








论文:DSSD : Deconvolutional Single Shot Detector
DSSD是2017年的CVPR,二作就是SSD的一作Wei Liu。另外值得一提的是,一作Cheng Yang Fu和Wei Liu大神已经合作发表
好几篇文章。
SSD的作者们对其做的改进肯定会有些方向性,毕竟他们可是深知SSD的优点和缺点啊!
个人的一些见解:
对state of the art的算法进行改进的时候最主要的是找准方向。
大家最常用的思路就是找缺点,比如ssd算法一个比较大的缺点是对小目标不够鲁棒。
但是这种缺点在目前基于CNN的目标检测算法都很常见。无非是有些算法相对好一些而已。
那么,知道了缺点了,如何去改进呐?改进的方法是不是具有普遍性?能不能扩展这种改进方法?
如果能回答了以上这些问题的改进方法,是具有方向性的,就是在此基础上,再做一些工作就可以更进一步的去改进算法。
或者这类改进算法并不是只适应一种算法,比如Faster RCNN中的RPN网络和Anchor 的思想,SPPNet中的SPP layer等等,
这些改进同样适应其他算法,Fast RCNN使用了SPP layer,改进成为了ROI Pooling。
DSSD的贡献:
本文最大的贡献,在常用的目标检测算法中加入上下文信息。通俗点理解就是,基于CNN的目标检测算法基本都是利用一层的
信息(feature map),
比如YOLO,Faster RCNN等。还有利用多层的feature map 来进行预测的,比如ssd算法。那么各层之间的信息的结合并没有
充分的利用。
DSSD算法就是为了解决这个问题的。
DSSD算法的由来:
既然是SSD算法的改进算法,我们先看看SSD算法的一些缺点。
SSD算法的缺点众所周知了,就是对小目标不够鲁棒。我们先分析一下为什么会对小目标不够鲁棒的。
先回忆一下YOLO算法,把检测的图片划分成14*14的格子,在每一个格子中都会提取出目标检测框,最初的时候每一个格子
只会提取出一个目标框,这时问题就很大,因为可能会有两个目标落入一个格子中,那么就会出现漏检。
顺理成章的是,在一个格子中提取出多个检测框来匹配目标,这时我们可以使用Anchor的思路,一个格子中加上6到9个不同的
检测框。
这样就可以匹配大部分目标了。这也算解决了漏检问题了。
但是还是会有问题的,比如我们的9个Anchor比较大的话,比较小的目标就又无法匹配到了。那怎么解决呐?
SSD的思路就是我可以在更潜的一些层(feature map)上,来更好的匹配小目标。换句话说就是把图片分成的格子更小了,
一张图片分成的格子的数目变多了。那么这样再在这些格子中使用Anchor ,这样漏检的概率就会大大减小了。
所以SSD的mAP比YOLO提高了不少。
但是!
在浅层提取的feature map表征能力不够强,也就是浅层的feature map中每个格子也可以判断这个格子中包含的是哪一个
类,但是不够那么确定!
可能会出现混淆。就是框是标对了,但是分类有可能出错,或者置信度不够高,不确定框里面的东西是什么?(有可能是分错
类,也有可能是背景误认为成目标)。
这样同样会出现误检和漏检。这种情况对于小目标出现的概率更高。所以SSD算法对小目标还是不够鲁棒。
那怎么办?
DSSD的网络结构:
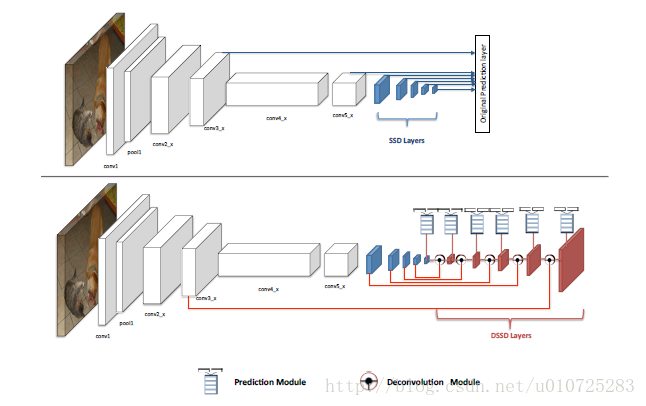
经过以上的分析我们知道,SSD算法对小目标不够鲁棒的最主要的原因是浅层feature map的表征能力不够强。
DSSD就使用了更好的基础网络(ResNet)和Deconvolution层,skip连接来给浅层feature map更好的表征能力。
这也是DSSD算法的核心思想。
具体怎么做?
既然DSSD算法的核心思想就是提高浅层的表征能力,首先想到的肯定是将基础网络由VGG换成ResNet,
更深的网络表征能力就更强这基本成为了大家的共识了。

