






概述
如果您的代码直接与硬件或其他内核上执行的代码交互,或者直接加载或写入要执行的指令,或者修改页表,则需要注意内存排序问题。
如果您是一名应用程序开发人员,那么硬件交互可能是通过设备驱动程序进行的,与其他内核的交互是通过Pthreads或另一个多线程API进行的,与分页内存系统的交互是通过操作系统进行的。在所有这些情况下,相关代码会为您解决内存排序问题。然而,如果您正在编写操作系统内核或设备驱动程序,或实现虚拟机监控程序、JIT编译器或多线程库,那么您必须对ARM体系结构的内存排序规则有很好的理解。您必须确保,在代码需要显式排序内存访问的地方,您可以通过正确使用屏障来实现这一点。
ARMv8体系结构采用了弱有序的内存模型。一般来说,这意味着内存访问顺序不需要与加载和存储操作的程序顺序相同。处理器能够相互重新排序内存读取操作。写入也可以重新排序(例如,写入合并)。因此,硬件优化(如缓存和写缓冲区的使用)的工作方式可以提高处理器的性能,这意味着可以减少处理器和外部内存之间所需的带宽,并隐藏与此类外部内存访问相关的长延迟。
对正常内存的读写可以通过硬件重新排序,只受数据依赖性和显式内存屏障指令的约束。某些情况需要更严格的排序规则。您可以通过描述该内存的翻译表条目的memory type属性向内核提供有关这方面的信息。
高性能系统可能支持推测性内存读取、多次发出指令或无序执行等技术,这些技术与其他技术一起,为内存访问的硬件重新排序提供了进一步的可能性:
- 多指令:处理器可能会在每个周期发出并执行多条指令,以便可以同时执行按程序顺序排列的指令
- 无序执行:许多处理器支持无序执行非依赖指令。当一条指令在等待前一条指令的结果而被暂停时,处理器可以执行没有依赖关系的后续指令
- 推断:当处理器遇到条件指令(如分支)时,它可以在确定是否必须执行该特定指令之前推测性地开始执行指令。因此,如果条件决定证明猜测是正确的,那么结果将很快出现。
- 推测加载:如果推测性地执行从可缓存位置读取的加载指令,这可能会导致缓存线填充和现有缓存线的潜在逐出。
- 加载和存储优化:由于对外部内存的读写可能有很长的延迟,处理器可以通过将多个存储合并到一个更大的事务中来减少传输次数。
- 外部存储系统:在许多复杂的片上系统(SoC)设备中,有许多代理能够启动传输和到从设备的多条读写路由。其中一些设备,例如DRAM控制器,可能能够同时接受来自不同主机的请求。事务可以通过互连进行缓冲或重新排序。这意味着,来自不同主机的访问可能需要不同数量的周期才能完成,并且可能会相互超越。
- Cache相干多核处理:在多核处理器中,硬件缓存一致性可以在核心之间迁移缓存线。因此,不同的内核可能会以不同的顺序看到缓存内存位置的更新。
- 编译器优化:编译器优化可以重新排序指令以隐藏延迟或充分利用硬件功能。它通常可以向前移动一个内存访问,使之更早,并在需要值之前给它更多的时间来完成。
在单核系统中,这种重新排序的效果对程序员来说通常是透明的,因为单个处理器可以检查风险并确保数据依赖的独立性。然而,如果有多个内核通过共享内存进行通信,或者以其他方式共享数据,那么内存排序考虑就变得更加重要。本章讨论与多处理(MP)操作和多个执行线程的同步相关的几个主题。它还讨论了体系结构定义的内存类型和规则,以及如何控制这些类型和规则。
1、内存类型
