从候选答案中选择正确答案。
4 常用方法
提取出上下文和问题之间的关联后,模型就能找到答案预测的证据。根据模型如何提取问题和答案之间的关系,可以将现在的方法分为两类:单跳交互、多跳交互。不论MRC模型使用哪种交互,在强调哪部分文本对于预测答案更重要方面,注意力机制扮演了重要角色。注意力机制根据是否被单向/双向使用分为两类:单项注意力、双向注意力。
单向注意力流通常是从查询到文本的 S i = f ( P i , Q ) S_i=f(P_i,Q) Si=f(Pi,Q) ,根据问题强调文中最相关的部分。如果某个文本词语和问题更相似,那它更有可能是答案词语。相似度计算:
注意力权重: a i = e x p S i ∑ i e x p S i a_i= \frac {expS_i} {\sum_iexpS_i} ai=∑iexpSiexpSi
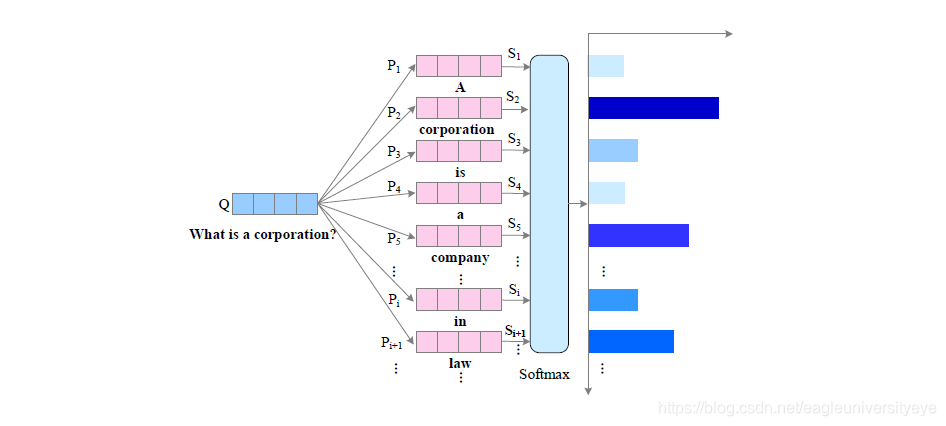
单向注意力将问题句子编码成了一个特征向量,无法将注意力放在问题中的词语,这些词语对答案预测也很关键,因此单向注意力流在提取文本和查询之间的相互信息方面有不足。
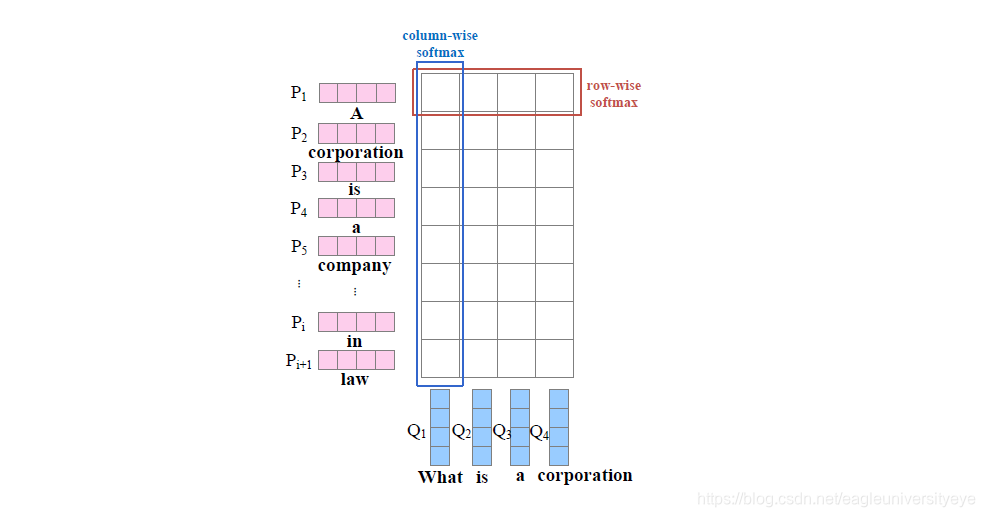
为了解决单向注意力的缺点,双向注意力不仅计算“查询-文本”注意力,也计算“文本-查询”注意力,双向查看,为双方提供互补的信息。
三 MRC和QA在信息抽取中的应用
这一部分详细的介绍一下命名实体识别和实体关系抽取中的几个SOTA模型,重点分析一下MRC和QA中的思想和方法在这几个模型中的使用,以及新的思想方法相比于信息抽取领域中传统的序列标注方法具体有哪些优势。
| 模型 | 任务领域 | 主要思想方法 | 论文 |
|---|---|---|---|
| BERT_MRC | 命名实体识别 | MRC片段抽取(问题+指针网络) | A Unified MRC Framework for Named Entity Recognition |
| Multi-turn QA | 实体关系抽取 | 多轮对话+指针网络 | Entity-Relation Extraction as Multi-turn Question Answering |
