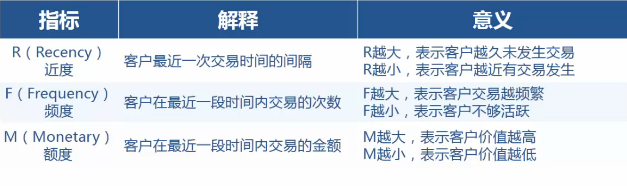
RFM分析
RFM分析是根据客户活跃程度和交易金额贡献,进行客户价值细分的一种方法;
可以通过R,F,M三个维度,将客户划分为8种类型。
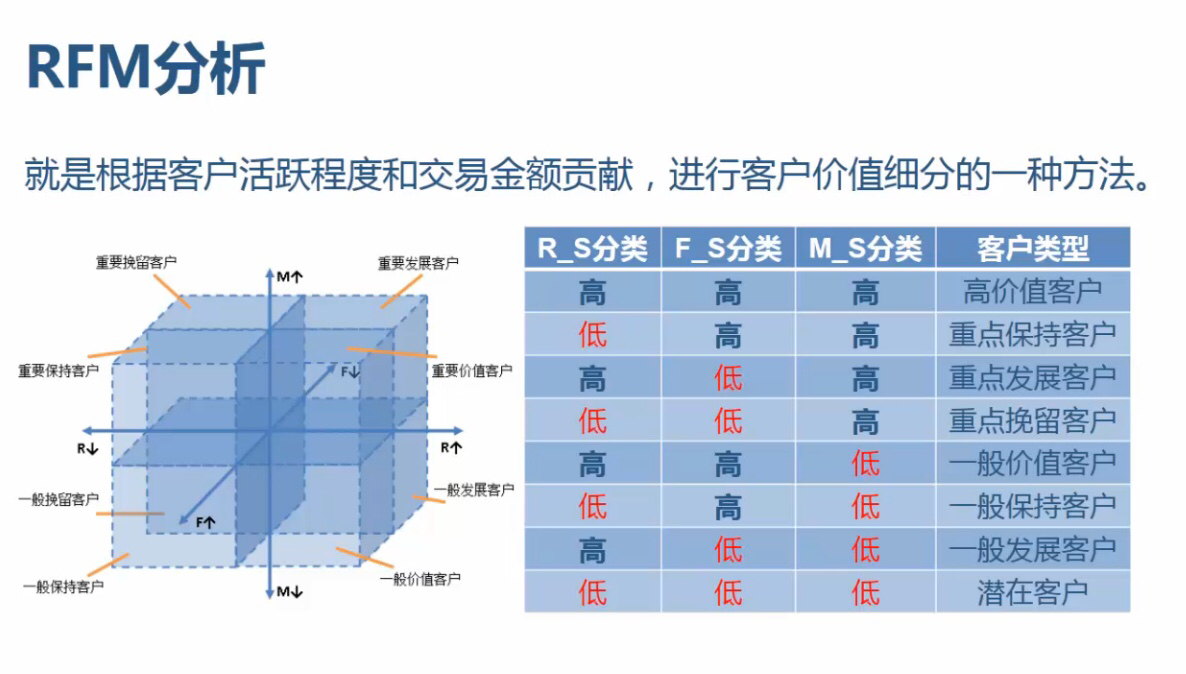
RFM分析过程
1.计算RFM各项分值
R_S,距离当前日期越近,得分越高,最高5分,最低1分
F_S,交易频率越高,得分越高,最高5分,最低1分
M_S,交易金额越高,得分越高,最高5分,最低1分
2.归总RFM分值
RFM=100*R_S+10*F_S+1*M_S
3.根据RFM分值对客户分类
RFM分析前提,满足以下三个假设,这三个假设也是符合逻辑的
1.最近有过交易行为的客户,再次发生交易的可能性要高于最近买有交易行为的客户;
2.交易频率较高的客户比交易频率较低的客户,更有可能再次发生交易行为;
3.过去所有交易总金额较多的客户,比交易总金额较少的客户,更有消费积极性。
我们了解了RFM的分析原理后,下面来看看如何在Python中用代码实现:
- import numpy
- import pandas
-
- data = pandas.read_csv(
- 'D:\\PDA\\5.7\\data.csv'
- )
-
- data['DealDateTime'] = pandas.to_datetime(
- data.DealDateTime,
- format='%Y/%m/%d'
- )
-
- data['DateDiff'] = pandas.to_datetime(
- 'today'
- ) - data['DealDateTime']
-
- data['DateDiff'] = data['DateDiff'].dt.days
-
- R_Agg = data.groupby(
- by=['CustomerID']
- )['DateDiff'].agg({
- 'RecencyAgg': numpy.min
- })
-
- F_Agg = data.groupby(
- by=['CustomerID']
- )['OrderID'].agg({
- 'FrequencyAgg': numpy.size
- })
-
- M_Agg = data.groupby(
- by=['CustomerID']
- )['Sales'].agg({
- 'MonetaryAgg': numpy.sum
- })
-
- aggData = R_Agg.join(F_Agg).join(M_Agg)
-
- bins = aggData.RecencyAgg.quantile(
- q=[0, 0.2, 0.4, 0.6, 0.8, 1],
- interpolation='nearest'
- )
- bins[0] = 0
- labels = [5, 4, 3, 2, 1]
- R_S = pandas.cut(
- aggData.RecencyAgg,
- bins, labels=labels
- )
-
- bins = aggData.FrequencyAgg.quantile(
- q=[0, 0.2, 0.4, 0.6, 0.8, 1],
- interpolation='nearest'
- )
- bins[0] = 0;
- labels = [1, 2, 3, 4, 5];
- F_S = pandas.cut(
- aggData.FrequencyAgg,
- bins, labels=labels
- )
-
- bins = aggData.MonetaryAgg.quantile(
- q=[0, 0.2, 0.4, 0.6, 0.8, 1],
- interpolation='nearest'
- )
- bins[0] = 0
- labels = [1, 2, 3, 4, 5]
- M_S = pandas.cut(
- aggData.MonetaryAgg,
- bins, labels=labels
- )
-
- aggData['R_S']=R_S
- aggData['F_S']=F_S
- aggData['M_S']=M_S
-
- aggData['RFM'] = 100*R_S.astype(int) + 10*F_S.astype(int) + 1*M_S.astype(int)