ARMv8体系结构定义了两种互斥的内存类型。所有内存区域都配置为这两种类型中的一种或另一种,即普通和设备。第三种内存类型是强有序的,是ARMv7体系结构的一部分。这种类型的内存与设备内存之间的差异很小,因此现在在ARMv8中省略了它。(参见第13-4页的设备存储器。)
除了内存类型之外,属性还提供对可缓存性、可共享性、访问和执行权限的控制。可共享和缓存属性仅适用于普通内存。设备区域始终被视为不可缓存和外部共享。对于可缓存位置,可以使用属性向处理器指示缓存分配策略。
内存类型不会直接编码到翻译表条目中。相反,每个块条目指定一个内存类型表的3位索引。该表存储在内存属性间接寄存器MAIR_ELn中。该表有八个条目,每个条目有八位,如图13-1所示。
尽管翻译表块条目本身并不直接包含内存类型编码,但处理器内的TLB条目通常会存储特定条目的信息。因此,只有在ISB指令屏障和TLB失效操作之后,才能观察到MAIR_ELn的变化。

1.1 普通内存
内存中的所有代码和大多数数据区域使用普通内存。普通内存的示例包括物理内存中的RAM、Flash或ROM。这种内存提供了最高的处理器性能,因为它是弱有序的,并且对处理器的限制较少。处理器可以重新排序、重复和合并对正常内存的访问。
此外,处理器可以推测性地访问被标记为正常的地址位置,这样就可以从内存中读取数据或指令,而无需在程序中显式引用,或者在实际执行显式引用之前。这种推测性访问可能是分支预测、推测性缓存线填充、无序数据加载或其他硬件优化的结果。
为了获得最佳性能,请始终将应用程序代码和数据标记为正常,在需要强制内存排序的情况下,可以通过使用显式屏障操作来实现。普通内存实现弱有序内存模式。对于其他正常访问或设备访问,无需按顺序完成正常访问。
然而,处理器必须始终处理由地址依赖性引起的危险。
例如,考虑下面的简单代码序列:
STR X0, [X2]
LDR X1, [X2]
处理器始终确保X1中的值是写入X2中存储的地址的值。
这当然适用于更复杂的依赖关系,如下
ADD X4, X3, #3
ADD X5, X3, #2
STR X0, [X3]
STRB W1, [X4]
LDRH W2, [X5]
在这种情况下,访问发生在相互重叠的地址上。处理器必须确保内存按照STR和STRB的顺序进行更新,以便LDRH返回最新的值。处理器将STR和STRB合并到一个包含最新正确数据的单一访问中仍然有效。
1.2 设备内存
您可以将设备内存用于访问可能产生副作用的所有内存区域。例如,对FIFO位置或计时器的读取是不可重复的,因为它会为每次读取返回不同的值。写入控制寄存器可能会触发中断。它通常仅用于系统中的外围设备。设备内存类型对内核施加了更多限制。无法对标记为设备的内存区域执行推测性数据访问。这有一个罕见的例外。如果NEON操作用于从设备内存中读取字节,处理器可能会读取未明确引用的字节,如果它们位于一个对齐的16字节块内,该块包含一个或多个明确引用的字节。
试图从标记为设备的区域执行代码通常是不可预测的。该实现可能会处理指令获取,就好像它是到具有正常不可缓存属性的内存位置一样,也可能会出现权限错误。
有四种不同类型的设备内存,适用不同的规则:
- Device-nGnRnE限制最严格(相当于ARMv7体系结构中的强有序内存)
- Device-nGnRE
- Device-nGRE
- Device-GRE最小限制
字母后缀指的是以下三个属性:
聚集或非聚集(G或nG):
