






最近想要自己玩一个多模态医疗大模型,首选需要获取数据集,于是抱抱脸上找到了MedTrinity-25M的下载地址 https://huggingface.co/datasets/UCSC-VLAA/MedTrinity-25M
数据集介绍
MedTrinity-25M 是一个全面的大型医学多模态数据集,由华中科技大学、加州大学、哈佛大学、斯坦福大学等机构合作发布,涵盖 10 种模态 2500 多万张图像,为 65 多种疾病提供多粒度注释。这些注释既包括全局文本信息,例如疾病/病变类型、模态、区域特定描述和区域间关系,也包括感兴趣区域 (ROI) 的详细局部注释,包括边界框、分割蒙版。支持全面的多模态任务,例如字幕和报告生成,以及以视觉为中心的分类、分割等任务。
下载数据集
本地安装官网提示下载遇到了各种问题(25M_full下载正常,但25M_demo各种失败),于是果断使用手工下载数据集
点击data后一个个点击下载,总共10个文件
下载之后长这样
本地预览数据集
.parquet文件,使用pandas pyarrow引擎可以读取,脚本如下:
df = pd.read_parquet(‘cache/UCSC-VLAA___med_trinity-25_m/25M_demo/0.0.0/train-00000-of-00010.parquet’, engine=‘pyarrow’)
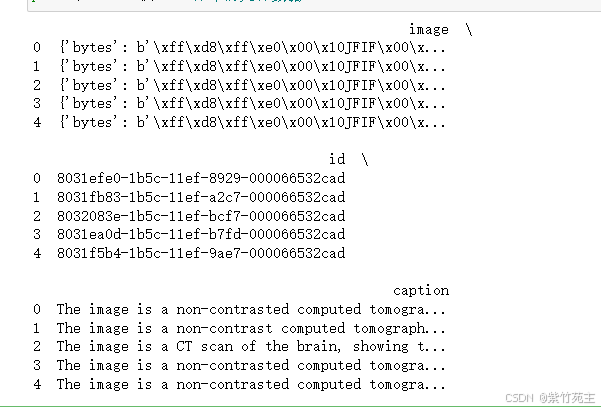
打印前五行出来看看 print(df.head()) ,数据长这样
不记得df都有啥,没关系,dir(df)去看看都有哪些方法和熟悉可用,看到了info,就他吧
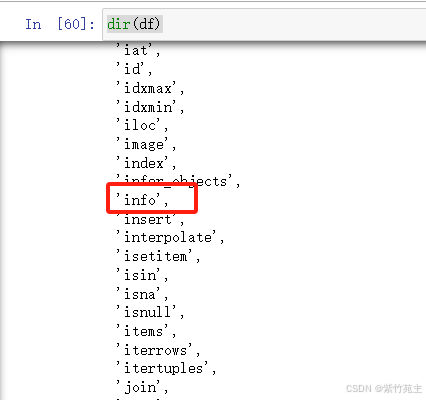
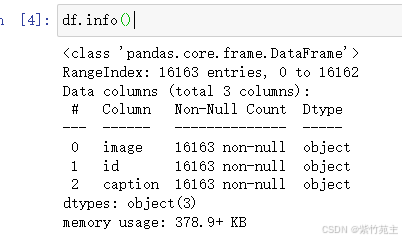
df.info()预览一下信息 长这样,不错,大概知道里面都有啥了
再试试loc方法,df.loc[0]读取第0行信息,长这样

