







基于内容的邮件排序(推荐系统)
这个实例完全是关于建立你自己的推荐系统的。我们将基于如下特征对邮件进行排序:“发送人”、“主题”、“主题中的公共词汇”和“邮件正文中的公共词汇”。稍后我们会对实例中的这些特征一一做解释。注意在设计你自己的推荐系统时,你要自己定义这些特征,而这正是最困难的环节之一。想出合适的特征来非常重要,而且就算最终选好了特征,已有的数据往往可能无法直接利用。
这个实例旨在教你如何选取特征以及解决在这个过程中使用你自己的数据时会遇到的问题。
我们将会使用邮件数据的一个子集,这些邮件数据已在实例“垃圾/正常邮件分类”中使用过了。这个子集可以从这里下载。此外,你还需要停用词文件。注意这些数据是一组接收到的邮件,因此我们还缺少一半数据,也就是这个邮箱发送出去的邮件。然而,就算没有这些信息,我们还是可以做一些相当漂亮的排序工作,待会儿就知道了。
在我们开始建立排序系统之前,我们首先需要从邮件数据集中抽取出尽可能多的数据来。因为这些数据本身有点冗长,我们给出处理这个过程的代码。行内注释对代码的作用进行了解释。注意,该程序一开始就是一个在 GUI 中的 swing 应用。之所以这样做,是因为稍后我们要将数据绘成图以洞悉其隐含的模式。同时注意,我们直接将数据分割为测试数据和训练数据,为我们之后验证模型做准备。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
|
import
java
.
awt
.
{
Rectangle
}
import
java
.
io
.
File
import
java
.
text
.
SimpleDateFormat
import
java
.
util
.
Date
import
smile
.
plot
.
BarPlot
import
scala
.
swing
.
{
MainFrame
,
SimpleSwingApplication
}
import
scala
.
util
.
Try
object
RecommendationSystem
extends
SimpleSwingApplication
{
case
class
EmailData
(
emailDate
:
Date
,
sender
:
String
,
subject
:
String
,
body
:
String
)
def
top
=
new
MainFrame
{
title
=
"Recommendation System Example"
val
basePath
=
"/Users/../data"
val
easyHamPath
=
basePath
+
"/easy_ham"
val
mails
=
getFilesFromDir
(
easyHamPath
)
.
map
(
x
=
>
getFullEmail
(
x
)
)
val
timeSortedMails
=
mails
.
map
(
x
=
>
EmailData
(
getDateFromEmail
(
x
)
,
getSenderFromEmail
(
x
)
,
getSubjectFromEmail
(
x
)
,
getMessageBodyFromEmail
(
x
)
)
)
.
sortBy
(
x
=
>
x
.
emailDate
)
val
(
trainingData
,
testingData
)
=
timeSortedMails
.
splitAt
(
timeSortedMails
.
length
/
2
)
}
def
getFilesFromDir
(
path
:
String
)
:
List
[
File
]
=
{
val
d
=
new
File
(
path
)
if
(
d
.
exists
&&
d
.
isDirectory
)
{
//Remove the mac os basic storage file,
//and alternatively for unix systems "cmds"
//移除mac os的基本存储文件或者unix系统的“cmds”文件
d
.
listFiles
.
filter
(
x
=
>
x
.
isFile
&&
!
x
.
toString
.
contains
(
".DS_Store"
)
&&
!
x
.
toString
.
contains
(
"cmds"
)
)
.
toList
}
else
{
List
[
File
]
(
)
}
}
def
getFullEmail
(
file
:
File
)
:
String
=
{
//Note that the encoding of the example files is latin1,
//thus this should be passed to the from file method.
//注意案例文件采用latin1编码,因此应该把它们传递给fronFile方法
val
source
=
scala
.
io
.
Source
.
fromFile
(
file
)
(
"latin1"
)
val
fullEmail
=
source
.
getLines
mkString
"n"
source
.
close
(
)
fullEmail
}
def
getSubjectFromEmail
(
email
:
String
)
:
String
=
{
//Find the index of the end of the subject line
//找出主题行的结束标志
val
subjectIndex
=
email
.
indexOf
(
"Subject:"
)
val
endOfSubjectIndex
=
email
.
substring
(
subjectIndex
)
.
indexOf
(
'n'
)
+
subjectIndex
//Extract the subject: start of subject + 7
// (length of Subject:) until the end of the line.
//抽取主题:主题开端+7(主题的长度),直到该行结束
val
subject
=
email
.
substring
(
subjectIndex
+
8
,
endOfSubjectIndex
)
.
trim
.
toLowerCase
//Additionally, we check whether the email was a response and
//remove the 're: ' tag, to make grouping on topic easier:
//此外,我们检查邮件是否是一封回复并删除“re:”标签,使对话题的分组更容易
subject
.
replace
(
"re: "
,
""
)
}
def
getMessageBodyFromEmail
(
email
:
String
)
:
String
=
{
val
firstLineBreak
=
email
.
indexOf
(
"nn"
)
//Return the message body filtered by only text
//from a-z and to lower case
//返回过滤后的信息主体,即只包含a-z小写形式的文本
email
.
substring
(
firstLineBreak
)
.
replace
(
"n"
,
" "
)
.
replaceAll
(
"[^a-zA-Z ]"
,
""
)
.
toLowerCase
}
def
getSenderFromEmail
(
email
:
String
)
:
String
=
{
//Find the index of the From: line
//找出带有“From:”标志的行
val
fromLineIndex
=
email
.
indexOf
(
"From:"
)
val
endOfLine
=
email
.
substring
(
fromLineIndex
)
.
indexOf
(
'n'
)
+
fromLineIndex
//Search for the <> tags in this line, as if they are there,
// the email address is contained inside these tags
//在该行中搜索“<>”标签,如果标签存在,则邮件地址包含在其中
val
mailAddressStartIndex
=
email
.
substring
(
fromLineIndex
,
endOfLine
)
.
indexOf
(
'<'
)
+
fromLineIndex
+
1
val
mailAddressEndIndex
=
email
.
substring
(
fromLineIndex
,
endOfLine
)
.
indexOf
(
'>'
)
+
fromLineIndex
if
(
mailAddressStartIndex
>
mailAddressEndIndex
)
{
//The email address was not embedded in <> tags,
// extract the substring without extra spacing and to lower case
//邮件地址不是括在<>标签内,抽取子字符串并去除空格,转为小写形式
var
emailString
=
email
.
substring
(
fromLineIndex
+
5
,
endOfLine
)
.
trim
.
toLowerCase
//Remove a possible name embedded in () at the end of the line,
//for example in test@test.com (tester) the name would be removed here
//删除行末可能包含在()内的名字,例如,在test@test.com(tester) 中,名字会被删除掉
val
additionalNameStartIndex
=
emailString
.
indexOf
(
'('
)
if
(
additionalNameStartIndex
==
-
1
)
{
emailString
.
toLowerCase
}
else
{
emailString
.
substring
(
0
,
additionalNameStartIndex
)
.
trim
.
toLowerCase
}
}
else
{
//Extract the email address from the tags.
//抽取标签中的邮件地址
//If these <> tags are there, there is no () with a name in
// the From: string in our data
//我们的数据中,如果“From:”字符串存在标签<>,则不会有带()的名字出现
email
.
substring
(
mailAddressStartIndex
,
mailAddressEndIndex
)
.
trim
.
toLowerCase
}
}
def
getDateFromEmail
(
email
:
String
)
:
Date
=
{
//Find the index of the Date: line in the complete email
//在整封邮件中找出日期行的标志
val
dateLineIndex
=
email
.
indexOf
(
"Date:"
)
val
endOfDateLine
=
email
.
substring
(
dateLineIndex
)
.
indexOf
(
'n'
)
+
dateLineIndex
//All possible date patterns in the emails.
//邮件中所有可能的日期格式
val
datePatterns
=
Array
(
"EEE MMM dd HH:mm:ss yyyy"
,
"EEE, dd MMM yyyy HH:mm"
,
"dd MMM yyyy HH:mm:ss"
,
"EEE MMM dd yyyy HH:mm"
)
datePatterns
.
foreach
{
x
=
>
//Try to directly return a date from the formatting.
//尝试用一种日期格式直接返回一个日期
//when it fails on a pattern it continues with the next one
// until one works
//对于一种格式,当返回错误时,它接着尝试下一种格式直到成功。
Try
(
return
new
SimpleDateFormat
(
x
)
.
parse
(
email
.
substring
(
dateLineIndex
+
5
,
endOfDateLine
)
.
trim
.
substring
(
0
,
x
.
length
)
)
)
}
//Finally, if all failed return null
//最后,如果都失败了则返回null
//(this will not happen with our example data but without
//this return the code will not compile)
//(对于我们的案例数据,这不会发生,但是没有这一返回,代码就不会编译)
null
}
}
|
这一数据预处理过程非常普遍,并且,一旦你的数据格式不标准,如带有邮件的日期和发送人,那这个过程将会令人非常纠结。不过,给出了这段代码之后,我们的实例数据现在就有了以下这些可用的属性:完整邮件、接收日期、发送人、主题和正文。有了这些,我们得以确定推荐系统实际要用到的特征。
我们建议选取的第一个特征来源于邮件的发送人。那些你经常收到 Ta 邮件的人应该排在那些你很少收到 Ta 邮件的人的前面。这是个很有力的假设,但是你应该会本能地认同我们没有考虑垃圾邮件这件事。我们来看看发送人在整个邮件集上的分布。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
//Add to the top body:
//添加到主体的顶部
//First we group the emails by Sender, then we extract only the sender address
//and amount of emails, and finally we sort them on amounts ascending
//首先我们按发送人给邮件分组,然后只抽取发送人的地址以及邮件数,
//最后按邮件数给这些地址按升序排序
val
mailsGroupedBySender
=
trainingData
.
groupBy
(
x
=
>
x
.
sender
)
.
map
(
x
=
>
(
x
.
_1
,
x
.
_2
.
length
)
)
.
toArray
.
sortBy
(
x
=
>
x
.
_2
)
//In order to plot the data we split the values from the addresses as
//this is how the plotting library accepts the data.
//为了将数据绘图,我们将数值与这些地址分离开,因为绘图库只接收这样的数据
val
senderDescriptions
=
mailsGroupedBySender
.
map
(
x
=
>
x
.
_1
)
val
senderValues
=
mailsGroupedBySender
.
map
(
x
=
>
x
.
_2
.
toDouble
)
val
barPlot
=
BarPlot
.
plot
(
""
,
senderValues
,
senderDescriptions
)
//Rotate the email addresses by -80 degrees such that we can read them
//将邮件地址旋转80度以方便阅读
barPlot
.
getAxis
(
0
)
.
setRotation
(
-
1.3962634
)
barPlot
.
setAxisLabel
(
0
,
""
)
barPlot
.
setAxisLabel
(
1
,
"Amount of emails received "
)
peer
.
setContentPane
(
barPlot
)
bounds
=
new
Rectangle
(
800
,
600
)
|