此属性确定是否可以将多个访问合并到此内存区域的单个总线事务中。如果地址被标记为非聚集(nG),那么在内存总线上对该位置执行的访问的数量和大小必须与代码中显式访问的数量和大小完全匹配。例如,如果地址标记为正在收集(G),那么处理器可以将两个字节的写入合并为一个半字的写入。
对于标记为聚集的区域,也可以合并对同一内存位置的多个内存访问。例如,如果程序读取同一位置两次,内核只需执行一次读取,就可以为两条指令返回相同的结果。对于从标记为非聚集的区域读取,数据值必须来自终端设备。不能从写入缓冲区或其他位置窥探它。
Re-ordering (R or nR):
这决定了对同一设备的访问是否可以相互重新排序。如果地址被标记为非重新排序(nR),那么同一块中的访问总是以程序顺序出现在总线上。此块的大小由实现定义。如果这个块的大小很大,它可能会跨越多个表条目。在这种情况下,对于也标记为nR的任何其他访问,都要遵守排序规则。
Early Write Acknowledgement (E or nE):
这决定是否允许处理器和被访问的从设备之间的中间写入缓冲区发送写入完成确认。如果地址被标记为非早期写入确认(nE),则写入响应必须来自外围设备。如果地址被标记为早期写入确认(E),则允许互连逻辑中的缓冲器在终端设备实际接收到写入之前发出写入接受信号。这本质上是给外部存储系统的一条信息。
2、Barriers
ARM体系结构包括屏障指令,用于在特定点强制访问顺序和访问完成。在某些体系结构中,类似的指令被称为围栏。
如果您编写的代码排序很重要,请参阅《ARM体系结构参考手册-ARMv8》中的Appendix J7 Barrier Litmus Tests,了解ARMv8-A architecture profile,以及《ARM体系结构参考手册》ARMv7-A/R版中的Appendix G Barrier Litmus Tests,其中包括许多工作示例。
ARM架构参考手册定义了某些关键词,尤其是术语“遵守”和“必须遵守”。在典型的系统中,这定义了主设备的总线接口(例如核心或GPU以及互连)必须如何处理总线事务。只有大师才能观察传输。所有总线事务都由一个主机启动。主设备执行事务的顺序不一定与此类事务在从属设备上完成的顺序相同,因为除非明确执行某些顺序,否则事务可能会由互连重新排序。
描述可观察性的一个简单方法是说,“当我能读到你写的东西时,我观察到了你的写,当我不能再改变你读到的值时,我观察到了你的读”,我和你都指的是系统中的内核或其他主控器。
体系结构提供了三种类型的屏障指令:
- 指令同步屏障(ISB):这用于保证再次获取任何后续指令,以便使用当前MMU配置检查权限和访问权限。它用于确保以前执行的任何上下文更改操作(如写入系统控制寄存器)在ISB完成时已完成。例如,在硬件方面,这可能意味着指令管道被刷新。它的典型用途是内存管理、缓存控制和上下文切换代码,或者在内存中移动代码。指令同步隔离。它最严格,冲洗流水线( Flush Pipeline)和预取buer( pretcLbuffers后,才会从 cache或者内存中预取ISB指令之后的指令。
- 数据存储屏障(DMB):这可以防止数据访问指令跨屏障指令重新排序。在DMB之后的任何数据访问之前,该处理器在DMB之前执行的所有数据访问(即加载或存储,但不是指令获取)对指定共享性域内的所有其他主机都可见。数据存储器隔离。DMB指令保证:仅当所有在它前面的存储器访问操作都执行完毕后,才提交( commit)在它后面的存取访问操作指令。当位于此指令前的所有内存访问均完成时,DMB指令才会完成。