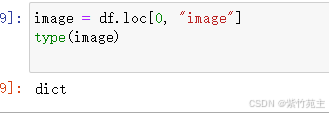
看到imag、id 和caption信息,image是bytes类型,存储在一个字典里,探究一下字典里还放了什么: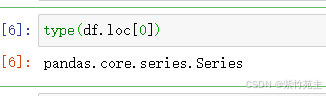 image = df.loc[0, “image”]
image = df.loc[0, “image”]
type(image) 果然是个字典
来看看字典里都有啥,image.keys()
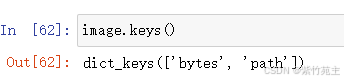
image.values()
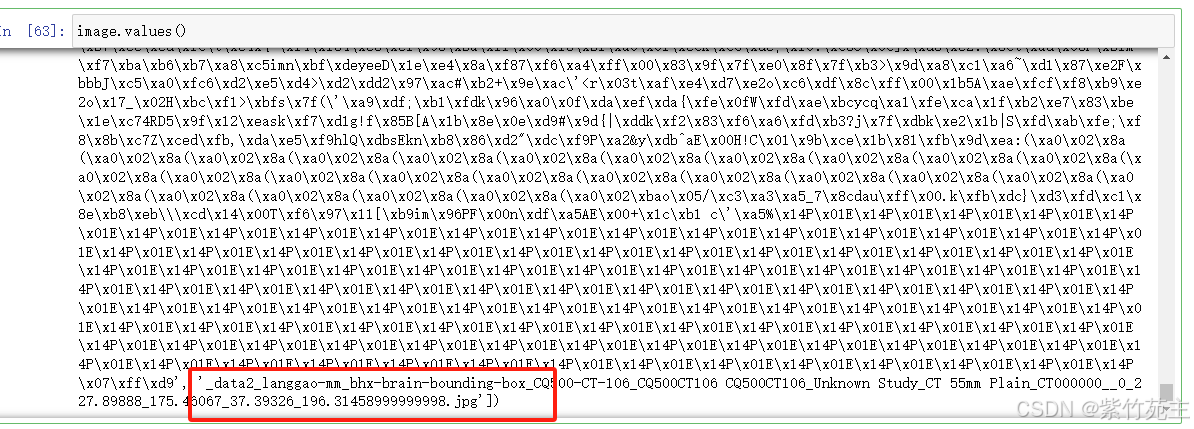 嗯,基本清楚数据里放的是图像、id、caption、还有路径,可用试试看完整的图像和内容了,
嗯,基本清楚数据里放的是图像、id、caption、还有路径,可用试试看完整的图像和内容了,
临时写一个方法来显示图像和相关描述使用

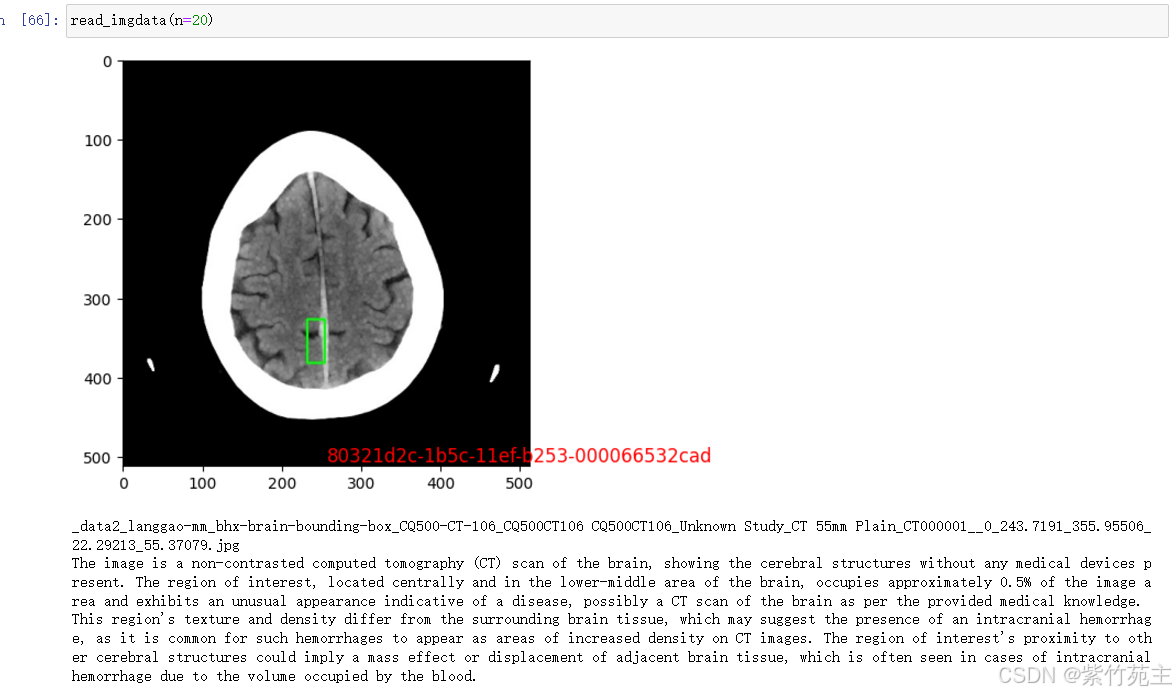
好啦,数据全貌都出来啦,后续再记录如何使用这些数据搞点事情

















 3443
3443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