| HBT | 实体关系抽取 | 指针网络 | A Novel Hierarchical Binary Tagging Framework for Joint Extraction of Entities and Relations |
| ETL-span | 实体关系抽取 | 指针网络 | Joint Extraction of Entities and Relations Based ona Novel Decomposition Strategy |
BERT_MRC
目前大多数命名实体识别模型都是针对的“非嵌套型”的NER(Flat NER),然而在实际场景中,“嵌套型”的NER(Nested NER)占了相当的比例。
BERT_MRC受到近来机器阅读理解问答(MRC-QA)的启发,使用机器阅读理解框架去合并处理Flat NER与Nested NER。比如,现在想要抽取PER类型的实体,那么就提出一个问题 “Which person is mentioned in the text” ,然后在文本中找答案,找到的答案就是PER类型的实体。使用这种方法,无论是Flat NER还是Nested NER,都能很直观地抽取出来。
BERT_MRC模型的创新点有:
-
基于MRC的方法抽取命名实体,该方法适用于Flat和Nested两种类型的NER。相比序列标注方法,该方法简单直观,可迁移性强。
-
通过实验表明,基于MRC的方法能够让问题编码一些先验语义知识,从而能够在小数据集下、迁移学习下表现更好。
先来回顾一下NER任务。给定一个文本序列X,它的长度为n,要抽取出其中的每个实体,其中实体都属于一种实体类型。假设该数据集的所有实体标签集合为Y,那么对其中的每个实体标签y,比如地点LOC,都有一个关于它的问题 q ( y ) q(y) q(y)。这个问题可以是一个词,也可以是一句话等等。使用上述MRC中片段抽取的思想,输入文本序列X和问题 q ( y ) q(y) q(y), a a a是需要抽取的实体,BERT_MRC通过建模 P ( a ∣ C , Q ) P(a|C,Q) P(a∣C,Q)来实现实体抽取。