这里可以看到,给你发送邮件最多的人发了45封,其后是37封,然后就迅速下降了。这些异常值的存在,会导致直接使用这些数据时,推荐系统仅将邮件发送最多的 1 到 2 位发送人列为重要级别,而剩下的则不考虑。为了防止出现这个问题,我们将通过 log1p 函数对数据进行重缩放。 log1p 函数是将数据加 1,然后再对其取对数 log。将数据加 1 的操作是考虑到发送人只发送一封邮件的情况。在对数据进行这样一个取对数操作之后,其图像是这样的。
|
1
2
3
4
5
6
7
8
9
|
//Code changes:
//代码更新
val
mailsGroupedBySender
=
trainingData
.
groupBy
(
x
=
>
x
.
sender
)
.
map
(
x
=
>
(
x
.
_1
,
Math
.
log1p
(
x
.
_2
.
length
)
)
)
.
toArray
.
sortBy
(
x
=
>
x
.
_2
)
barPlot
.
setAxisLabel
(
1
,
"Amount of emails received on log Scale "
)
|

事实上,这些数据仍是相同的,只不过用了不同的比例来展示。注意数据的数值范围在 0.69 与 3.83 之间。这个范围小了很多,异常值也不会太偏离其他数据。在机器学习领域,这种数据操作技巧是很常用的。找到合适的缩放比例需要某种洞察力。所以,在做重缩放时,应用 Smile 的绘图库画出多幅不同缩放比例的图,会给工作带来很大的帮助。
下一个我们要分析的特征是主题出现的频率和时段。如果一个主题经常出现,那它有可能更重要。此外,我们还考虑了一个邮件会话的持续时间。因此,一个主题的频率可以用这个主题下邮件会话的持续时间来标准化。这样,高度活跃的邮件会话会被排在最前面,再次强调,这也是我们的一个假设。
我们来看看这些主题和它们的出现次数:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
//Add to 'def top'
//添加到‘def top’
val
mailsGroupedByThread
=
trainingData
.
groupBy
(
x
=
>
x
.
subject
)
//Create a list of tuples with (subject, list of emails)
//创建一列元组(主题,邮件列表)
val
threadBarPlotData
=
mailsGroupedByThread
.
map
(
x
=
>
(
x
.
_1
,
x
.
_2
.
length
)
)
.
toArray
.
sortBy
(
x
=
>
x
.
_2
)
val
threadDescriptions
=
threadBarPlotData
.
map
(
x
=
>
x
.
_1
)
val
threadValues
=
threadBarPlotData
.
map
(
x
=
>
x
.
_2
.
toDouble
)
//Code changes in 'def top'
//改变的‘def top’代码
val
barPlot
=
BarPlot
.
plot
(
threadValues
,
threadDescriptions
)
barPlot
.
setAxisLabel
(
1
,
"Amount of emails per subject"
)
|
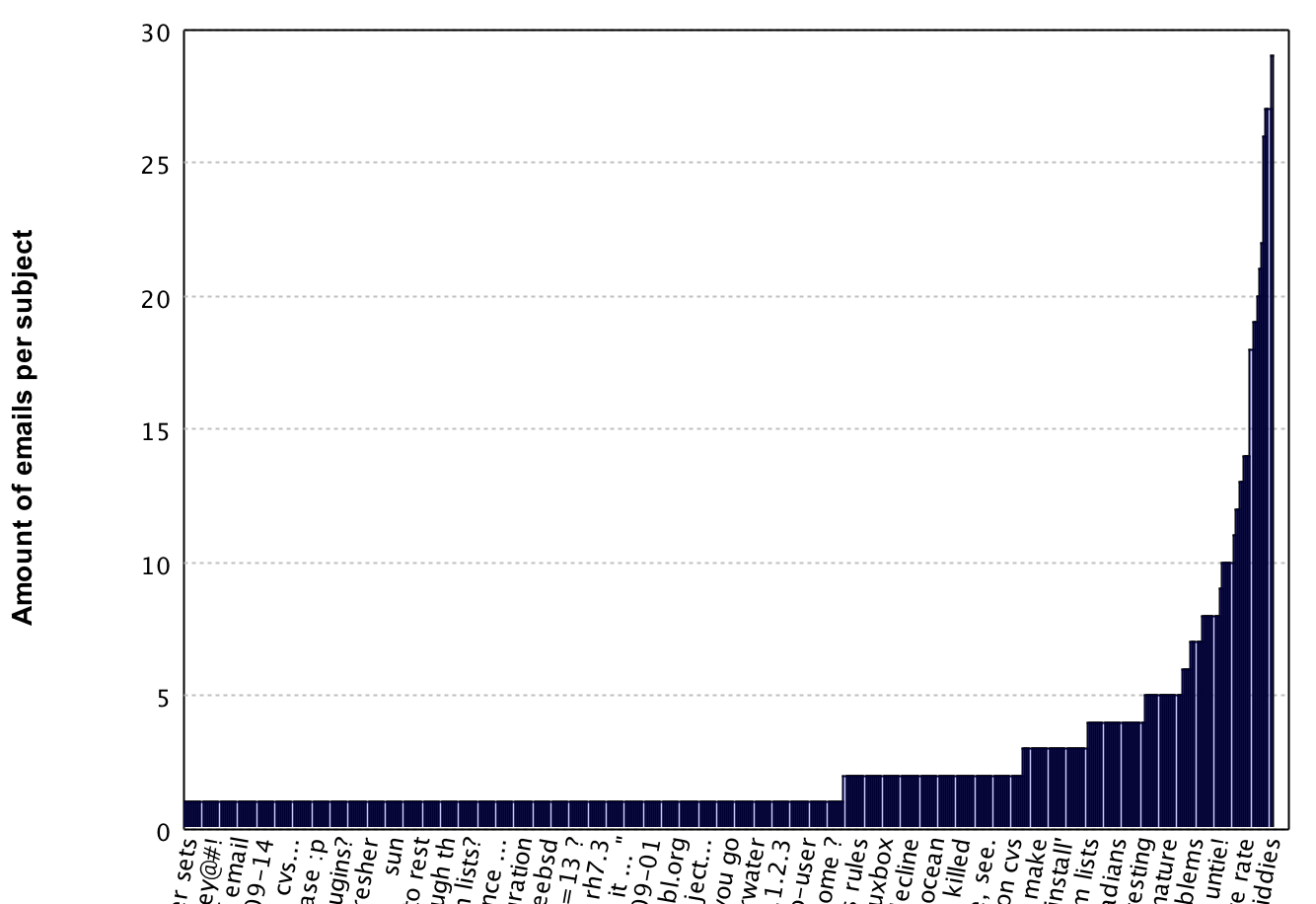
可以看出这与发送人的情况有类似的分布,因此我们再一次应用 log1p 函数。
|
1
2
3
4
5
6
|
//Code change:
//代码更新
val
threadBarPlotData
=
mailsGroupedByThread
.
map
(
x
=
>
(
x
.
_1
,
Math
.
log1p
(
x
.
_2
.
length
)
)
)
.
toArray
.
sortBy
(
x
=
>
x
.
_2
)
|

