







摘要:本文主要提出了一个深度特征流算法,用于视频的识别。它仅在稀疏的关键帧上运行计算量极大的卷积子网络,并通过流场将它们的深度特征图传输到其他帧。由于流计算方法相对较快,所以算法得到了明显的加速。整个框架的端到端的训练明显提升了识别的精度。
由于中间卷积特征图与输入图像拥有相同的空间大小(通常以较小分辨率,例如,16×更小)。它们保留了低级图像内容与中高级语义内容之间的空间对应关系。这种对应关系通过空间形变给附近帧之间的特征传播提供了机会,类似于光流法。
本文提出了深度特征流算法仅在稀疏的关键帧上运行计算量极大的卷积子网络,并通过流场将它们的深度特征图传输到其他帧。方法如下图所示。两个中间特征图分别对应“汽车”和“人”。它们在两个相邻帧上是相似的。从关键帧传播到当前帧之后,传播的特征与原始特征相似。

给定图像识别任务和前馈卷积网络N对输入图像I的输出的结果为。我们的目标是将网络应用于所有视频帧
 ,
, 。
。
首先我们将N分解成两个连续的子网络。第一个子网络 ,被称为特征网络,是完全卷积网络,并输出多个中间特征图,
,被称为特征网络,是完全卷积网络,并输出多个中间特征图, 。第二个子网
。第二个子网 ,被称为任务网络,是根据任务的不同具有的特定结构,在特征图上执行识别任务,
,被称为任务网络,是根据任务的不同具有的特定结构,在特征图上执行识别任务,。
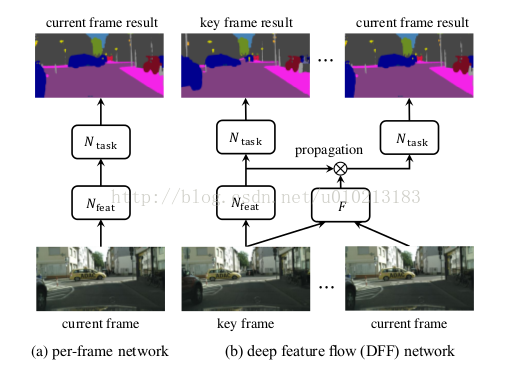 只在稀疏的关键帧上运行。非关键帧
只在稀疏的关键帧上运行。非关键帧 的特征图则由其上一个的关键帧
的特征图则由其上一个的关键帧 的特征图传播得到。
的特征图传播得到。
令 为二维流场,由流估计算法[1,2]
为二维流场,由流估计算法[1,2] 获得,其中,
获得,其中, 。特征图被双线性插值算法调整到相同的空间分辨率上进行传播。它将当前帧
。特征图被双线性插值算法调整到相同的空间分辨率上进行传播。它将当前帧 中的位置
中的位置 投影到关键帧
投影到关键帧 中的位置
中的位置 ,其中
,其中 。
。
由于 值通常为分数,因此通过双线性插值来实现特征的形变:
值通常为分数,因此通过双线性插值来实现特征的形变:
其中 为特征图
为特征图 中的通道,
中的通道, 枚举了特征图中的所有的空间位置,
枚举了特征图中的所有的空间位置, 表示双线性插值的内核。 注意,
表示双线性插值的内核。 注意, 是二维的,下式将其分成两个一维的内核:
是二维的,下式将其分成两个一维的内核:

其中
由于流估计错误等造成空间形变计算不准确。为了更好地近似特征,它们的幅度由“尺度场” 来调整,其空间维度和通道维度与特征图相同。“尺度场”通过在两帧上应用“比例函数”
来调整,其空间维度和通道维度与特征图相同。“尺度场”通过在两帧上应用“比例函数” 来获得,
来获得,
最后,特征传播函数定义为:
其中 对特征图中的所有位置和所有通道使用公式(1),并让特征应用尺度以元素方式进行倍增。
对特征图中的所有位置和所有通道使用公式(1),并让特征应用尺度以元素方式进行倍增。
这种视频识别的算法称为深度特征流算法,具体流程详见下面的流程图:
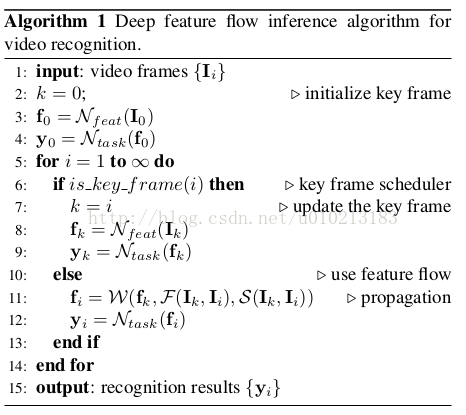
关键帧的调整:视频识别加速的关键之一是何时分配新的关键帧。在这项工作中,我们使用简单的固定关键帧,即关键帧持续时间长度 是固定常数。本文在最后给挖了个坑,它提出图像内容的各种变化可能需要变化的来平滑的权衡精度和速度。理想情况下,当图像内容发生急剧变化时,应分配新的关键帧。如何设计有效且自适应的关键帧长度可以进一步提高识别的精度和速度。
是固定常数。本文在最后给挖了个坑,它提出图像内容的各种变化可能需要变化的来平滑的权衡精度和速度。理想情况下,当图像内容发生急剧变化时,应分配新的关键帧。如何设计有效且自适应的关键帧长度可以进一步提高识别的精度和速度。















 737
737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