- 数据同步屏障(DSB):比DMB要严格一些,仅当所有在它前面的存储访问操作指令都执行完毕后,才会执行在它后面的指令,即任何指令都要等待DSB前面的存储访问完成。位于此指令前的所有缓存,如分支预测和TLB( Translation Look- aside Buffer)维护操作全部完成。这将强制执行与数据内存屏障相同的顺序,但具有阻止任何进一步指令执行的额外效果,而不仅仅是加载或存储,或两者兼而有之,直到同步完成。例如,这可用于防止执行SEV指令,该指令会向其他内核发出事件发生的信号。它将等待,直到该处理器针对指定的可共享性域发出的所有缓存、TLB和分支预测器维护操作完成。
从以上示例中可以看出,DMB和DSB指令采用一个参数,该参数指定了屏障操作的访问类型、之前或之后,以及它适用的共享性域。如下表:

有序访问字段指定屏障操作的访问类别,有三种选择:
- Load - Load/Store:这意味着屏障需要在屏障之前完成所有load,但不需要完成store。程序顺序中出现在屏障之后的加载和存储都必须等待屏障完成
- Store - Store:这意味着屏障仅影响store访问,而且load仍然可以在屏障周围自由重新排序
- Any - Any:这意味着装载和存储必须在屏障之前完成。程序顺序中出现在屏障之后的加载和存储都必须等待屏障完成
屏障用于防止发生不安全的优化,并强制执行特定的内存顺序。因此,使用不必要的屏障指令可能会降低软件性能。仔细考虑在特定情况下是否需要使用屏障,如果需要,应使用哪种屏障。
排序规则的一个更微妙的影响是,内核的指令接口、数据接口和MMU表遍历器被视为单独的观察者。这意味着,例如,您可能需要使用DSB指令来确保access one接口可以在不同的接口上观察到。
如果执行数据缓存清除和失效指令,例如DCCVAU、X0,则必须在此之后插入DSB指令,以确保后续页表遍历、翻译表条目修改、指令获取或内存中指令更新都能看到新值,如下:

需要DSB来确保维护操作完成,需要ISB来确保这些操作的效果可以通过下面的说明看到。
处理器可能会在任何时候推测性地访问标记为正常的地址。因此,在考虑是否需要屏障时,不要只考虑加载或存储指令生成的显式访问。
2.1 One-way barriers
AArch64使用隐式屏障语义添加了新的加载和存储指令。这些要求按照程序顺序观察隐式屏障前后的所有加载和存储。
- Load-Acquire (LDAR):必须在LDAR之后观察所有加载和存储,这些加载和存储按照程序顺序在LDAR之后,并且与目标地址的可共享域相匹配。
- Store-Release (STLR):STLR之前的所有加载和存储,如果与目标地址的可共享域相匹配,则必须在STLR之前进行观察。
此外,还提供了上述产品的升级版本LDAXR和STLXR。
与数据屏障指令不同,LDAR和STLR指令使用访问地址的属性。数据屏障指令使用限定符来控制哪些共享性域可以看到屏障的效果。
LDAR指令保证LDAR之后的任何内存访问指令仅在加载获取后可见。存储释放保证在存储释放变为可见之前,所有早期的内存访问都是可见的,并且存储对系统中能够同时存储缓存数据的所有部分都是可见的。