现在,每个主题的邮件数的取值范围变为 0.69 到 3.41,对推荐系统来说,这比 1 到 29 的范围要好。不过,我们还没有把时间段考虑进去,因此我们回到标准频率上来,着手对数据作变换。为此,我们首先要获取每个邮件会话中,第一个邮件到最后一个邮件的时间间隔:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
//Create a list of tuples with (subject, list of emails,
//time difference between first and last email)
//创建一列元组(主题,邮件列表,首末两封邮件的时间间隔)
val
mailGroupsWithMinMaxDates
=
mailsGroupedByThread
.
map
(
x
=
>
(
x
.
_1
,
x
.
_2
,
(
x
.
_2
.
maxBy
(
x
=
>
x
.
emailDate
)
.
emailDate
.
getTime
-
x
.
_2
.
minBy
(
x
=
>
x
.
emailDate
)
.
emailDate
.
getTime
)
/
1000
)
)
//turn into a list of tuples with (topic, list of emails,
// time difference, and weight) filtered that only threads occur
//转换为一列过滤后的元组(话题,邮件列表,时间间隔,权重),其中只出现邮件对话
val
threadGroupedWithWeights
=
mailGroupsWithMinMaxDates
.
filter
(
x
=
>
x
.
_3
!=
0
)
.
map
(
x
=
>
(
x
.
_1
,
x
.
_2
,
x
.
_3
,
10
+
Math
.
log10
(
x
.
_2
.
length
.
toDouble
/
x
.
_3
)
)
)
.
toArray
.
sortBy
(
x
=
>
x
.
_4
)
val
threadGroupValues
=
threadGroupedWithWeights
.
map
(
x
=
>
x
.
_4
)
val
threadGroupDescriptions
=
threadGroupedWithWeights
.
map
(
x
=
>
x
.
_1
)
//Change the bar plot code to plot this data:
//改变条形图代码以将这些数据绘图
val
barPlot
=
BarPlot
.
plot
(
threadGroupValues
,
threadGroupDescriptions
)
barPlot
.
setAxisLabel
(
1
,
"Weighted amount of emails per subject"
)
|
注意代码中我们是如何确定时间差的,并将其除以 1000。这是为了把时间单位从毫秒化成秒。此外,我们用一个主题的频率除以时间差来计算权重。因为该值很小,我们对其取 log10 函数以使它放大一些。但这样做会把数值变负数,因此,我们将每个数值都加上 10 使其为正数。这个加权过程的结果如下:

我们想要的数值大概落在 4.4 到 8.6 的范围,这表明异常值对特征的影响已经很小。此外,我们观察权重最高的 10 个主题和最低的 10 个主题,看看到底发生了什么。
权重最高的 10 个主题

权重最低的 10 个主题

可以看到,权重最高的是那些短时间内就收到回复的邮件,而权重最低的则是那些回复等待时间很长的邮件。这样的话,即使是那些频率很低的主题也可以根据其往来邮件之间时间间隔短而被排在重要的位置。因此,我们可以得到两个特征:来自发送人的邮件数量 mailsGroupedBySender 和属于一个已知邮件会话的邮件的权重 threadGroupedWithWeights。
如前所述,我们的排序系统是要基于尽可能多的特征的,我们继续找下一个特征。这个特征是以我们刚刚计算出的权重值为基础的。我们的想法是,邮箱会收到带有不同主题的新邮件。不过,这些邮件的主题有可能含有类似于之前收到的重要邮件主题的关键词。因此,在一个邮件会话(一个主题下的多封往来邮件)开始之前,我们就能够将邮件排序。为此,我们把关键词的权重指定为含有这些关键词的主题的权重。如果多个主题都含有这些关键词,我们就选择权重最高的一个排在第一位。
这个特征有个问题,那就是停用词。还好,目前我们有一个停用词文件可以让我们剔除(大部分)英语停用词。然而,当你在设计自己的系统时,还应该考虑到可能会有多种语言出现,这时你就要剔除所有这些语言的停用词了。此外,在不同的语言中,某些单词会有多种不同的意思,因此,在这种情况下剔除停用词就要小心了。就现在来说,我们继续剔除英语停用词。这个特征的代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
def
getStopWords
:
List
[
String
]
=
{
val
source
=
scala
.
io
.
Source
.
fromFile
(
new
File
(
"/Users/../stopwords.txt"
)
)
(
"latin1"
)
val
lines
=
source
.
mkString
.
split
(
"n"
)
source
.
close
(
)
lines
.
toList
}
//Add to top:
//添加到顶部
val
stopWords
=
getStopWords
val
threadTermWeights
=
threadGroupedWithWeights
.
toArray
.
sortBy
(
x
=
>
x
.
_4
)
.
flatMap
(
x
=
>
x
.
_1
.
replaceAll
(
"[^a-zA-Z ]"
,
""
)
.
toLowerCase
.
split
(
" "
)
.
filter
(
_
.
nonEmpty
)
.
map
(
y
=
>
(
y
,
x
.
_4
)
)
)
val
filteredThreadTermWeights
=
threadTermWeights
.
groupBy
(
x
=
>
x
.
_1
)
.
map
(
x
=
>
(
x
.
_1
,
x
.
_2
.
maxBy
(
y
=
>
y
.
_2
)
.
_2
)
)
.
toArray
.
sortBy
(
x
=
>
x
.
_1
)
.
filter
(
x
=
>
!
stopWords
.
contains
(
x
.
_1
)
)
|
给定这段代码,我们就得到了一张列表 filteredThreadTermWeights,该列表基于已有邮件会话中的权重列出了一些关键词。这些权重可以用来计算新邮件的主题的权重,即使这封邮件不是对已有会话的回复。
对于第四个特征,我们打算合并考虑在所有邮件中出现频率很高的词汇的权重。为此,我们要创建一个 TDM,不过这一次和前一个例子中的有点不同,这次,我们只将所有文档中的词汇频率取对数。此外,我们还要对出现率取 log10 函数。这么做可以缩小词汇频率的比例,防止结果被可能的异常值影响。
|
1
2
3
4
5
6
|
val
tdm
=
trainingData
.
flatMap
(
x
=
>
x
.
body
.
split
(
" "
)
)
.
filter
(
x
=
>
x
.
nonEmpty
&&
!
stopWords
.
contains
(
x
)
)
.
groupBy
(
x
=
>
x
)
.
map
(
x
=
>
(
x
.
_1
,
Math
.
log10
(
x
.
_2
.
length
+
1
)
)
)
.
filter
(
x
=
>
x
.
_2
!=
0
)
|
这个 TDM 列表可以帮助我们根据历史数据计算新邮件正文的权重,这个权重很重要。
准备了这 4 个特征之后,我们就可以对训练数据做实际的排序计算。为此,我们要计算出每封邮件的 senderWeight (代表发送人的权重)、termWeight (代表主题词汇的权重)、threadGroupWeight (代表邮件会话的权重)以及 commonTermsWeight (代表邮件正文的权重),并将它们相乘以得到最后的排序。由于我们是做乘法而不是加法,我们需要小心那些小于1的数值。例如,有人发送了一封邮件,那么其 sengerWeight 就是 0.69,若将其与那些还未发送过任何邮件的人作比较就会不公平,因为对方的 senderWeight 值是 1。因此,对于那些数值可能低于 1 的各个特征,我们取函数 Math.max(value,1)。我们来看看代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
val
trainingRanks
=
trainingData
.
map
(
mail
=
>
{
//Determine the weight of the sender, if it is lower than 1, pick 1 instead
//确定发送人的权重,如果小于1,则设为1
//This is done to prevent the feature from having a negative impact
//这是为了防止特征出现负面影响
val
senderWeight
=
mailsGroupedBySender
.
collectFirst
{
case
(
mail
.
sender
,
x
)
=
>
Math
.
max
(
x
,
1
)
}
.
getOrElse
(
1.0
)
//Determine the weight of the subject
//确定主题的权重
val
termsInSubject
=
mail
.
subject
.
replaceAll
(
"[^a-zA-Z ]"
,
""
)
.
toLowerCase
.
split
(
" "
)
.
filter
(
x
=
>
x
.
nonEmpty
&&
!
stopWords
.
contains
(
x
)
)
val
termWeight
=
if
(
termsInSubject
.
size
>
0
)
Math
.
max
(
termsInSubject
.
map
(
x
=
>
{
tdm
.
collectFirst
{
case
(
y
,
z
)
if
y
==
x
=
>
z
}
.
getOrElse
(
1.0
)
}
)
.
sum
/
termsInSubject
.
length
,
1
)
else
1.0
//Determine if the email is from a thread,
//and if it is the weight from this thread:
//判断邮件是否来自一个会话,如果是,其在该会话的权重:
val
threadGroupWeight
:
Double
=
threadGroupedWithWeights
.
collectFirst
{
case
(
mail
.
subject
,
_
,
_
,
weight
)
=
>
weight
}
.
getOrElse
(
1.0
)
//Determine the commonly used terms in the email and the weight belonging to it:
//确定邮件中的常用词汇及其权重:
val
termsInMailBody
=
mail
.
body
.
replaceAll
(
"[^a-zA-Z ]"
,
""
)
.
toLowerCase
.
split
(
" "
)
.
filter
(
x
=
>
x
.
nonEmpty
&&
!
stopWords
.
contains
(
x
)
)
val
commonTermsWeight
=
if
(
termsInMailBody
.
size
>
0
)
Math
.
max
(
termsInMailBody
.
map
(
x
=
>
{
tdm
.
collectFirst
{
case
(
y
,
z
)
if
y
==
x
=
>
z
}
.
getOrElse
(
1.0
)
}
)
.
sum
/
termsInMailBody
.
length
,
1
)
else
1.0
val
rank
=
termWeight *
threadGroupWeight *
commonTermsWeight *
senderWeight
(
mail
,
rank
)
}
)
val
sortedTrainingRanks
=
trainingRanks
.
sortBy
(
x
=
>
x
.
_2
)
val
median
=
sortedTrainingRanks
(
sortedTrainingRanks
.
length
/
2
)
.
_2
val
mean
=
sortedTrainingRanks
.
map
(
x
=
>
x
.
_2
)
.
sum
/
sortedTrainingRanks
.
length
|
我们计算了训练集中所有邮件的排序,还将它们做了排序并取中位数和平均值。我们取中位数和平均值是为了确定一个决策边界,通过该边界来评估一封邮件是优先级还是非优先级。在实践中,这个办法通常并不管用。实际上最好的办法是让用户标记一组邮件作为优先级,与另一组邮件作为非优先级。然后就可以用这些邮件的排序来计算出决策边界,此外还可以确认排序系统的特征是否选得正确。如果最终用户标记为非优先级的邮件评级比标记为优先级的邮件还高,那你可能要重新评估你所选取的特征。
我们之所以提出这个决策边界,而不是仅仅对用户邮件进行排序,是考虑了时间这个因素。如果你纯粹根据排序来整理邮件,那结果将会令人讨厌,因为人们通常喜欢根据时间来整理邮件。然而,假设我们要把这一排序系统融合到一个邮件客户端中,有了这个决策边界之后,我们就可以标记优先级邮件,然后把它们单独显示在一个列表中。
我们来看看在训练集中,有多少封邮件被标记为优先级。为此,我们首先需要添加下列代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
val
testingRanks
=
trainingData
.
map
(
mail
=
>
{
//mail contains (full content, date, sender, subject, body)
//包含(全部内容、日期、发送人、主题、正文)的邮件
//Determine the weight of the sender
//确定发送人的权重
val
senderWeight
=
mailsGroupedBySender
.
collectFirst
{
case
(
mail
.
sender
,
x
)
=
>
Math
.
max
(
x
,
1
)
}
.
getOrElse
(
1.0
)
//Determine the weight of the subject
//确定主题的权重
val
termsInSubject
=
mail
.
subject
.
replaceAll
(
"[^a-zA-Z ]"
,
""
)
.
toLowerCase
.
split
(
" "
)
.
filter
(
x
=
>
x
.
nonEmpty
&&
!
stopWords
.
contains
(
x
)
)
val
termWeight
=
if
(
termsInSubject
.
size
>
0
)
Math
.
max
(
termsInSubject
.
map
(
x
=
>
{
tdm
.
collectFirst
{
case
(
y
,
z
)
if
y
==
x
=
>
z
}
.
getOrElse
(
1.0
)
}
)
.
sum
/
termsInSubject
.
length
,
1
)
else
1.0
//Determine if the email is from a thread,
//and if it is the weight from this thread:
//判断一封邮件是否来自一个会话,如果是,其在该会话的权重:
val
threadGroupWeight
:
Double
=
threadGroupedWithWeights
.
collectFirst
{
case
(
mail
.
subject
,
_
,
_
,
weight
)
=
>
weight
}
.
getOrElse
(
1.0
)
//Determine the commonly used terms in the email and the weight belonging to it:
//确定邮件中的常用词汇及其权重:
val
termsInMailBody
=
mail
.
body
.
replaceAll
(
"[^a-zA-Z ]"
,
""
)
.
toLowerCase
.
split
(
" "
)
.
filter
(
x
=
>
x
.
nonEmpty
&&
!
stopWords
.
contains
(
x
)
)
val
commonTermsWeight
=
if
(
termsInMailBody
.
size
>
0
)
Math
.
max
(
termsInMailBody
.
map
(
x
=
>
{
tdm
.
collectFirst
{
case
(
y
,
z
)
if
y
==
x
=
>
z
}
.
getOrElse
(
1.0
)
}
)
.
sum
/
termsInMailBody
.
length
,
1
)
else
1.0
val
rank
=
termWeight *
threadGroupWeight *
commonTermsWeight *
senderWeight
(
mail
,
rank
)
}
)
val
priorityEmails
=
testingRanks
.
filter
(
x
=
>
x
.
_2
>=
mean
)
println
(
priorityEmails
.
length
+
" ranked as priority"
)
|
在实际执行了这个测试代码以后,你将看到这个测试集被标记为优先级的邮件数量实际是 563,占到测试集邮件数的 45%。这是一个相当大的值,所以我们可以用决策边界进行调节。不过,我们仅以此作为说明的目的,这个值并不应该拿去代表实际情况,所以我们就不再去纠结那个百分比。反之,我们来看看优先级邮件中评级最高的10封。
注意我已经将电子邮件地址的部分内容删除了,以防止垃圾邮件程序抓取这些地址。从下表中可以看到,这10封优先级最高的邮件中,大部分邮件都来自不同的会话,这些会话的活动性很高。以评级最高的那封邮件为例,这封邮件是一封9分钟前的邮件的回复。这就表明了这个邮件会话的重要性。