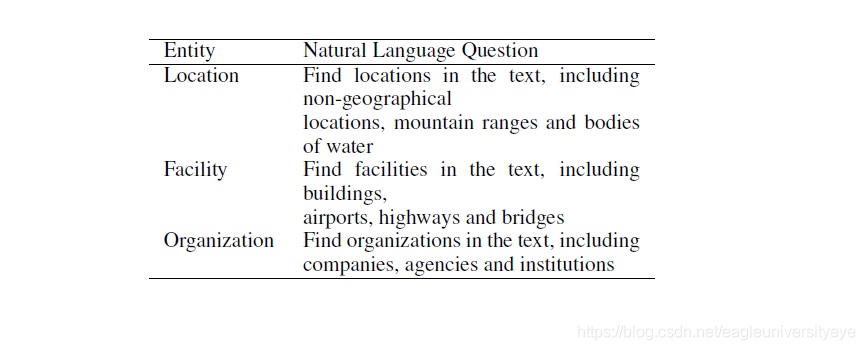
对于问题 q ( y ) q(y) q(y) 的构造是建模 P ( a ∣ C , Q ) P(a|C,Q) P(a∣C,Q) 的重要环节。BERT_MRC使用“标注说明”作为每个标签的问题。所谓“标注说明”,是在构造某个数据集的时候提供给标注者的简短的标注说明。比如标注者要去标注标签为LOC的所有实体,那么对应LOC的标注说明就是“Find locations in the text, including non-geographical locations, mountain ranges and bodies of water”,下图是更多的例子。
在抽取实体的具体方法上,BERT_MRC使用了指针网络,就是下图所示的两层标注网络,一层标记实体开始位置,一层标记实体结束位置。如果一共有N个类型的实体,则需要2*N个这样的标注序列,每两个标注序列一组,共N组,根据 ‘’1“ 标签所在的标签组来确定实体的类型。如下图所示:
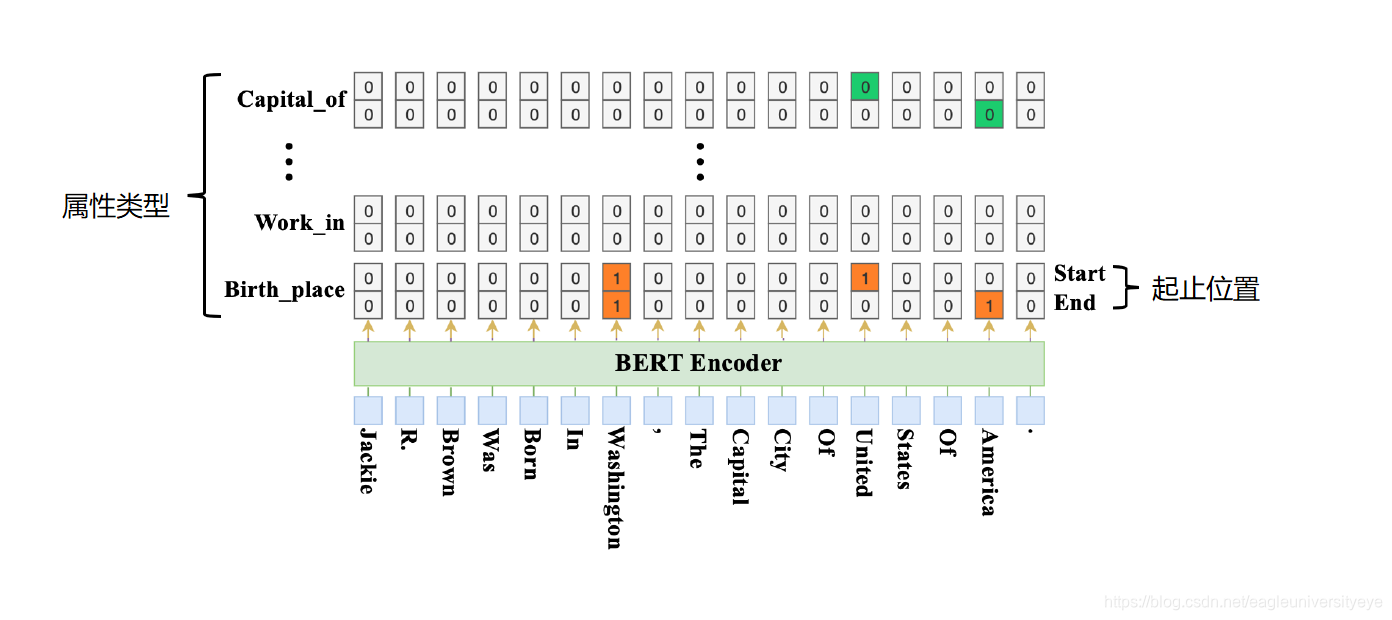
BERT_MRC定义了三个损失函数,分别计算开始位置损失、结束位置损失和实体损失,训练时总的loss值是上述三个损失值之和。

BERT_MRC的实验设置非常有意思,通过设置很多对比实验,证明了很多有用的信息,下面是对BERT_MRC论文中的一些实验结论的总结:
1.相比baseline,BERT_MRC能够更好地解决数据稀疏问题,主要原因是MRC中的问题能够编码一部分先验信息。
2.指针网络能有效解决实体重叠问题,无论对non-BERT还是BERT模型,MRC都比non-MRC好。
3.针对BERT_MRC中问题的构建策略,BERT_MRC又提出了很多问题的构建方法,但是实验证明,上文提到的“标注说明“仍是最有效的方法。
4.引入MRC中的问题后,由于问题中编码了一些先验信息,所以在标签迁移上效果较好。并且具有了一定的先验知识编码能力。
Multi-turn QA