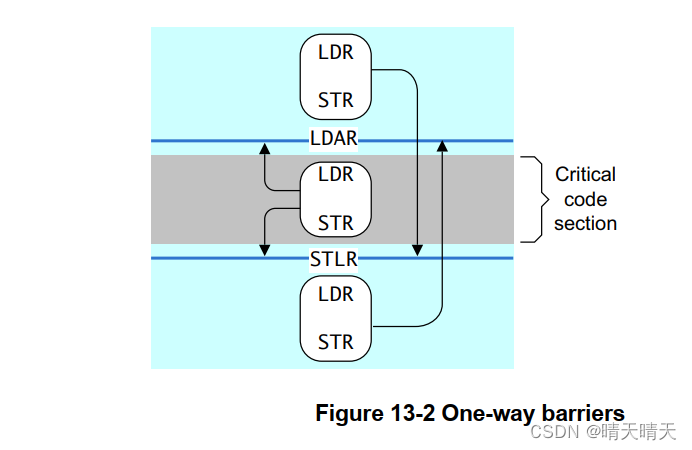
该图显示了通道如何在一个方向上穿过单向屏障,而不是在另一个方向。
2.2 ISB 详解
ARMv8体系结构将上下文定义为系统寄存器的状态,将上下文更改操作定义为缓存、TLB和分支预测器维护操作,或对系统控制寄存器的更改,例如SCTLR_EL1、TCR_EL1和TTBRn_EL1。这种上下文更改操作的效果只能保证在上下文同步事件之后才能看到。
有三种上下文同步事件:
- 触发异常
- 异常返回
- ISB
ISB刷新流水线,并从缓存或内存中重新获取指令,并确保ISB之前完成的任何上下文更改操作的效果对ISB之后的任何指令都可见。它还可以确保ISB指令之后的任何上下文更改操作仅在ISB执行后生效,并且ISB之前的指令不会看到这些操作。这并不意味着在修改处理器寄存器的每条指令之后都需要ISB。例如,对PSTATE字段、ELR、SPs和SPSR的读取或写入按照相对于其他指令的程序顺序进行。
本例显示了如何启用浮点单元和NEON,您可以在AArch64中通过写入CPACR_EL1寄存器的位[20]来实现这一点。ISB是一个上下文同步事件,它保证在执行任何后续指令或NEON指令之前完成启用。
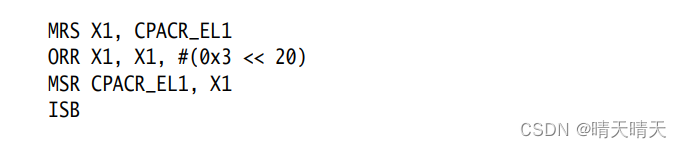
2.3 C语言中使用屏障
C11和C++11语言有一个良好的独立于平台的内存模型。
所有版本的C和C++都有序列点,但C11和C++11也提供了内存模型。序列点只会阻止编译器对C++源代码重新排序。没有什么可以阻止处理器对生成的目标代码中的指令进行重新排序,也没有什么可以阻止读写缓冲区对数据传输发送到缓存的顺序进行重新排序。换句话说,它们只与单线程代码相关。对于多线程代码,可以使用C11/C++11的内存模型功能,也可以使用操作系统提供的其他同步机制,如互斥锁。通常,编译器不能跨序列点重新排列语句,也不能限制编译器可以进行的优化。代码中的序列点示例包括函数调用和对可变变量的访问。
C语言规范对序列点的定义如下:在被称为序列点的执行序列中的某些特定点上,先前评估的所有副作用都应完整,且后续评估不得产生副作用。
Barriers in Linux:Linux内核包括许多独立于平台的屏障函数。请参阅Linux内核文档中内存屏障。更多细节文件位于:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/Documentation/ 。
2.4 非临时加载和存储对
ARMv8中的一个新概念是非时态加载和存储。这些是LDNP和STNP指令,用于读取或写入一对寄存器值。它们还提示内存系统缓存对这些数据没有用处。该提示并不禁止内存系统活动,例如缓存地址、预加载或收集,但只是表明缓存不太可能提高性能。典型的用例可能是流数据,但您应该注意,有效使用这些指令需要一种特定于微体系结构的方法。
非时态加载和存储放宽了内存排序要求。在上述情况下,LDNP指令可能在前面的LDR指令之前被观察到,这可能导致从X0中不可预测的地址读取。

3、内存属性
系统的内存映射被划分为多个区域。每个区域可能需要不同的内存属性,例如访问权限,包括不同权限级别、内存类型和缓存策略的读写权限。在内存映射中,代码和数据的功能片段通常被分组在一起,并且这些区域的属性都是单独控制的。该功能由MMU执行。转换表条目使MMU硬件能够将虚拟地址转换为物理地址。此外,它们还指定了与每个页面关联的多个属性。
