







本文参考了前人的博客,觉得写的已经很好啦,借鉴过来学习一下。
这里参考的链接如下:
http://blog.csdn.net/xjz18298268521/article/details/52681966
论文:
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
本篇博文主要讲解大神何凯明2014年的paper:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》,这篇paper主要的创新点在于提出了空间金字塔池化。paper主页:http://research.microsoft.com/en-us/um/people/kahe/eccv14sppnet/index.html 这个算法比R-CNN算法的速度快了n多倍。我们知道在现有的CNN中,对于结构已经确定的网络,需要输入一张固定大小的图片,比如224*224、32*32、96*96等。这样对于我们希望检测各种大小的图片的时候,需要经过裁剪,或者缩放等一系列操作,这样往往会降低识别检测的精度,于是paper提出了“空间金字塔池化”方法,这个算法的牛逼之处,在于使得我们构建的网络,可以输入任意大小的图片,不需要经过裁剪缩放等操作,只要你喜欢,任意大小的图片都可以。不仅如此,这个算法用了以后,精度也会有所提高,总之一句话:牛逼哄哄。
1. Introduction
在之前物体检测的文章,比如R-CNN中,他们都要求输入固定大小的图片,这些图片或者经过裁切(Crop)或者经过变形缩放(Warp),都在一定程度上导致图片信息的丢失和变形,限制了识别精确度。两种方式如下所示。

实上,在网络实现的过程中,卷积层是不需要输入固定大小的图片的,而且还可以生成任意大小的特征图,只是全连接层需要固定大小的输入。因此,固定长度的约束仅限于全连接层。在本文中提出了Spatial Pyramid Pooling layer 来解决这一问题,使用这种方式,可以让网络输入任意的图片,而且还会生成固定大小的输出。这样,整体的结构和之前的R-CNN有所不同。

2. Spatital Pyramid Pooling
在解释什么是空间金字塔池化之前,先一下什么是空间金字塔。这里的理解就是以不同大小的块来对图片提取特征,比如下面这张图:
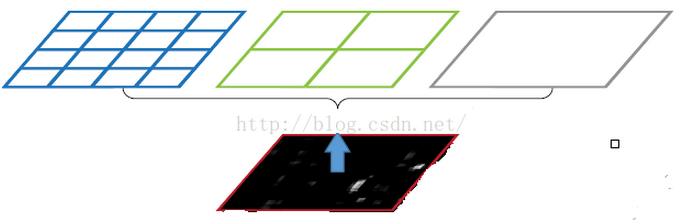
分别是4*4,2*2,1*1大小的块,将这三张网格放到下面这张特征图上,就可以得到16+4+1=21种不同的切割方式,分别在每一个区域取最大池化,那么就可以得到21组特征。这种以不同的大小格子的组合方式来池化的过程就是空间金字塔池化(SPP)。

