







最近刚入手一台 Jetson Ori Nano 开发板,前两篇把开发前的准备工作做了:
Jetson Ori Nano 搭载了一块有 1024 个 CUDA 核的 GPU,可提供 40 TOPS(每秒万亿次)的算力,为本地跑大模型提供了一种可能。
在最强开源Qwen2.5:本地部署 Ollma/vLLM 实测中,我们实测发现:GPU 推理速度是 CPU 的 10+ 倍!
边缘设备中,还有这么高的加速比么?
用 Jetson Ori Nano 跑大模型,速度咋样?
本文就带大家用 Ollama 实测一番。
1. Ollama 支持所有 GPU 么
Ollama 是一款最适合小白的大模型部署利器,所谓的一键部署是 Ollama 帮你搞定了很多麻烦事,比如 GPU 加速、模型量化等。
但 Ollama 并非支持所有 GPU 设备的加速推理。
划重点:Ollama 只支持计算能力 5.0 及以上的 Nvidia GPU!
其中,计算能力 5.0 是NVIDIA 是定义的一个术语,不同版本意味着支持不同的 CUDA 特性,以及不同的计算性能。
https://developer.nvidia.com/cuda-gpus这里可以查看你的 GPU 对应的计算能力。
Jetson Orin Nano 的计算能力是 8.7,理论上是可行的?
2. 原生 Ollama 部署失败
在 Jetson 中,系统内存和 GPU 显存共享,板卡使用的是专门为嵌入式系统优化的驱动和API,原生 Ollama 无法在 Jetson 上利用 GPU 跑大模型。
首先,尝试 docker 部署 Ollma。
1. 使用 GPU:
docker run -d --runtime nvidia -v ollama:/root/.ollama -p 3002:11434 --restart unless-stopped --name ollama ollama/ollama
2. 使用 CPU:
docker run -d -v ollama:/root/.ollama -p 3002:11434 --restart unless-stopped --name ollama ollama/ollama
但是,使用 GPU 无法将模型加载到内存中,而 CPU 可以,一开始以为是 docker 环境的问题,后来尝试了本地部署,依然无法加载成功。
直到找到 Jetson Containers 这个工具。
3. dustynv/ollama 镜像部署成功
Jetson Containers 是专为 Jetson 设计的容器项目,提供了模块化的容器构建系统,底层依赖 docker。
其中,专为 Ollama 提供了一个教程:https://www.jetson-ai-lab.com/tutorial_ollama.html。
不过,jetson-containers run --name ollama $(autotag ollama) 命令依然是采用的 Ollama 原生镜像,所以搞不定。
后面发现dustynv/ollama:r36.2.0这个镜像,可以成功拉起支持 Jetson GPU 的docker 容器:
docker run -d --runtime nvidia --restart unless-stopped -p 3002:11434 -v ollama:/ollama -e OLLAMA_MODELS=/ollama -e OLLAMA_LOGS=/ollama/ollama.log --name ollama dustynv/ollama:r36.2.0
通过如下命令进入容器:
docker exec -it ollama /bin/bash
接下来,下载你需要的模型就行,具体可参考:最强开源Qwen2.5:本地部署 Ollma/vLLM 实测
打一个请求测试了看看吧:
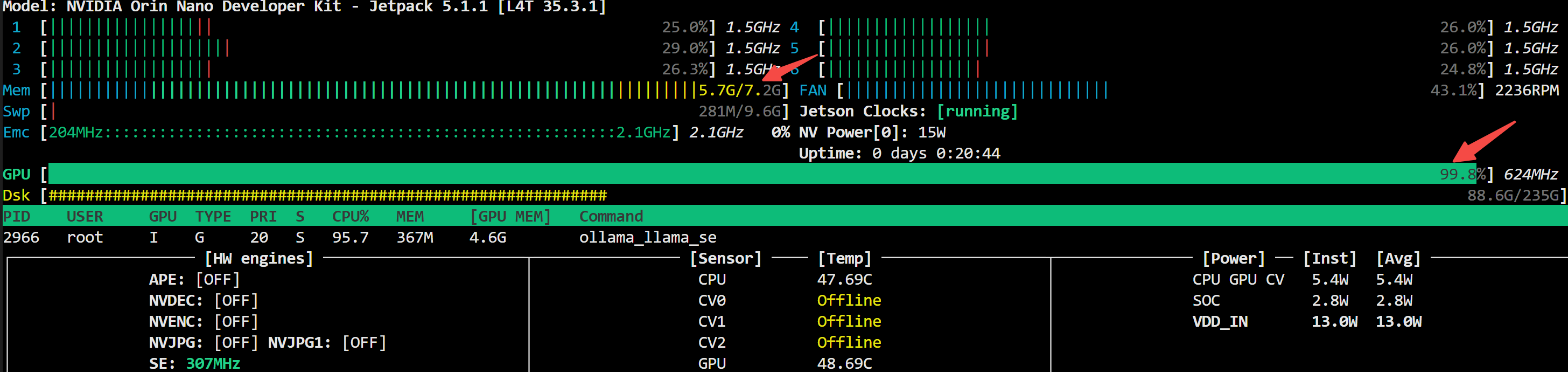
上图可以发现:CPU 没有打满,但 GPU 利用率上来了,说明你的模型已经成功跑在了 GPU 上!
4. CPU/GPU 速度对比
既然已经实现了 GPU 推理加速,自然最关心的问题是:加速效果如何?
我们还是采用上篇的测试方法:非流式输出,直接使用输出文本字数进行平均耗时对比。
cpu 跑 qwen2.5:7b
7b cpu: 0, time: 4.08s, token/s: 3.68
7b cpu: 1, time: 6.31s, token/s: 3.80
7b cpu: 2, time: 5.02s, token/s: 3.39
7b cpu: 3, time: 9.39s, token/s: 4.26
7b cpu: 4, time: 6.68s, token/s: 3.89
gpu 跑 qwen2.5:7b
qwen2.5-7b time: 45.86s, token/s: 9.31
qwen2.5-7b time: 37.87s, token/s: 9.48
qwen2.5-7b time: 44.05s, token/s: 9.72
qwen2.5-7b time: 30.55s, token/s: 9.23
qwen2.5-7b time: 50.36s, token/s: 9.13
尴尬了,加速比不到 3,jetson gpu 甚至跑不到服务端 cpu 的速度!
看来,想要在端侧跑本地大模型,流式输出是必须的了,我们下篇来聊。
写在最后
终于,我们在 Jetson 上成功利用 GPU 实现了大模型推理加速。
有朋友问:7b 能叫大模型?
是啊,不过在 Ollama 对模型量化的基础上,8G 内存只够装下 7b 模型,还得给本地部署语音识别+语音合成留点内存空间。
本系列文章,会陆续更新 Jetson AI 应用开发的相关教程,欢迎感兴趣的朋友关注。
为方便大家交流,新建了一个 AI 交流群,欢迎对AIoT、AI工具、AI自媒体等感兴趣的小伙伴加入。
最近打造的微信机器人小爱(AI)也在群里,公众号后台「联系我」,拉你进群。

















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