此外,我们还看到 tim.One… 在这个表中出现很多次。这反映出他的所有邮件都很重要,或者,他发送了这么多邮件以致排序系统自动将其评为优先。作为这个实例的最后一步,我们对这一点再做些讨论:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
val
timsEmails
=
testingRanks
.
filter
(
x
=
>
x
.
_1
.
sender
==
"tim.one@..."
)
.
sortBy
(
x
=
>
-
x
.
_2
)
timsEmails
.
foreach
(
x
=
>
println
(
"| "
+
x
.
_1
.
emailDate
+
" | "
+
x
.
_1
.
subject
+
" | "
+
df
.
format
(
x
.
_2
)
+
" |"
)
)
|
运行这一段代码后,一个包含 45 封邮件的列表就会被打印出来,评级最低的 10 封邮件如下:

我们知道决策边界就是平均值,这里是 25.06,那么可以看出,Tim 只有一封邮件没有被标记为优先级。这表明,一方面,我们的决策边界太低了,而另一方面,Tim也许真的发送了很多重要邮件,否则很多邮件的评级就会低于决策边界。不幸的是,我们无法为你提供确切的答案,因为我们不是这些测试数据的原主人。
当你手中的数据并非一手数据时,验证一个像这样的排序系统是相当困难的。验证并改善这个系统最常用的方式是将它开放给客户使用,让他们标记、纠正错误。而这些纠错就可以用来改善系统。
总的来说,我们介绍了如何从含有异常值的原始数据中获取特征,以及如何把这些特征耦合到最终的排序值中。此外,我们还尝试对这些特征进行验证,但由于缺乏对数据集的确切把握,我们无法得出明确的结论。不过,如果你想使用自己的直接数据进行同样的过程,那么这个实例就可以帮助你建立自己的排序系统。
根据身高预测体重(应用普通最小二乘法)
在这部分中,我们将介绍普通最小二乘法,它是一种线性回归方法。因为这种方法十分强大,所以开始实例之前,有必要先了解回归与常见的陷阱。我们将在这部分介绍一部分这些问题,其他的相关问题我们已在欠拟合与过拟合这两小节中介绍过了。
线性回归的基本思想是用一条“最优的”回归线来拟合数据点。注意这只对线性数据并且无过大异常值的情况才适用。如果你的数据不满足这种条件,那你可以尝试对数据进行操作,例如将数据取平方或取对数,直到满足适用条件。
与往常一样,在一项工程开始时,首先要导入一个数据集。为此,我们提供了如下 csv 文件以及读取文件用的代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
def
getDataFromCSV
(
file
:
File
)
:
(
Array
[
Array
[
Double
]
]
,
Array
[
Double
]
)
=
{
val
source
=
scala
.
io
.
Source
.
fromFile
(
file
)
val
data
=
source
.
getLines
(
)
.
drop
(
1
)
.
map
(
x
=
>
getDataFromString
(
x
)
)
.
toArray
source
.
close
(
)
var
inputData
=
data
.
map
(
x
=
>
x
.
_1
)
var
resultData
=
data
.
map
(
x
=
>
x
.
_2
)
return
(
inputData
,
resultData
)
}
def
getDataFromString
(
dataString
:
String
)
:
(
Array
[
Double
]
,
Double
)
=
{
//Split the comma separated value string into an array of strings
//把用逗号分隔的数值字符串分解为一个字符串数组
val
dataArray
:
Array
[
String
]
=
dataString
.
split
(
','
)
var
person
=
1.0
if
(
dataArray
(
0
)
==
""
Male
""
)
{
person
=
0.0
}
//Extract the values from the strings
//从字符串中抽取数值
//Since the data is in US metrics
//inch and pounds we will recalculate this to cm and kilo's
//因数据是采用美制单位英寸和磅,我们要将它们转换为厘米和千克
val
data
:
Array
[
Double
]
=
Array
(
person
,
dataArray
(
1
)
.
toDouble *
2.54
)
val
weight
:
Double
=
dataArray
(
2
)
.
toDouble *
0.45359237
//And return the result in a format that can later easily be used to feed to Smile
//并以一定格式返回结果,使得该结果之后容易输入到Smile中处理
return
(
data
,
weight
)
}
|
注意,该数据读取器将数值从英制单位转换为公制单位。这对 OLS 的应用没有什么大影响,不过我们还是采用更为常用的公制单位。
这样操作之后我们得到一个数组 Array[Array[Double]],该数组包含了数据点和 Array[Double] 值,该值代表男性或女性。这种格式既有利于将数据绘图,也有利于将数据导入机器学习算法中。
我们首先看看数据是什么样的。为此,用下列代码将数据绘成图。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
object
LinearRegressionExample
extends
SimpleSwingApplication
{
def
top
=
new
MainFrame
{
title
=
"Linear Regression Example"
val
basePath
=
"/Users/.../OLS_Regression_Example_3.csv"
val
testData
=
getDataFromCSV
(
new
File
(
basePath
)
)
val
plotData
=
(
testData
.
_1
zip
testData
.
_2
)
.
map
(
x
=
>
Array
(
x
.
_1
(
1
)
,
x
.
_2
)
)
val
maleFemaleLabels
=
testData
.
_1
.
map
(
x
=
>
x
(
0
)
.
toInt
)
val
plot
=
ScatterPlot
.
plot
(
plotData
,
maleFemaleLabels
,
'@'
,
Array
(
Color
.
blue
,
Color
.
green
)
)
plot
.
setTitle
(
"Weight and heights for male and females"
)
plot
.
setAxisLabel
(
0
,
"Heights"
)
plot
.
setAxisLabel
(
1
,
"Weights"
)
peer
.
setContentPane
(
plot
)
size
=
new
Dimension
(
400
,
400
)
}
|
如果你执行上面这段代码,就会弹出一个窗口显示以下右边那幅图像。注意当代码运行时,你可以滚动鼠标来放大和缩小图像。


