






上文(一文了解语义分割网络)首先介绍语义分割的问题背景,从构造一个简单的网络结构开始,讲述了直接堆叠一些卷积层不可行的原因,最后引出了全卷积网络和编码器-解码器结构。
本文接着上文继续…
添加跳跃连接
上文最后一段提到,FCN论文作者对语义分割的一段评价:
语义分割面临着语义和位置之间的内在张力:全局信息解决**“是什么”,而局部信息解决“在哪里”**。…将细致层和粗糙层结合起来,可以让模型做出符合整体结构的局部预测。
那么如何解决这种内在张力?
作者通过对编码的特征图向上采样,得到一个特征图;从较早的层上添加跳跃连接,也会得到一个特征图;然后对两个特征图进行融合(融合是add 操作,须要相加的特征图宽、高和通道数是一致的)。

这些从早期层过来的跳跃连接提供了必要的细节特征,使得最后的分割图得到更精确的形状,实际上,通过添加这些跳过连接,我们可以恢复更多细节。

这里可以与上一篇文章中的最后一个示意图结合着对比,发现轮廓明显更好一点。
Ronneberger等人主要通过扩展网络中的解码器容量来改进了全卷积结构。具体来说,作者提出了U型网络结构,**该结构包括一个捕捉上下文的收缩路径和一个实现精确定位的对称扩展路径。**这种更简单的结构已经变得非常流行,并已经应用于各种分割问题。
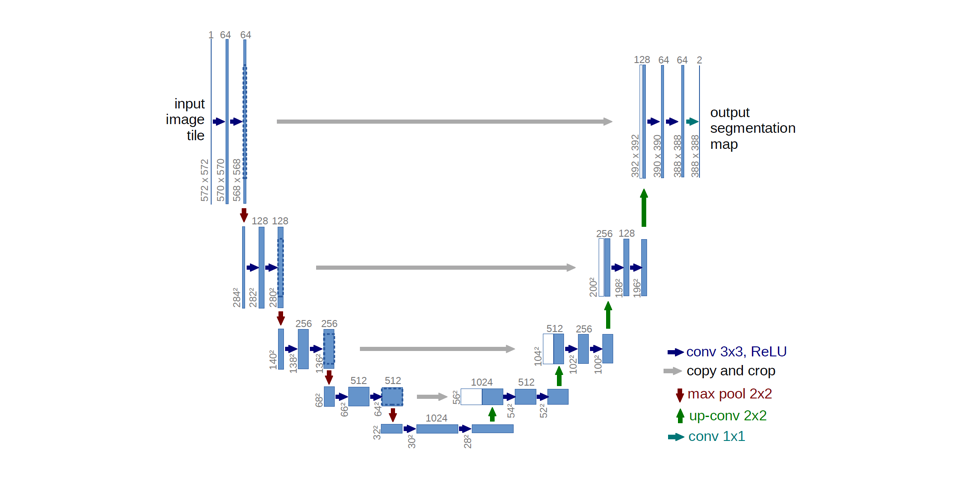
注意:最初的架构由于使用的是valid padding的填充方式,从而导致特征图尺寸的下降。然而,一些实践者选择使用same padding的填充方式,其中填充值是通过图像在边界上的反射获得的。
在数据增强方面,Long等人(FCN论文作者)指出数据增强(尝试随机镜像、jettering图像)并没有改善结果;而在Ronneberger 等人(U-Net 论文作者)却指出数据增强(训练样本的随机弹性变形)是一个关键步骤。这里的矛盾,似乎说明数据增强的有用与否取决于问题域。
高级U-Net 变体
标准的U-Net 模型由在网络中的每个**“块(block)**”的一系列卷积操作组成。代替于堆叠卷积层,存在许多更高级的“块”,可以通过堆叠块来搭建网络结构。
Drozdzal等人将基本的叠加卷积块替换为残差块(residual blocks)。上文我们知道,现有的标准U-Net 结构中引入了跳跃连接,该跳跃连接位于编码器与解码器的相应特征映射之间。在此基础上,Drozdzal 等人使用残差块代替卷积层,并引入了短跳连接。他们文中指出,短跳连接能够允许在训练时更快的收敛,并允许更深层次的模型得到训练。
在此基础上,Jegou等人提出使用稠密块(dense blocks), 仍然遵循U-Net结构,认为DenseNets的特性非常适合于语义分割,因为它们会自然的引起跳跃连接和多尺度监督。这些稠密块是有用的,因为它们直接携带了前几层的低层特征,以及最近几层的高层特征。从而实现了高效的特征重用。
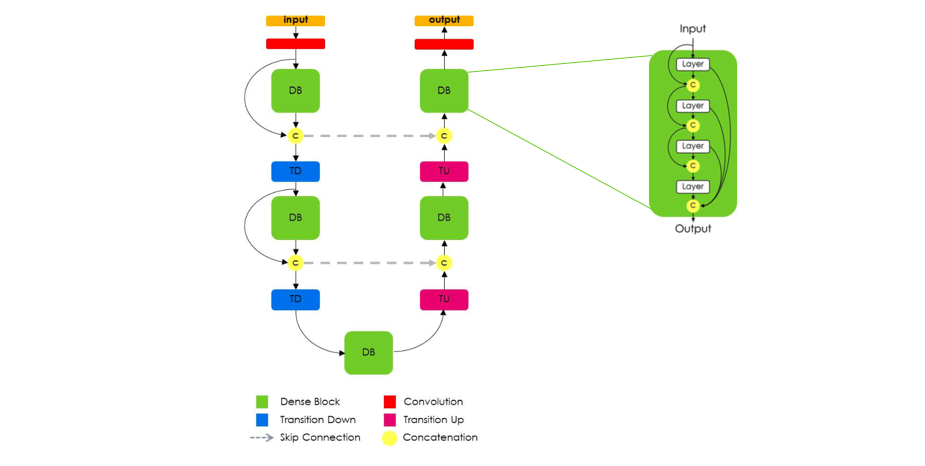
注意: 这种结构的一个非常重要的方面是,上采样路径在稠密块的输入和输出之间没有跳过连接(如上图所示)。
作者指出,由于“上采样路径增加了特征映射的空间分辨率,特征数量的线性增长将过于消耗内存。”因此,只有稠密块的输出在解码器模块中传递。

