







1. Mixture Model
- A typical k-dimensional mixture model is a hierarchical model consisting of:
- There are N observations, each observation is a mixture of K components.
- Each component belongs to the same distribution but with different parameters.
- A set of K mixture weights, each of which is a probability, all of which sum to one.
2. Gaussian Mixture Model
- Multivariate (d-dimensional) Gaussian distribution is elaborated in Anomaly Detection.
- A Gaussian mixture model (GMM) is a weighted sum of K components (multivariate) Gaussian distributions as given by:
where wj is the prior probability (weight) that an observation x is derived from the j-th Gaussian distribution:My understanding: a GMM is a linear combination of K Gaussian distributions, hence it is likely to be a mixed Gaussian distribution, given the combination parameters w j, corresponding to the importance of the j-th Gaussain distribution. Put simply, a GMM is a distribution for a variable. When it is applied to clustering problem, each Gaussian component corresponds to one cluster. Hence, each example may be generated by different components with different probabilities. We will not assign each example to a specific cluster, but give a probability that an example is assigned (or due to) a specific Gaussian distribution.
- Examples:
- Problems: given a set of data (i.e., observaitons), and assuming that each of these observations is derived due to an unknown distribution (i.e., GMM), how to estimate the parameters
of the GMM model that best fits the data.
- Solutions: maximize the likelihood
of the data with regard to the model parameters:
However, sine eachis often a small value,the product value will becomes extremely small that overflows the representation capability of a computer (浮点溢出). Hence, we often adopt the log-likelihood function as instead:
Hence, it can be solved by an EM algorithm, which aims to maximize the log-likelihood function.
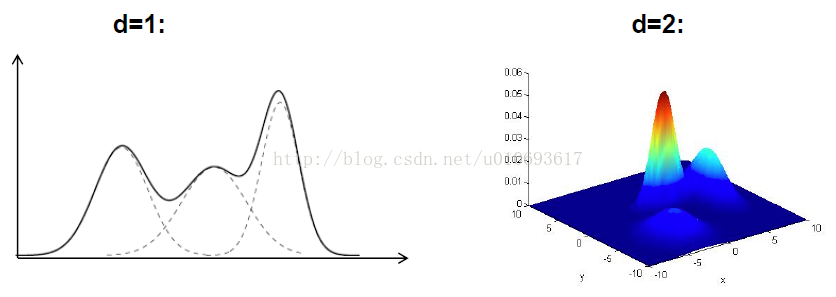
3. EM for GMM
- For GMM, the hidden variable Q will describe which Gaussian generated each example. If Q was observed, then it would be simple to maximize the likelihood of the data: simply estimate the parameters Gaussian by Gaussion. Moreover, we will see we can easily estimate Q.
- The mixture of Gaussian model for each example xi can be written as follows:
- Let us now introduce the following indicator variable:
- We can now write the joint likelihood of all the x and Q:
which in log gives:
- Let us now write the corresponding auxiliary function:
- Hence, the E-step estimates the posterior:
- And the M-step finds the parameters for each parameter (
,
and weights
, note that
). The resultant update parameters are:
Means:Variance:Weights: - EM is very sensitive to initial conditions. Hence, we often use K-means to initialize the EM.
4. Adapted GMM
- In some cases, you have access to only a few examples coming from the target distribution, but many from a nearby distribution.
- In such cases, the maximum a posterior (MAP) adaption is most well-known and used for GMMs.
- Normal maximum likelihood training for a data set x:
- MAP training:
where
represents your prior belief about the distribution of the parameters
- To select a proper distribution, we often use conjugate priors, to ensure the EM algorithm tractable.
- Dirichlet distribution for weights
- Gaussian densities for means and variances.















 4990
4990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