在这幅图像中,绿色代表女性,蓝色代表男性,可以看到,男女的身高和体重有很大部分是重叠的。因此,如果我们忽略男女性别,数据看上去依旧是呈线性的(如左图所示)。然而,若不考虑男女性别差异,模型就不够精确。
在本例中,找出这种区别(将数据依性别分组)是小事一桩,然而,你可能会碰到一些其中的数据区分不那么明显的数据集。意识到这种可能性对数据分组是有帮助的,从而有助于改善机器学习应用程序的性能。
既然我们已经考察过数据,也知道我们确实可以建立一条回归线来拟合数据,现在就该训练模型了。Smile 库提供了普通最小二乘算法,我们可以用如下代码轻松调用:
|
1
|
val
olsModel
=
new
OLS
(
testData
.
_1
,
testData
.
_2
)
|
有了这个 OLS 模型,我们现在可以根据某人的身高和性别预测其体重了:
|
1
2
3
|
println
(
"Prediction for Male of 1.7M: "
+
olsModel
.
predict
(
Array
(
0.0
,
170.0
)
)
)
println
(
"Prediction for Female of 1.7M:"
+
olsModel
.
predict
(
Array
(
1.0
,
170.0
)
)
)
println
(
"Model Error:"
+
olsModel
.
error
(
)
)
|
结果如下:
|
1
2
3
|
Prediction
for
Male
of
1.7M
:
79.14538559840447
Prediction
for
Female
of
1.7M
:
70.35580395758966
Model
Error
:
4.5423150758157185
|
回顾前文的分类算法,它有一个能够反映模型性能的先验值。回归分析是一种更强大的统计方法,它可以给出一个实际误差。这个值反映了偏离拟合回归线的平均程度,因此可以说,在这个模型中,一个身高1.70米的男性的预测体重是 79.15kg ± 4.54kg,4.54 为误差值。注意,如果不考虑数据的男女差异,这一误差会增加到 5.5428。换言之,考虑了数据的男女差异后,模型在预测时,精确度提高了 ±1kg
最后一点,Smile 库也提供了一些关于模型的统计信息。R平方值是模型的均方根误差(RMSE)与平均函数的 RMSE 之比。这个值介于 0 与 1 之间。假如你的模型能够准确的预测每一个数据点,R平方值就是 1,如果模型的预测效果比平均函数差,则该值为 0。在机器学习领域中,通常将该值乘以 100,代表模型的精确度。它是一个归一化值,所以可以用来比较不同模型的性能。
本部分总结了线性回归分析的过程,如果你还想了解如何将回归分析应用于非线性数据,请随时学习下一个实例“应用文本回归尝试畅销书排行预测”。
应用文本回归尝试预测最畅销书排行
在实例“根据身高预测体重”中,我们介绍了线性回归的概念。然而,有时候需要将回归分析应用到像文本这类的非数字数据中去。
在本例中,我们将通过尝试预测最畅销的 100 本 O’Reilly 公司出版的图书,说明如何应用文本回归。此外,我们还介绍在本例的特殊情况下应用文本回归无法解决问题。原因仅仅是这些数据中不含有可以被我们的测试数据利用的信号。即使如此,本例也并非一无是处,因为在实践中,数据可能会含有实际信号,该信号可以被这里要介绍的文本回归检测到。
本例使用到的数文件可以在这里下载。除了 Smile 库,本例也会使用 Scala-csv 库,因为 csv 中包含带逗号的字符串。我们从获取需要的数据开始:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
object
TextRegression
{
def
main
(
args
:
Array
[
String
]
)
:
Unit
=
{
//Get the example data
//获取案例数据
val
basePath
=
"/users/.../TextRegression_Example_4.csv"
val
testData
=
getDataFromCSV
(
new
File
(
basePath
)
)
}
def
getDataFromCSV
(
file
:
File
)
:
List
[
(
String
,
Int
,
String
)
]
=
{
val
reader
=
CSVReader
.
open
(
file
)
val
data
=
reader
.
all
(
)
val
documents
=
data
.
drop
(
1
)
.
map
(
x
=
>
(
x
(
1
)
,
x
(
3
)
toInt
,
x
(
4
)
)
)
return
documents
}
}
|
现在我们得到了 O’Reilly 出版社最畅销100部图书的书名、排序和详细说明。然而,当涉及某种回归分析时,我们需要数字数据。这就是问什么我们要建立一个文档词汇矩阵 (DTM)。注意这个 DTM 与我们在垃圾邮件分类实例中建立的词汇文档矩阵 (TDM) 是类似的。区别在于,DTM 存储的是文档记录,包含文档中的词汇,相反,TDM 存储的是词汇记录,包含这些词汇所在的一系列文档。
我们自己用如下代码生成 DTM:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
import
java
.
io
.
File
import
scala
.
collection
.
mutable
class
DTM
{
var
records
:
List
[
DTMRecord
]
=
List
[
DTMRecord
]
(
)
var
wordList
:
List
[
String
]
=
List
[
String
]
(
)
def
addDocumentToRecords
(
documentName
:
String
,
rank
:
Int
,
documentContent
:
String
)
=
{
//Find a record for the document
//找出一条文档记录
val
record
=
records
.
find
(
x
=
>
x
.
document
==
documentName
)
if
(
record
.
nonEmpty
)
{
throw
new
Exception
(
"Document already exists in the records"
)
}
var
wordRecords
=
mutable
.
HashMap
[
String
,
Int
]
(
)
val
individualWords
=
documentContent
.
toLowerCase
.
split
(
" "
)
individualWords
.
foreach
{
x
=
>
val
wordRecord
=
wordRecords
.
find
(
y
=
>
y
.
_1
==
x
)
if
(
wordRecord
.
nonEmpty
)
{
wordRecords
+=
x
->
(
wordRecord
.
get
.
_2
+
1
)
}
else
{
wordRecords
+=
x
->
1
wordList
=
x
::
wordList
}
}
records
=
new
DTMRecord
(
documentName
,
rank
,
wordRecords
)
::
records
}
def
getStopWords
(
)
:
List
[
String
]
=
{
val
source
=
scala
.
io
.
Source
.
fromFile
(
new
File
(
"/Users/.../stopwords.txt"
)
)
(
"latin1"
)
val
lines
=
source
.
mkString
.
split
(
"n"
)
source
.
close
(
)
return
lines
.
toList
}
def
getNumericRepresentationForRecords
(
)
:
(
Array
[
Array
[
Double
]
]
,
Array
[
Double
]
)
=
{
//First filter out all stop words:
//首先过滤出所有停用词
val
StopWords
=
getStopWords
(
)
wordList
=
wordList
.
filter
(
x
=
>
!
StopWords
.
contains
(
x
)
)
var
dtmNumeric
=
Array
[
Array
[
Double
]
]
(
)
var
ranks
=
Array
[
Double
]
(
)
records
.
foreach
{
x
=
>
//Add the rank to the array of ranks
//将评级添加到排序数组中
ranks
=
ranks
:
+
x
.
rank
.
toDouble
//And create an array representing all words and their occurrences
//for this document:
//为该文档创建一个数组,表示所有单词及其出现率
var
dtmNumericRecord
:
Array
[
Double
]
=
Array
(
)
wordList
.
foreach
{
y
=
>
val
termRecord
=
x
.
occurrences
.
find
(
z
=
>
z
.
_1
==
y
)
if
(
termRecord
.
nonEmpty
)
{
dtmNumericRecord
=
dtmNumericRecord
:
+
termRecord
.
get
.
_2
.
toDouble
}
else
{
dtmNumericRecord
=
dtmNumericRecord
:
+
0.0
}
}
dtmNumeric
=
dtmNumeric
:
+
dtmNumericRecord
}
return
(
dtmNumeric
,
ranks
)
}
}
class
DTMRecord
(
val
document
:
String
,
val
rank
:
Int
,
var
occurrences
:
mutable
.
HashMap
[
String
,
Int
]
)
|
观察这段代码,注意到这里面有一个方法 def getNumericRepresentationForRecords(): (Array[Array[Double]], Array[Double])。这一方法返回一个元组,该元组以一个矩阵作为第一个参数,该矩阵中每一行代表一个文档,每一列代表来自 DTM 文档的完备词汇集中的词汇。注意第一个列表中的浮点数表示词汇出现的次数。
第二个参数是一个数组,包含第一个列表中所有记录的排序值。
现在我们可以按如下方式扩展主程序,这样就可以得到所有文档的数值表示:
|
1
2
|
val
documentTermMatrix
=
new
DTM
(
)
testData
.
foreach
(
x
=
>
documentTermMatrix
.
addDocumentToRecords
(
x
.
_1
,
x
.
_2
,
x
.
_3
)
)
|
