







矩阵乘法公式:
( A B ) i j = ∑ k = 1 p a i k b k j = a i 1 b 1 j + a i 2 b 2 j + . . . + a i p b p j (AB)_{ij}=\sum_{k=1}^{p}a_{ik}b_{kj}=a_{i1}b_{1j}+a_{i2}b_{2j}+...+a_{ip}b_{pj} (AB)ij=∑k=1paikbkj=ai1b1j+ai2b2j+...+aipbpj
时间复杂度:
C m ∗ n = A m ∗ k ∗ B k ∗ n C_{m*n}=A_{m*k}*B_{k*n} Cm∗n=Am∗k∗Bk∗n,时间复杂度为O(mkn)
C++代码:
void matrixMulCPU( int * a, int * b, int * c )
{
int val = 0;
for( int row = 0; row < N; ++row )
for( int col = 0; col < N; ++col )
{
val = 0;
for ( int k = 0; k < N; ++k )
val += a[row * N + k] * b[k * N + col];
c[row * N + col] = val;
}
}```
对应的CUDA代码需要先指定线程块数和每个线程块内的线程数
```cpp
dim3 threads_per_block (16, 16, 1); // A 16 x 16 block threads
dim3 number_of_blocks ((N / threads_per_block.x) + 1, (N / threads_per_block.y) + 1, 1);
matrixMulGPU <<< number_of_blocks, threads_per_block >>> ( a, b, c_gpu );
这一块公司的同事和我说CUDA有个建议值,这块代码不需要太多关注,接下来就到了CUDA矩阵乘的代码了
__global__ void matrixMulGPU( int * a, int * b, int * c )
{
int val = 0;
int row = blockIdx.x * blockDim.x + threadIdx.x;
int col = blockIdx.y * blockDim.y + threadIdx.y;
if (row < N && col < N)
{
for ( int k = 0; k < N; ++k )
val += a[row * N + k] * b[k * N + col];
c[row * N + col] = val;
}
}
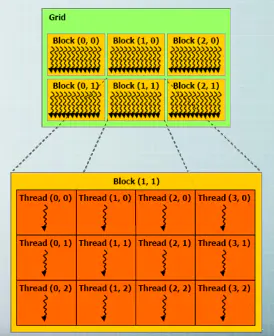
这个地方需要理解CUDA线程结构,我们采用自底向上的方式看
最小的单元是线程(Thread)
接下来是block,每个block中有多个thread,采用二维编号,如上图的橘黄色的thread(2,1)代表该block的第7个线程
再向上一层是grid(格线),每个grid里有多个block,如上图的黄色的block(2,0)
在我们的代码里面我们使用(blockIdx.x * blockDim.x + threadIdx.x,blockIdx.y * blockDim.y + threadIdx.y)来定位到具体的线程,接下来就是具体某个线程执行的代码,从而实现了并行
最后需要使用cudaDeviceSynchronize(); // Wait for the GPU to finish before proceeding等待所有线程都结束,才能继续

Grid最多有3dim,block最多有3dim,上述代码z的维度都是指定的1,所以在CUDA代码中没有提到blockIdx.z
关于这块这个博客讲的挺好
https://blog.csdn.net/dcrmg/article/details/54867507















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