图13-3显示了如何在阶段1块条目中指定内存属性。翻译表中的块条目定义了每个内存区域的属性。第二阶段的参赛作品有不同的布局。
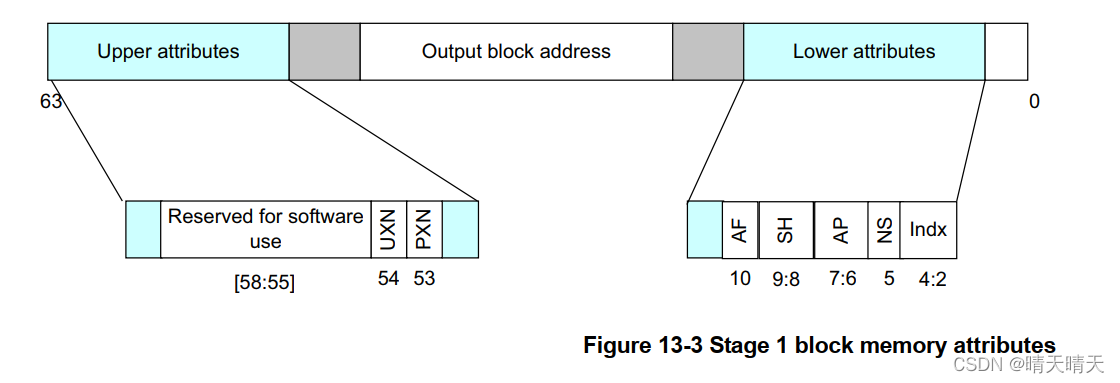
- UXN and PXN 是执行权限
- AF 是访问标记
- SH是共享属性
- AP是访问权限
- NS是安全位,但仅限于EL3和安全EL1
- Indx是内存属性间接寄存器MAIR_ELn的索引
描述符格式支持分层属性,因此一个级别上的属性集可以由较低级别继承。这意味着L0、L1或L2表中的表项可以覆盖它所指向的表中指定的一个或多个属性。这可以用于访问权限、安全性和执行权限。例如,L1表中NSTable=1的条目意味着它指向的L2和L3表中的NS位被忽略,所有条目都被视为NS=1。
此功能仅限制同一翻译阶段的后续查找级别。
3.1 可缓存和可共享内存属性
标记为正常的内存区域可以指定为缓存或非缓存。有关可缓存内存的更多信息,请参阅第14章多核处理器。内存缓存可以通过内部和外部属性分别控制,以实现多级缓存。内部和外部的划分是由实现定义的,但通常内部属性集由集成到处理器中的缓存使用,而外部属性从处理器导出到外部内存总线,因此可能由核心或集群外部的缓存硬件使用。
共享属性用于定义一个位置是否与多个核心共享。将某个区域标记为不可共享意味着它仅由该核心使用,而将其标记为内部可共享或外部可共享,或两者都有,意味着该位置与其他观察者共享,例如,GPU或DMA设备可能被视为另一观察者。同样,内部和外部实现之间的划分也被定义。这些属性的体系结构定义是,它们使我们能够定义一组观察者,共享性属性使数据或统一缓存对数据访问透明。这意味着系统提供硬件一致性管理,以便内部可共享域中的两个核心必须看到标记为内部可共享的位置的一致副本。如果系统中的处理器或其他主机不支持一致性,则必须将可共享区域视为不可缓存。
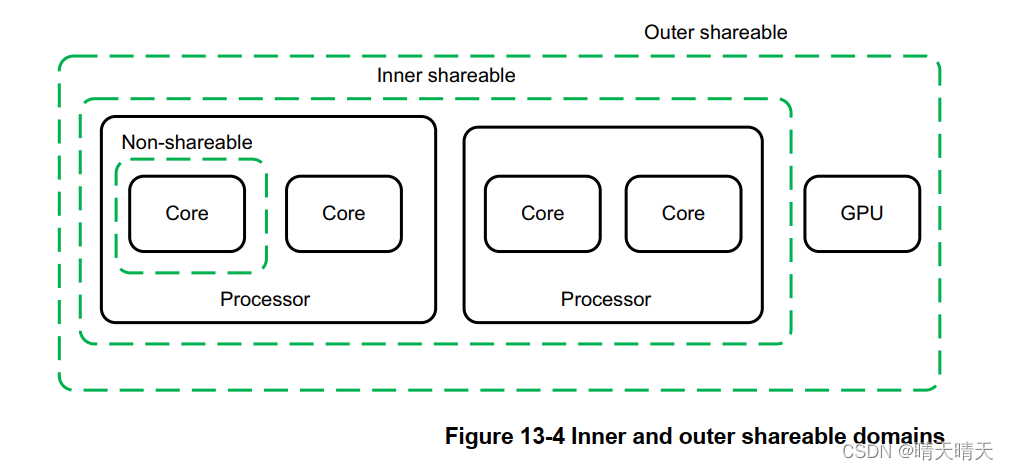
缓存一致性硬件有一定的开销。与其他方式相比,数据内存访问可能需要更长的时间,消耗更多的电力。通过保持较小数量的主控器之间的一致性,并确保它们在硅中物理上紧密相连,可以将这种开销降至最低。出于这个原因,该体系结构将系统划分为多个域,从而可以将开销限制在需要一致性的位置。
以下可共享性域选项可用:
- Non-shareable:这表示只能由单个处理器或其他代理访问内存,因此内存访问不需要与其他处理器同步。此域通常不用于SMP系统。
- 内部共享:这代表了一个可共享性域,可以由多个处理器共享,但不一定是系统中的所有代理共享。一个系统可能有多个内部可共享域。影响一个内部可共享域的操作不会影响系统中的其他内部可共享域。这种结构域的一个例子可能是四核Cortex-A57簇。
- 外部共享:外部可共享(OSH)域重新排序由多个代理共享,可以由一个或多个内部可共享域组成。影响外部可共享域的操作也会隐式影响其中的所有内部可共享域。但是,它不会以其他方式表现为内部可共享操作。
- 全系统:对整个系统(SY)的操作会影响系统中的所有观察者















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