有了这个从文本到数值的转换,现在我们可以利用回归分析工具箱了。我们在“基于身高预测体重”的实例中应用了普通最小二乘法 (OLS),不过这次我们要应用“最小绝对收缩与选择算子”(Lasso) 回归。这是因为我们可以给这种回归方法提供某个 λ 值,它代表一个惩罚值。该惩罚值可以帮助 LASSO 算法选择相关的特征(单词)而丢弃其他一些特征(单词)。
LASSO 执行的这一特征选择功能非常有用,因为在本例中,文档说明包含了大量的单词。LASSO 会设法找出那些单词的一个合适的子集作为特征,而要是应用 OLS,则所有单词都会被使用,那么运行时间将会变得极其漫长。此外,OLS 算法实现会检测非满秩。这是维数灾难的一种情形。
无论如何,我们需要找出一个最佳的 λ 值,因此,我们应该用交叉验证法尝试几个 λ 值,操作过程如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
for
(
i
<
-
0
until
cv
.
k
)
{
//Split off the training datapoints and classifiers from the dataset
//从数据集中将用于训练的数据点与分类器分离出来
val
dpForTraining
=
numericDTM
.
_1
.
zipWithIndex
.
filter
(
x
=
>
cv
.
test
(
i
)
.
toList
.
contains
(
x
.
_2
)
)
.
map
(
y
=
>
y
.
_1
)
val
classifiersForTraining
=
numericDTM
.
_2
.
zipWithIndex
.
filter
(
x
=
>
cv
.
test
(
i
)
.
toList
.
contains
(
x
.
_2
)
)
.
map
(
y
=
>
y
.
_1
)
//And the corresponding subset of data points and their classifiers for testing
//以及对应的用于测试的数据点子集及其分类器
val
dpForTesting
=
numericDTM
.
_1
.
zipWithIndex
.
filter
(
x
=
>
!
cv
.
test
(
i
)
.
contains
(
x
.
_2
)
)
.
map
(
y
=
>
y
.
_1
)
val
classifiersForTesting
=
numericDTM
.
_2
.
zipWithIndex
.
filter
(
x
=
>
!
cv
.
test
(
i
)
.
contains
(
x
.
_2
)
)
.
map
(
y
=
>
y
.
_1
)
//These are the lambda values we will verify against
//这些是我们将要验证的λ值
val
lambdas
:
Array
[
Double
]
=
Array
(
0.1
,
0.25
,
0.5
,
1.0
,
2.0
,
5.0
)
lambdas
.
foreach
{
x
=
>
//Define a new model based on the training data and one of the lambda's
//定义一个基于训练数据和其中一个λ值的新模型
val
model
=
new
LASSO
(
dpForTraining
,
classifiersForTraining
,
x
)
//Compute the RMSE for this model with this lambda
//计算该模型的RMSE值
val
results
=
dpForTesting
.
map
(
y
=
>
model
.
predict
(
y
)
)
zip
classifiersForTesting
val
RMSE
=
Math
.
sqrt
(
results
.
map
(
x
=
>
Math
.
pow
(
x
.
_1
-
x
.
_2
,
2
)
)
.
sum
/
results
.
length
)
println
(
"Lambda: "
+
x
+
" RMSE: "
+
RMSE
)
}
}
|
多次运行这段代码会给出一个在 36 和 51 之间变化的 RMSE 值。这表示我们排序的预测值会偏离至少 36 位。鉴于我们要尝试预测最高的 100 位,结果表明这个模型的效果非常差。在本例中,λ 值变化对模型的影响并不明显。然而,在实践中应用这种算法时,要小心地选取 λ 值: λ 值选得越大,算法选取的特征数就越少。 所以,交叉验证法对分析不同 λ 值对算法的影响很重要。
引述 John Tukey 的一句话来总结这个实例:
“数据中未必隐含答案。某些数据和对答案的迫切渴求的结合,无法保证人们从一堆给定数据中提取出一个合理的答案。”
应用无监督学习合并特征(PCA)
主成分分析 (PCA) 的基本思路是减少一个问题的维数。这是一个很好的方法,它可以避免维灾难,也可以帮助合并数据,避开无关数据的干扰,使其中的趋势更明显。
在本例中,我们打算应用 PCA 把 2002-2012 年这段时间内 24 只股票的股价合并为一只股票的股价。这个随时间变化的值就代表一个基于这 24 只股票数据的股票市场指数。把这24种股票价格合并为一种,明显地减少了处理过程中的数据量,并减少了数据维数,对于之后应用其他机器学习算法作预测,如回归分析来说,有很大的好处。为了看出特征数从 24 减少为 1 之后的效果,我们会将结果与同一时期的道琼斯指数 (DJI) 作比较。
随着工程的开始,下一步要做的是加载数据。为此,我们提供了两个文件:Data file 1 和 Data file 2.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
object
PCA
extends
SimpleSwingApplication
{
def
top
=
new
MainFrame
{
title
=
"PCA Example"
//Get the example data
//获取案例数据
val
basePath
=
"/users/.../Example Data/"
val
exampleDataPath
=
basePath
+
"PCA_Example_1.csv"
val
trainData
=
getStockDataFromCSV
(
new
File
(
exampleDataPath
)
)
}
def
getStockDataFromCSV
(
file
:
File
)
:
(
Array
[
Date
]
,
Array
[
Array
[
Double
]
]
)
=
{
val
source
=
scala
.
io
.
Source
.
fromFile
(
file
)
//Get all the records (minus the header)
//获取所有记录(减去标头)
val
data
=
source
.
getLines
(
)
.
drop
(
1
)
.
map
(
x
=
>
getStockDataFromString
(
x
)
)
.
toArray
source
.
close
(
)
//group all records by date, and sort the groups on date ascending
//按日期将所有记录分组,并按日期将组升序排列
val
groupedByDate
=
data
.
groupBy
(
x
=
>
x
.
_1
)
.
toArray
.
sortBy
(
x
=
>
x
.
_1
)
//extract the values from the 3-tuple and turn them into
// an array of tuples: Array[(Date, Array[Double)]
//抽取这些3元组的值并将它们转换为一个元组数组:Array[(Date,Array[Double])]
val
dateArrayTuples
=
groupedByDate
.
map
(
x
=
>
(
x
.
_1
,
x
.
_2
.
sortBy
(
x
=
>
x
.
_2
)
.
map
(
y
=
>
y
.
_3
)
)
)
//turn the tuples into two separate arrays for easier use later on
//将这些元组分隔为两个数组以方便之后使用
val
dateArray
=
dateArrayTuples
.
map
(
x
=
>
x
.
_1
)
.
toArray
val
doubleArray
=
dateArrayTuples
.
map
(
x
=
>
x
.
_2
)
.
toArray
(
dateArray
,
doubleArray
)
}
def
getStockDataFromString
(
dataString
:
String
)
:
(
Date
,
String
,
Double
)
=
{
//Split the comma separated value string into an array of strings
//把用逗号分隔的数值字符串分解为一个字符串数组
val
dataArray
:
Array
[
String
]
=
dataString
.
split
(
','
)
val
format
=
new
SimpleDateFormat
(
"yyyy-MM-dd"
)
//Extract the values from the strings
//从字符串中抽取数值
val
date
=
format
.
parse
(
dataArray
(
0
)
)
val
stock
:
String
=
dataArray
(
1
)
val
close
:
Double
=
dataArray
(
2
)
.
toDouble
//And return the result in a format that can later
//easily be used to feed to Smile
//并以一定格式返回结果,使得该结果之后容易输入到Smile中处理
(
date
,
stock
,
close
)
}
}
|
有了训练数据,并且我们已经知道要将24个特征合并为一个单独的特征,现在我们可以进行主成分分析,并按如下方式为数据点检索数据。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
//Add to `def top`
//添加到‘def top’中
val
pca
=
new
PCA
(
trainData
.
_2
)
pca
.
setProjection
(
1
)
val
points
=
pca
.
project
(
trainData
.
_2
)
val
plotData
=
points
.
zipWithIndex
.
map
(
x
=
>
Array
(
x
.
_2
.
toDouble
,
-
x
.
_1
(
0
)
)
)
val
canvas
:
PlotCanvas
=
LinePlot
.
plot
(
"Merged Features Index"
,
plotData
,
Line
.
Style
.
DASH
,
Color
.
RED
)
;
peer
.
setContentPane
(
canvas
)
size
=
new
Dimension
(
400
,
400
)
|
这段代码不仅执行了 PCA,还将结果绘成图像,y 轴表示特征值,x 轴表示每日。