现在,再来看这张完整的图像,因为卷积层输入的任意大小的图片,所以Conv5计算出的feature map也是任意大小的,现在经过SPP之后,就可以变成固定大小的输出了,以上图为例,一共可以输出(16+4+1)*256的特征,16+4+1表示空间盒的数量(Spatial bins),256则表示卷积核的数量。
3. 物体检测
带有SPP layer的网络叫做SPP-net,它在物体检测上跟R-CNN也有一定的区别。首先是特征提取上,速度提升了好多,R-CNN是直接从原始图片中提取特征,它在每张原始图片上提取2000个Region Proposal,然后对每一个候选区域框进行一次卷积计算,差不多要重复2000次,而SPP-net则是在卷积原始图像之后的特征图上提取候选区域的特征。所有的卷积计算只进行了一次,效率大大提高。
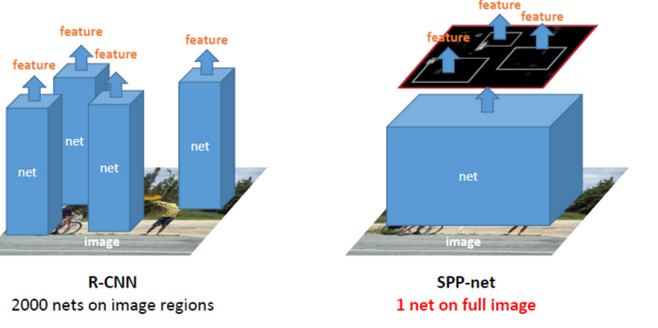
从这张图片上应该可以看到两者之间的计算差别。
4. 算法应用之物体检测
在SPP-Net还没出来之前,物体检测效果最牛逼的应该是RCNN算法了,下面跟大家简单讲一下R-CNN的总算法流程,简单回顾一下:
1、首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。
2、把这2k个候选窗口的图片都缩放到227*227,然后分别输入CNN中,每个候选窗台提取出一个特征向量,也就是说利用CNN进行提取特征向量。
3、把上面每个候选窗口的对应特征向量,利用SVM算法进行分类识别。
可以看到R-CNN计算量肯定很大,因为2k个候选窗口都要输入到CNN中,分别进行特征提取,计算量肯定不是一般的大。
接着回归正题,如何利用SPP-Net进行物体检测识别?具体算法的大体流程如下:
1、首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
2、特征提取阶段。这一步就是和R-CNN最大的区别了,同样是用卷积神经网络进行特征提取,但是SPP-Net用的是金字塔池化。这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后在进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度是大大地快啊。江湖传说可一个提高100倍的速度,因为R-CNN就相当于遍历一个CNN两千次,而SPP-Net只需要遍历1次。
3、最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
算法细节说明:看完上面的步骤二,我们会有一个疑问,那就是如何在feature maps中找到原始图片中候选框的对应区域?因为候选框是通过一整张原始的图片进行检测得到的,而feature maps的大小和原始图片的大小是不同的,feature maps是经过原始图片卷积、下采样等一系列操作后得到的。那么我们要如何在feature maps中找到对应的区域呢?
这个答案可以在文献中的最后面附录中找到答案:
APPENDIX A:Mapping a Window to Feature Maps。这个作者直接给出了一个很方便我们计算的公式:假设(x’,y’)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系:
(x,y)=(S*x’,S*y’)
其中S的就是CNN中所有的strides的乘积。比如paper所用的ZF-5:
S=2*2*2*2=16
而对于Overfeat-5/7就是S=12,这个可以看一下下面的表格:
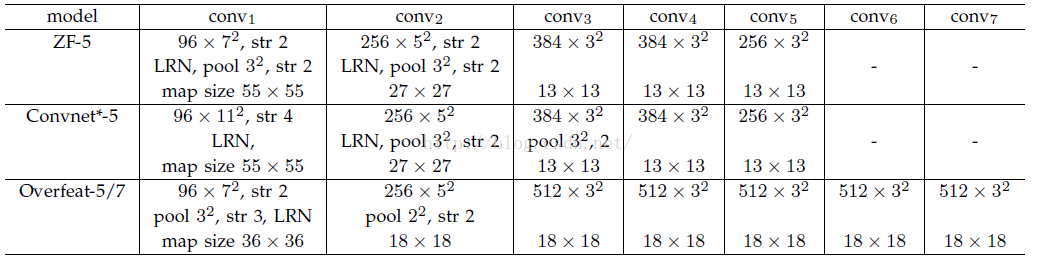
需要注意的是Strides包含了池化、卷积的stride。自己计算一下Overfeat-5/7(前5层)是不是等于12。
反过来,我们希望通过(x,y)坐标求解(x’,y’),那么计算公式如下:
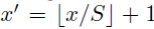
因此我们输入原图片检测到的windows,可以得到每个矩形候选框的四个角点,然后我们再根据公式:
Left、Top: 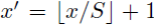
Right、Bottom:


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