上表说明了在VGG和ResNet上哪些层作为最后的预测feature layer。如果不明白这张表的话,再仔细看一下SSD的网络结构图
就知道怎么回事了。
另外值得一提的是,这些层可不是随便选的,大致要和VGG对应,且感受野也要对应,这样才能保证效果会提高,要不然反而会
变差也不好说。
看看加上ResNet的SSD的效果。

实验结果很明显,图片大小不够的时候,ResNet的SSD和VGG的SSD效果其实相当,整体甚至还会稍微差一些。
(这里作者没有分析,我对这块也是不明白,为什么呐?欢迎讨论)。
到了512*512的尺度上时,ResNet的下过就明显要好了。尤其是标粗的小目标(bird)。
这也印证了之前的分析,浅层更具有表征能力时,对小目标效果就会更好。
基于ResNet的实验,还没有完,在预测阶段作者同样做了一些工作就是修改一下预测模块。这个灵感作者说是来自MS-CNN指
出改善每个任务的分支网络同样可以提高准确率。
作者使用了四种不同的预测模块。如下图:
Prediction Module :
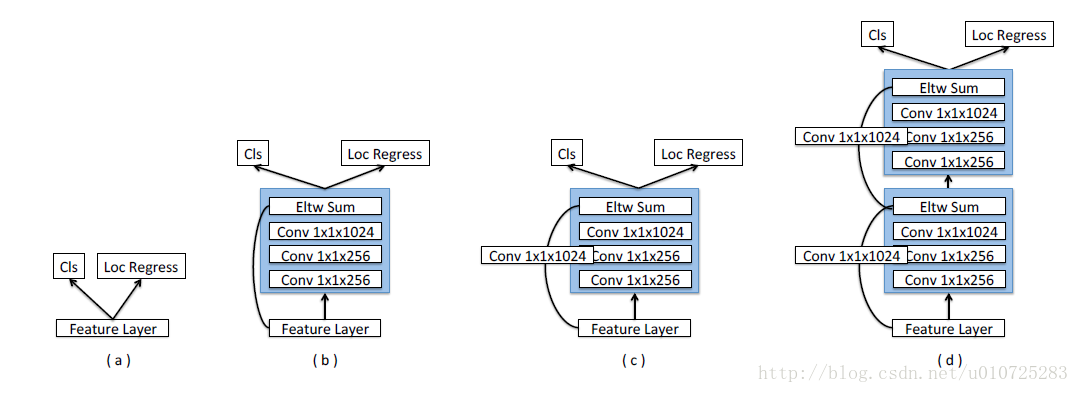
这四个不同的预测模块就不细讲了,其实就是将ResNet进行到底,预测阶段同样是用这个思路。
效果确实得到了提高,如下表:

基于ResNet的实验基本做完了,下面就看这篇文章的最重要的点,Deconvolution模块的使用。
Deconvolution Module:

在第一张图片中的这个小圆就是代表了 Deconvolution Module 。它的结构如下图所示:
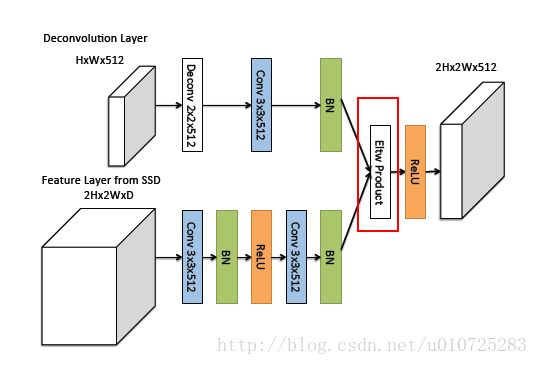
被红色框部分圈住的可以有两种连接方式,Eltw Product其实就是矩阵的点积,还有sum的形式就是求和。
在caffe中的可以用下面的prototxt文件来描述。
- layer {
- name: "fuse"
- type: "Eltwise"
- bottom: "A"
- bottom: "B"
- top: "C"
- eltwise_param {
- operation: SUM
- }
- }
operation参数表明使用哪种操作,SUM是默认操作,就是将A和B相加减。PROD表示点积,MAX求最大值。

如上表,结果是使用prod的效果会更好一点。
将ResNet,Deconvolution Module,Prediction Module结合在一起就是最终的DSSD算法了。
所有新的网络的提出,如果没有讲是如何训练的,我觉得都是在耍流氓。
训练部分作者基本沿用SSD的训练方法。
当然,ResNet要比VGG的收敛速度要快很多。
总结:提高浅层的表征能力,是可以提高类似检测器对小目标的检测能力。按照这个方向走是正确的。
参考:
SSD
MS-CNN:

















 7748
7748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