为了能看出 PCA 合并的效果,我们现在通过如下方式调整代码将道琼斯指数加入到图像中:
首先把下列代码添加到 def top 方法中:
|
1
2
3
4
5
6
|
//Verification against DJI
//用道琼斯指数验证
val
verificationDataPath
=
basePath
+
"PCA_Example_2.csv"
val
verificationData
=
getDJIFromFile
(
new
File
(
verificationDataPath
)
)
val
DJIIndex
=
getDJIFromFile
(
new
File
(
verificationDataPath
)
)
canvas
.
line
(
"Dow Jones Index"
,
DJIIndex
.
_2
,
Line
.
Style
.
DOT_DASH
,
Color
.
BLUE
)
|
然后我们需要引入下列两个方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
def
getDJIRecordFromString
(
dataString
:
String
)
:
(
Date
,
Double
)
=
{
//Split the comma separated value string into an array of strings
//把用逗号分隔的数值字符串分解为一个字符串数组
val
dataArray
:
Array
[
String
]
=
dataString
.
split
(
','
)
val
format
=
new
SimpleDateFormat
(
"yyyy-MM-dd"
)
//Extract the values from the strings
//从字符串中抽取数值
val
date
=
format
.
parse
(
dataArray
(
0
)
)
val
close
:
Double
=
dataArray
(
4
)
.
toDouble
//And return the result in a format that can later
//easily be used to feed to Smile
//并以一定格式返回结果,使得该结果之后容易输入到Smile中处理
(
date
,
close
)
}
def
getDJIFromFile
(
file
:
File
)
:
(
Array
[
Date
]
,
Array
[
Double
]
)
=
{
val
source
=
scala
.
io
.
Source
.
fromFile
(
file
)
//Get all the records (minus the header)
//获取所有记录(减去标头)
val
data
=
source
.
getLines
(
)
.
drop
(
1
)
.
map
(
x
=
>
getDJIRecordFromString
(
x
)
)
.
toArray
source
.
close
(
)
//turn the tuples into two separate arrays for easier use later on
//将这些元组分隔为两个数组以方便之后使用
val
sortedData
=
data
.
sortBy
(
x
=
>
x
.
_1
)
val
dates
=
sortedData
.
map
(
x
=
>
x
.
_1
)
val
doubles
=
sortedData
.
map
(
x
=
>
x
.
_2
)
(
dates
,
doubles
)
}
|
这段代码加载了 DJI 数据,并把它绘成图线添加到我们自己的股票指数图中。然而,当我们执行这段代码时,效果图有点无用。

如你所见,DJI 的取值范围与我们的计算特征的取值范围偏离很远。因此,现在我们要将数据标准化。办法就是根据数据的取值范围将数据进行缩放,这样,两个数据集就会落在同样的比例中。
用下列代码替换 getDJIFromFile 方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
def
getDJIFromFile
(
file
:
File
)
:
(
Array
[
Date
]
,
Array
[
Double
]
)
=
{
val
source
=
scala
.
io
.
Source
.
fromFile
(
file
)
//Get all the records (minus the header)
//获取所有记录(减去标头)
val
data
=
source
.
getLines
(
)
.
drop
(
1
)
.
map
(
x
=
>
getDJIRecordFromString
(
x
)
)
.
toArray
source
.
close
(
)
//turn the tuples into two separate arrays for easier use later on
//将这些元组分隔为两个数组以方便之后使用
val
sortedData
=
data
.
sortBy
(
x
=
>
x
.
_1
)
val
dates
=
sortedData
.
map
(
x
=
>
x
.
_1
)
val
maxDouble
=
sortedData
.
maxBy
(
x
=
>
x
.
_2
)
.
_2
val
minDouble
=
sortedData
.
minBy
(
x
=
>
x
.
_2
)
.
_2
val
rangeValue
=
maxDouble
-
minDouble
val
doubles
=
sortedData
.
map
(
x
=
>
x
.
_2
/
rangeValue
)
(
dates
,
doubles
)
}
|
用下列代码替换 def top 方法中 plotData 的定义:
|
1
2
3
4
5
6
|
val
maxDataValue
=
points
.
maxBy
(
x
=
>
x
(
0
)
)
val
minDataValue
=
points
.
minBy
(
x
=
>
x
(
0
)
)
val
rangeValue
=
maxDataValue
(
0
)
-
minDataValue
(
0
)
val
plotData
=
points
.
zipWithIndex
.
map
(
x
=
>
Array
(
x
.
_2
.
toDouble
,
-
x
.
_1
(
0
)
/
rangeValue
)
)
|

