






原文:Action Recognition by Dense Trajectories
作者:Heng Wang 等
发表于2011年 CVPR
创新点:
第一次将密集轨迹方法引入到动作识别领域;
提出了一种新的与轨迹描述子。
使用密集轨迹进行动作识别的算法流程:
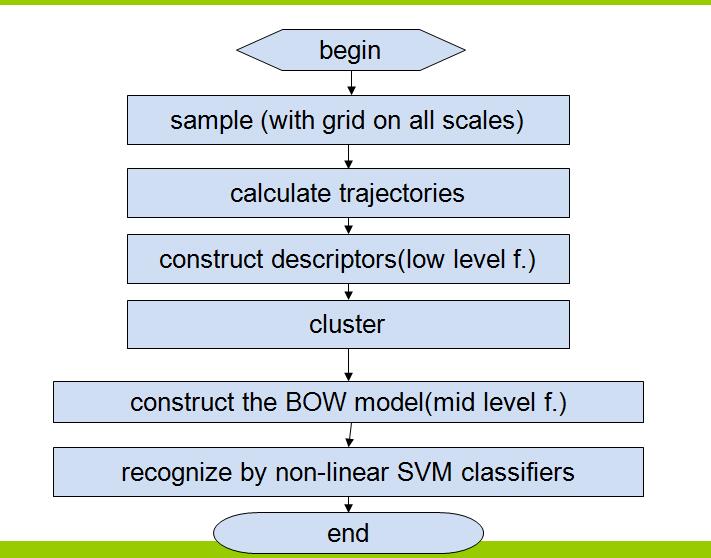
不过本文着重讲前三步,即密集采样,轨迹计算以及轨迹描述子的构建,所以按照文章的内容,接下来详细介绍这三个步骤:
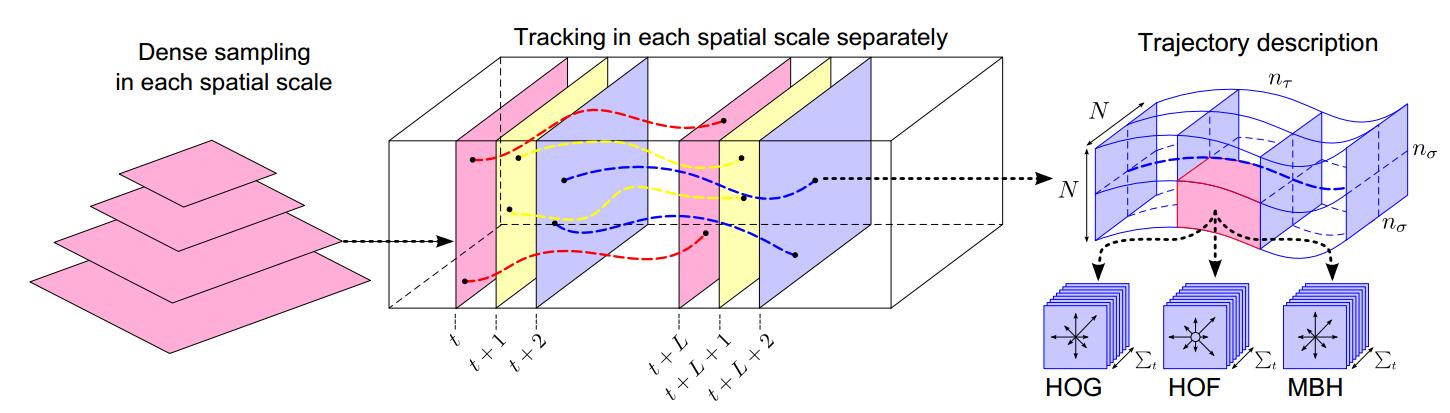
密集采样:
对多个尺度空间使用密集网格进行采样,作者使用八个尺度空间,每两个尺度空间之间的缩放因子为
1/(√2)
;
采样空间示意图如下:
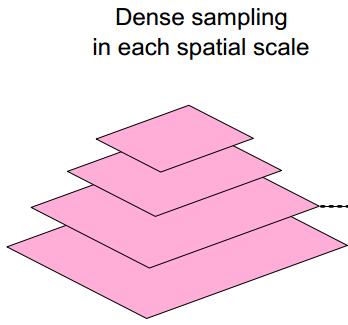
按照作者提供的代码,进行采样时是简单地提取每个网格的中心点。
然后按照Shi和Tomasi在1994你那《Good Features to Track》中的判断标准对采集到的特征点进行去留判断:如果此点对应的自相关矩阵的特征值小于某个阈值(作者通过实验设定的硬阈值),就去掉该点。
轨迹提取
对特征点的跟踪形成轨迹,跟踪是在提前光流场中进行的,迭代方程为:
Pt+1=(xt+1,yt+1)=(xt,yt)+(M∗ω)|(xt′,yt′)
Pt+1为第t+1帧的特征点,M为中值滤波器
ω
为光流场对应数值。(xt’,yt’)为(xt,yt)的近似位置。为了克服轨迹漂移问题,作者将轨迹长度限制为15帧。在后期,静止的轨迹还会被剔除。
在描述轨迹的形状时,作者使用相对位置移动来表达:
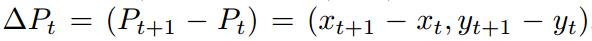
最后经过归一化的轨迹形状描述子为:
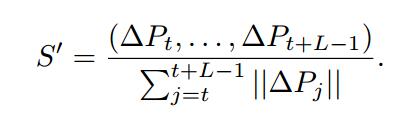
轨迹描述子
作者沿着轨迹,将轨迹邻域划分成更小的子空间,然后对每个子空间构造HOG(描述静态特征),HOF(像素绝对运动特征),MBH(像素相对运动特征)。其中,MBH是作者借鉴他人的工作,第一次将这个特征用到动作识别的领域。
整体的特征点提取到描述子构建流程图如下:
至此,本文章的创新部分已经全部讲完,剩下的就是构建词袋模型,使用支持向量机进行分类,由于使用的都是最一般的方法,所以这里就不介绍了,直接讲他的实验结果:

博主的话:

















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