实体关系抽取的大多数模型都将实体关系联合抽取的任务看作是一个三元组抽取任务,而这样的处理将存在如下几个问题
- 在形式化层面上:简单的三元组形式往往不能充分表现文本背后的结构化信息,因为往往在文本中存在层级性的依赖关系。独立地考虑两种实体可能导致依赖关系的间断,导致重要信息的缺失,从而影响模型的判断。
- 在算法层面上:对于关系抽取任务,大多数模型都是以标记的 mention 作为输入,而模型的主要目的是判断两个 mention 是否存在某种关系,在这种情况下,模型难以捕捉词汇、语法以及语义上的关系,特别是在如下几种情形下: 1.实体相距很远,即长距离依赖问题;2.一个实体出现在多个三元组中,即实体重叠问题;3.关系跨度相交,即关系交叉问题。
Multi-turn QA模型的创新点在于其将实体关系联合抽取的任务当作一个多轮问答类问题来处理,即每种实体和每种关系都用一个问答模板进行刻画,从而这些实体和关系可以通过回答这些模板化的问题来从上下文中进行抽取。下面简单给出一个问答模版:

可见,问题主要有如下几个特点:
-
首先确定目标实体 e1
-
之后根据目标实体和候选关系类别进行提问
这样的处理方法主要有如下几个优点:
- 能够很好地捕捉标签的层次依赖性。即随着每一轮问答的进行,我们有序的获得所需要的实体,这与多回合填充式对话系统类似
- 问题的编码能够整合对关系分类任务重要的一些先验信息,这些信息可以潜在地解决了现有关系抽取模型难以解决的问题,如远距离实体对,或是关系重叠问题
- QA任务提供了一种很自然的方式来融合实体抽取和关系抽取任务,因为 QA 任务对于没有答案的问题可以返回 None,则对于不存在相应关系的问题,如果返回的不是 None,则可以同时确定实体和关系

将实体关系抽取任务转化为多轮问答任务的算法如上所示,整个算法分如下几个部分:
- 头实体抽取(line 4 - 9):由于每一轮多轮对话都需要一个头实体来作为 trigger,因此需要事先抽取句子中所有的头实体,而抽取实体的过程可以看作一个抽取 entity_question 答案的过程。所有 entity_question 都存放在 EntityQuesTemplates 中,每一种 entity_question 都对应一类实体的抽取