现在我们看到,虽然 DJI 的取值范围落在 0.8 与 1.8 之间,而我们的新特征的取值范围落在 -0.5 与 0.5 之间,但两条曲线的趋势符合得很好。学完这个实例,加上段落中对 PCA 的说明,现在你应该学会了 PCA 并能把它应用到你自己的数据中。
应用支持向量机(SVM)
在我们实际开始应用支持向量机 (SVM) 之前,我会稍微介绍一下 SVM。基本的 SVM 是一个二元分类器,它通过挑选出一个代表数据点之间最大距离的超平面,将数据集分为两部分。一个 SVM 就带有一个所谓的“校正率”值。如果不存在理想分割,则该校正率提供了一个误差范围,允许人们在该范围内找出一个仍尽可能合理分割的超平面。因此,即使仍存在一些令人不快的点,在校正率规定的误差范围内,超平面也是合适的。这意味着,我们无法为每种情形提出一个“标准的”校正率。不过,如果数据中没有重叠部分,则较低的校正率要优于较高的校正率。
我刚刚说明了作为一个二元分类器的基本 SVM,但是这些原理也适用于具有更多类别的情形。然而,现在我们要继续完成具有 2 种类别的实例,因为仅说明这种情况已经足够了。
在本例中,我们将完成几个小案例,其中,支持向量机 (SVM) 的表现都胜过其他分离算法如 KNN。这种方法与前几例中的不同,但它能帮你更容易学会怎么使用以及何时使用 SVM。
对于每个小案例,我们会提供代码、图像、不同参数时的 SVM 运行测试以及对测试结果的分析。这应该使你对输入 SVM 算法的参数有所了解。
在第一个小案例中,我们将应用高斯核函数,不过在 Smile 库中还有其他核函数。其他核函数可以在这里找到。紧接着高斯核函数,我们将讲述多项式核函数,因为这个核函数与前者有很大的不同。
我们会在每个小案例中用到下列的基本代码,其中只有构造函数 filePaths 和 svm 随每个小案例而改变。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
object
SupportVectorMachine
extends
SimpleSwingApplication
{
def
top
=
new
MainFrame
{
title
=
"SVM Examples"
//File path (this changes per example)
//文件路径(随案例而改变)
val
trainingPath
=
"/users/.../Example Data/SVM_Example_1.csv"
val
testingPath
=
"/users/.../Example Data/SVM_Example_1.csv"
//Loading of the test data and plot generation stays the same
//加载测试数据,绘图生成代码保持相同
val
trainingData
=
getDataFromCSV
(
new
File
(
path
)
)
val
testingData
=
getDataFromCSV
(
new
File
(
path
)
)
val
plot
=
ScatterPlot
.
plot
(
trainingData
.
_1
,
trainingData
.
_2
,
'@'
,
Array
(
Color
.
blue
,
Color
.
green
)
)
peer
.
setContentPane
(
plot
)
//Here we do our SVM fine tuning with possibly different kernels
//此处,我们用可能的不同核函数对SVM进行微调
val
svm
=
new
SVM
[
Array
[
Double
]
]
(
new
GaussianKernel
(
0.01
)
,
1.0
,
2
)
svm
.
learn
(
trainingData
.
_1
,
trainingData
.
_2
)
svm
.
finish
(
)
//Calculate how well the SVM predicts on the training set
//计算SVM对测试集的预测效果
val
predictions
=
testingData
.
_1
.
map
(
x
=
>
svm
.
predict
(
x
)
)
.
zip
(
testingData
.
_2
)
val
falsePredictions
=
predictions
.
map
(
x
=
>
if
(
x
.
_1
==
x
.
_2
)
0
else
1
)
println
(
falsePredictions
.
sum
.
toDouble
/
predictions
.
length
*
100
+
" % false predicted"
)
size
=
new
Dimension
(
400
,
400
)
}
def
getDataFromCSV
(
file
:
File
)
:
(
Array
[
Array
[
Double
]
]
,
Array
[
Int
]
)
=
{
val
source
=
scala
.
io
.
Source
.
fromFile
(
file
)
val
data
=
source
.
getLines
(
)
.
drop
(
1
)
.
map
(
x
=
>
getDataFromString
(
x
)
)
.
toArray
source
.
close
(
)
val
dataPoints
=
data
.
map
(
x
=
>
x
.
_1
)
val
classifierArray
=
data
.
map
(
x
=
>
x
.
_2
)
return
(
dataPoints
,
classifierArray
)
}
def
getDataFromString
(
dataString
:
String
)
:
(
Array
[
Double
]
,
Int
)
=
{
//Split the comma separated value string into an array of strings
//把用逗号分隔的数值字符串分解为一个字符串数组
val
dataArray
:
Array
[
String
]
=
dataString
.
split
(
','
)
//Extract the values from the strings
//从字符串中抽取数值
val
coordinates
=
Array
(
dataArray
(
0
)
.
toDouble
,
dataArray
(
1
)
.
toDouble
)
val
classifier
:
Int
=
dataArray
(
2
)
.
toInt
//And return the result in a format that can later
//easily be used to feed to Smile
//并以一定格式返回结果,使得该结果之后容易输入到Smile中处理
return
(
coordinates
,
classifier
)
}
|
案例1(高斯核函数)
在本案例中,我们介绍了最常用的 SVM 核函数,即高斯核函数。我们的想法是帮助读者寻找该核函数的最佳输入参数。本例中用到的数据可以在这里下载。
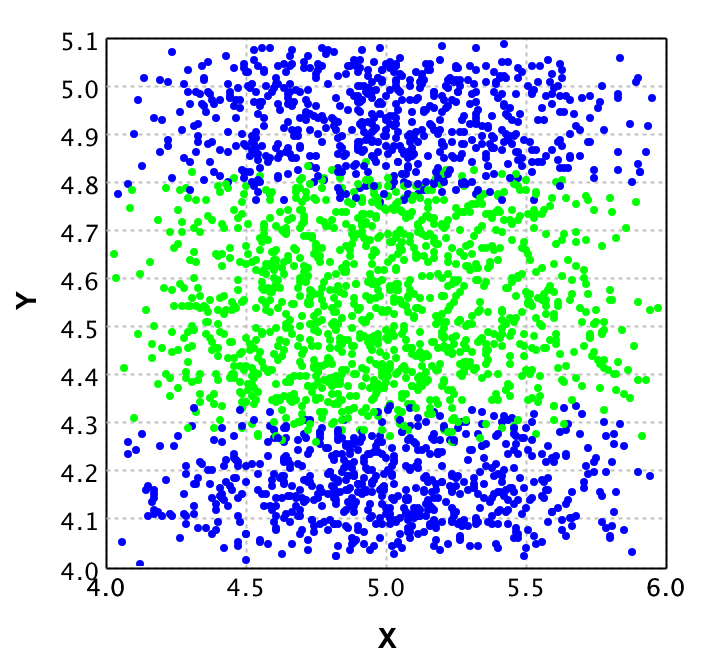
从该图中可以清楚看出,线性回归线在这里起不了作用。我们要使用一个 SVM 来作预测。在给出的第一段代码中,高斯核函数的 sigma 值为 0.01,边距惩罚系数为 1.0,类别总数为 2,并将其传递给了 SVM。那么,这些都代表什么意思呢?
我们从高斯核函数说起。这个核函数反映了 SVM 如何计算系统中成对数据的相似度。对于高斯核函数,用到了欧氏距离中的方差。我们特意挑选高斯核函数的原因是,数据中并不含有明显的结构如线性函数、多项式函数或者双曲线函数。相反地,数据聚集成了3组。
我们传递到高斯核中构造函数的参数是 sigma。这个 sigma 值反映了核函数的平滑程度。我们会演示改变这一取值如何影响预测效果。我们将边距惩罚系数取 1。这一参数定义了系统中向量的边距,因此,这一值越小,约束向量就越多。我们会执行一组运行测试,通过结果向读者说明这个参数在实践中的作用。注意其中 s: 代表 sigma,c: 代表校正惩罚系数。百分数表示预测效果的误差率, 它只不过是训练之后,对相同数据集的错误预测的百分数。

不幸的是,并不存在为每个数据集寻找正确 sigma 的黄金法则。不过,可能最好的方法就是计算数据的 sigma 值,即 √(variance),然后在这个值附近取值看看哪一个 sigma 值效果最好。因为本例数据的方差在 0.2 与 0.5 之间,我们把这区间作为中心并在中心的两边都选取一些值,以比较我们的案例中使用高斯核的 SVM 的表现。
看看表格中的结果和错误预测的百分比,它表明产生最佳效果的参数组合是一个非常低的 sigma (0.001) 和一个 1.0 及以上的校正率。不过,如果把这个模型应用到实际中的新数据上,可能会产生过拟合。因此,在用模型本身的训练数据测试模型时,你应该保持谨慎。一个更好的方法是使用交叉验证,或用新数据验证。
案例2(多项式核函数)
高斯核并不总是最佳选择,尽管在应用 SVM 时,它是最常用的核函数。因此,在本例中,我们将演示一个多项式核函数胜过高斯核函数的案例。注意,虽然本案例中的示例数据是构建好的,但在本领域内相似的数据(带有一点噪声)是可以找到的。本案例中的训练数据可以在这里下载,测试数据在这里下载。
对于本例数据,我们用一个三次多项式创建了两个类别,并生成了一个测试数据文件和一个训练数据文件。训练数据包含x轴上的前500个点,而测试数据则包含x轴上500到1000这些点。为了分析多项式核函数的工作原理,我们将数据汇成图。左图是训练数据的,右图是测试数据的。


考虑到本实例开头给出的基本代码,我们作如下的替换:
|
1
2
|
val
trainingPath
=
"/users/.../Example Data/SVM_Example_2.csv"
val
testingPath
=
"/users/.../Example Data/SVM_Example_2_Test_data.csv"
|
然后,如果我们使用高斯核并且运行代码,就可以得到如下结果:

可以看到,即使是最佳情况,仍然有 27.4% 的测试数据被错误分类。这很有趣,因为当我们观察图像时,可以看到两个类别之间有一个很明显的区分。我们可以对 sigma 和校正率进行微调,但是当预测点很远时(例如 x 是 100000),sigma 和校正率就会一直太高而使模型表现不佳(时间方面与预测效果方面)。
因此,我们将高斯核替换为多项式核,代码如下:
|
1
|
val
svm
=
new
SVM
[
Array
[
Double
]
]
(
new
PolynomialKernel
(
2
)
,
1.0
,
2
)
|
注意我们给多项式核的构造函数传递 2 的方式。这个 2 代表它要拟合的函数的次数。如果我们不单考虑次数为 2 的情况,我们还考虑次数为2、3、4、5的情况,并且让校正率再一次在 0.001 到 100 之间变化,则得到如下结果:

从中我们可以看到,次数为 3 和 5 的情况得到了100%的准确率,这两种情况中测试数据与训练数据之间没有一个点是重叠的。与高斯核的最佳情况 27.4% 的错误率相比,这种表现令人惊喜。确实要注意本例这些数据是构建好的,因此没有什么噪声数据。所以才能出现所有的“校正率”都为 0% 错误率。如果添加了噪声,则需要对校正率进行微调。
以上就是对支持向量机这一部分的总结。
结论
在了解了机器学习的整体思想之后,你应该可以辨别出哪些情况分别属于分类问题、回归问题或是维数约化问题。此外,你应该理解机器学习的基本概念,什么是模型,并且知道机器学习中的一些常见陷阱。
在学完本文中的实例之后,你应该学会应用 K-NN、朴素贝叶斯算法以及线性回归分析了。此外,你也能够应用文本回归、使用 PCA 合并特征以及应用支持向量机。还有非常重要的一点,就是能够建立你自己的推荐系统。















 1985
1985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