下图是FC-DenseNet103模型在CamVid数据集上获得最新成果(2017年10月)。
空洞卷积(Dilated convolutions)
对特征图进行下采样的一个好处是,在给定一个恒定的滤波器大小的情况下,它拓宽了后续滤波器的感受野(相对于输入)。回想一下,由于大尺寸的过滤器的参数效率低,这种方法比增加过滤器大小更为理想。然而,这种更广泛的背景是以降低空间分辨率为代价的。
空洞卷积提供了另一种方法以获得广泛的感受野,同时保持完整的空间维度。如下图所示,用于空洞卷积的值是根据特定的扩张率(dilated rate) 来间隔的。
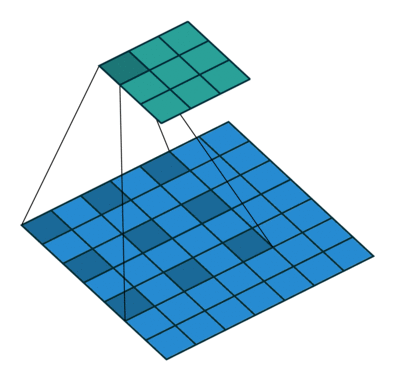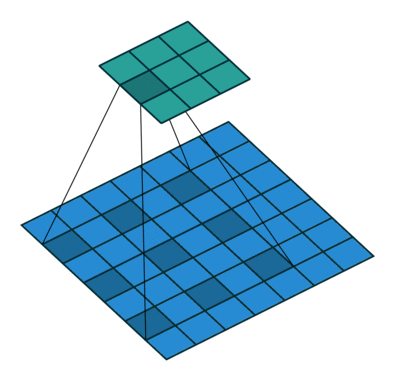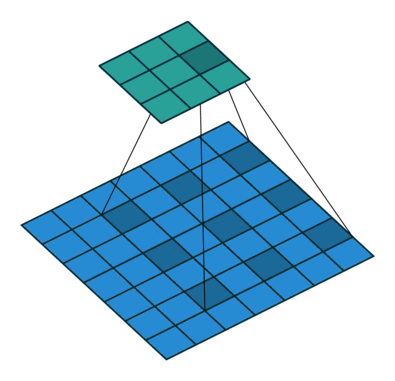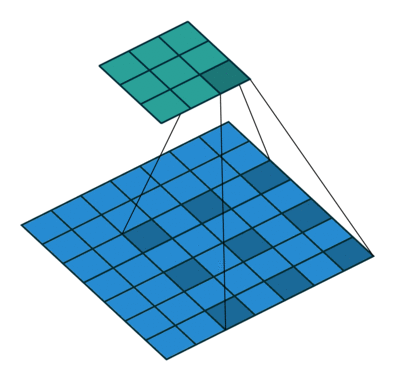
一些网络结构提出将最后几个池化层替换为具有连续更高扩张率的空洞卷积,以保持相同的视野,同时防止空间细节的丢失。但是,要用空洞卷积完整地替换池化层,通常仍然需要大量的计算量。
笔者注:
Dilated convolutions, 中文翻译有多种,包括空洞卷积、扩张卷积、膨胀卷积,都是指同一个概念。
阅读到这里,如果愿意对空洞卷积深入了解,推荐阅读三篇关于空洞卷积的文章:
- Multi-scale context aggregation with dila
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5194
5194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