-
- bins = aggData.RFM.quantile(
- q=[
- 0, 0.125, 0.25, 0.375, 0.5,
- 0.625, 0.75, 0.875, 1
- ],
- interpolation='nearest'
- )
- bins[0] = 0
- labels = [1, 2, 3, 4, 5, 6, 7, 8]
- aggData['level'] = pandas.cut(
- aggData.RFM,
- bins, labels=labels
- )
-
- aggData = aggData.reset_index()
-
- aggData.sort(
- ['level', 'RFM'],
- ascending=[1, 1]
- )
-
- aggData.groupby(
- by=['level']
- )['CustomerID'].agg({
- 'size':numpy.size
- })
RFM在传统的直效营销领域的应用
作为一种对
客户分类的方法,RFM分析模型起初主要用于直效营销(Direct Marketing)领域,目的是提高老客户交易的次数。
广东一家办公设备及耗材零售企业,在省内建立了9家连锁配送中心,业务发展迅速,有过成交记录的老客户也多了起来,通过向客户用邮政信函发送商品目录、开展直效营销的成本越来越高。该公司希望找到一种更有效的方法,来区分客户,以便在“更恰当的时间、向恰当的客户传递恰当的商品信息”,从而刺激重复交易,同时也适当降低邮寄费用。
他们把客户购买日期到当天的天数算出来,得到R这个参数。然后可以依据参数R的大小对客户进行分组,例如可以把客户分成数量基本相等的5个等级,R5级表示购买时间最接近统计当日,R1级表示购买时间最远离统计当日;此外还可以依据停止交易的绝对天数、不考虑每级的客户数量是否近似而进行划分。
对于R5级的客户,该公司会立即再邮寄一份商品目录及奖励积分计划,对于R4级的客户则会在一周内再邮寄一份商品目录及奖励积分计划,对于R3级以下的客户则不采用这种追随购买的邮寄方式。 根据国外的统计结果,R5级客户对直效邮件的回函率是R4级的三倍,因为这些客户刚完成交易不久,所以会更注意同一公司的商品信息。如果及时跟进的邮件内容,采用“交叉销售”(Cross-Sell)或“追加销售”(Up-Sell)的策略,推荐与客户购买需求相关度高的商品,或者提供额外的重复购买奖励,效果更加显著。
通过大量的统计发现,紧随参数R之后、与重复购买有密切关系的是参数F。采用F购买次数作为参数,将客户分为F5~F1五组,采取不同的邮寄策略也是很有意义的。例如过去6个月购买超过5次以上的客户,今后将每月邮寄一次商品目录;而购买不足2次的客户,将只会每两个月邮寄一次。
相对而言,参数M与刺激重复购买的频率之间关系不那么紧密。统计发现,如果采用M货币价值这个参数对
客户分类,平均交易金额高的客户的反馈率并不见得比平均交易金额低的客户来得多。但这个世界永远存在这样一些客户,他们对一些促销宣传小策略反应冷漠,但偶尔一次的大额采购往往给您带来意外的惊喜。 因此有必要让他们在需要采购的时候能想起您,这就需要利用参数M,同样我们也可以把客户分为M5~M1五组。
将客户分别按照R、F、M参数分组后,假设某个客户同时属于R5、F4、M3三个组,则可以得到该客户的RFM代码543。同理,我们可以推测,有一些客户刚刚成功交易、且交易频率高、总采购金额大,其RFM代码是555,还有一些客户的RFM代码是554、545……每一个RFM代码都对应着一小组客户,开展市场营销活动的时候可以从中挑选出若干组进行。
RFM非常适用于提供多种商品的企业,这些商品单价相对不高,或者相互间有互补性,具有多次重复购买的必要,这些企业可能提供如下商品:日用消费品、服装、小家电等;RFM也适用于这类企业,它们既提供高价值耐用商品、同时又提供配套的零部件或维修服务,如下:精密机床、成套生产设备、打印机等;RFM对于商品批发、原材料贸易、以及一些服务业(如旅行、保险、运输、快递、娱乐等)的企业也很适用。

























 1427
1427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