- 关系与尾实体抽取(line 10 - 24):ChainOfRelTemplates 定义了一个关系序列,我们需要根据这个关系序列来进行多轮问答。同时,它也定义了每种关系的模板,为了生成对应的问题(第14行),我们要在模板槽(slot)中插入之前抽取的实体。然后,关系 REL 和尾实体 e 就能通过回答问题同时被抽取出来。如果回答是 None,就说明没有答案,即只有同时抽出头实体,以及头实体存在对应的关系和尾实体被抽出时,才算是成功抽出一个满足条件的三元组了。
我们知道现阶段常见的 MRC 模型都是通过指针网络的方式,仅预测答案在 Context 中的开始和结束位置,仅适用于单答案的情况。但对于实体识别任务,在一段 Context 中可能有多个答案,所以这种方法并不合适。作者的做法是将其当作以问题为基础的序列标注问题,或者说将 2 个 N-class 分类任务转换成 N 个 5-class 分类任务,其中 N 为句子长度。
作者将 BERT 作为 baseline。训练时,损失函数为两个子任务的叠加,即:
L = ( 1 − λ ) L ( h e a d e n t i t y ) + λ L ( t a i l e n e t i t y , r e l ) L=(1−λ)L(head_entity)+λL(tail_enetity,rel) L=(1−λ)L(headentity)+λL(tailenetity,rel)
HBT、ETL-span
这两个模型的思想和方法非常相似,所以放在一起介绍,它们能达到SOTA的重要原因之一就是因为使用了MRC中的指针网络。
HBT和ETL-span的抽取过程和Multi-turn QA相似,将实体关系三元组的抽取分解成了多个步骤来完成。但在具体实现的细节上上,HBT和ETL-span和使用多轮对话的Multi-turn QA有很多不同。
HBT和ETL-span将三元组的抽取任务建模为三个级别的问题,从而能够更好解决三元组重叠的问题。其核心观点就是不再将关系抽取的过程看作实体对的离散标签,而是将其看作两个实体的映射关系,即f(s,o)−>r,整个三元组的过程可以概括为:
- 抽取三元组中的 subject
- 针对每一个 fr(⋅),抽取其对应的 object
HBT模型的整体结构如下图所示,主要包括如下几个部分:
- BERT Encoder:通过 BERT 得到每个词的词表征,把BERT的输出当作词向量使用
- Subject Tagger:该部分用于识别所有可能的subject对象。其通过对每一个位置的编码结果用两个分类器(全连接层)进行分类,来判断其是否是实体的开始或结束位置
- Relation-specific Object Taggers:针对每一个 subject,都需要对其进行之后的 object 进行预测。由图中可知,其与 Subject Tagger 基本一致,主要区别在于每一个关系类别独享一组 object 分类器,同时还要将subject作为特征和BERT词向量拼接后作为输入
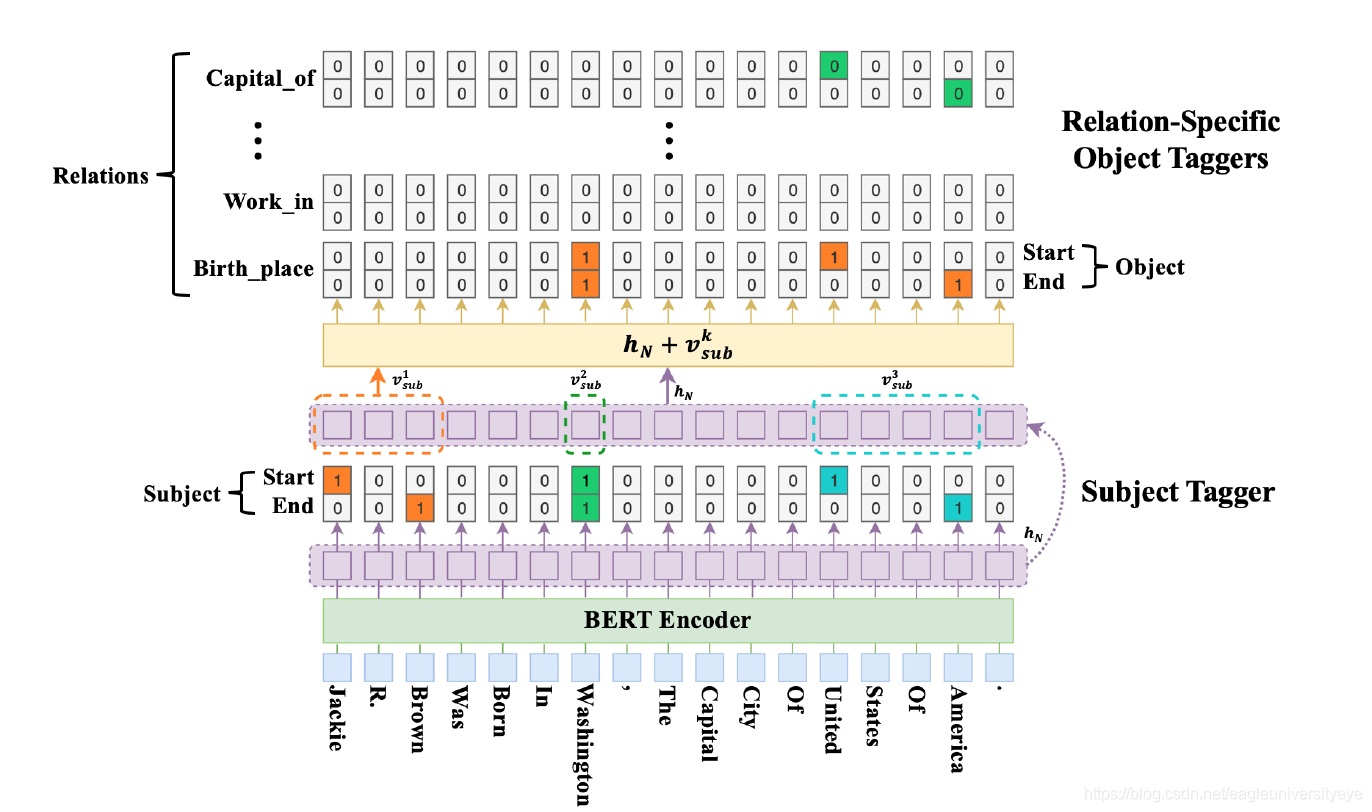
HBT的解码方式和传统的基于序列标注的解码方式有很大的不同,HBT基于指针网络,确定实体span通过两个分类器来实现,采用sigmod+BinaryCrossEntrpy的方式,而序列标注则只训练一个分类器,采用softmax+CrossEntropy的方式。HBT的这种多层标记结构能够很好地抽取出重叠实体和关系,而且由于增加了分类器的数量,使得每个分类器只用进行二分类,而序列标注的分类器则需要进行多分类,因此HBT对非重叠的实体和关系也有很好的效果。
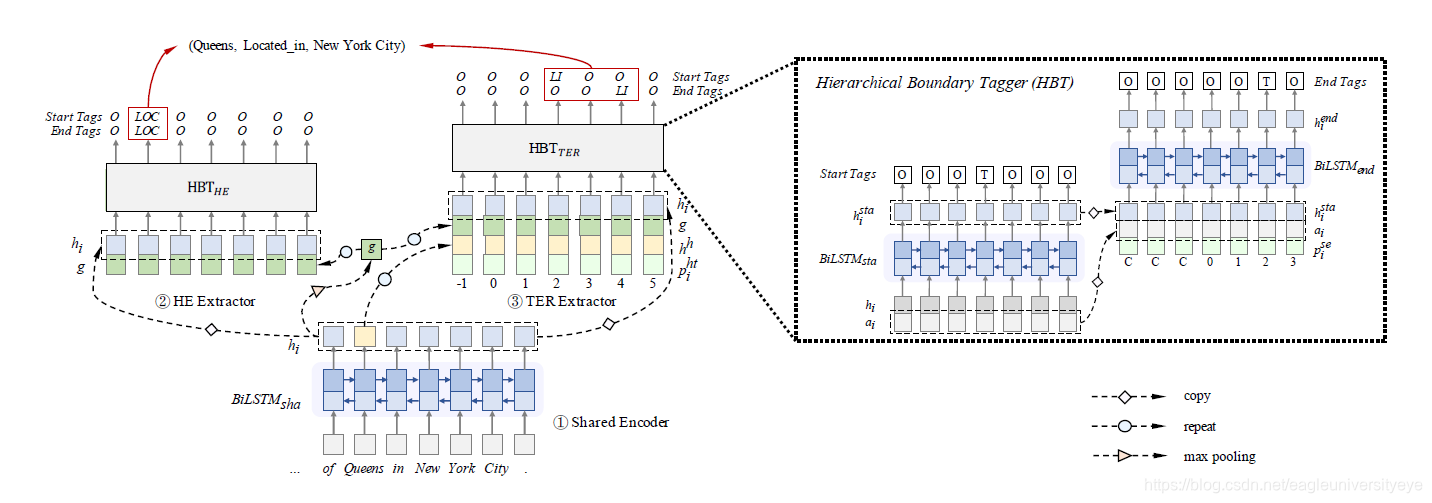
ETL-span和HBT的结构差不多,只是在编码层上有一点不同,ETL-span利用模型的分层结构,将靠前步骤得到的一些句向量,位置向量作为特征,加入进靠后的步骤,取得了不错的效果。而识别实体范围,关系类型的方法和HBT一样,都采用了指针网络。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









