







CNN
CNN简介
卷积神经网络(Convolutional Neural Networks,简称CNN)。
卷积神经网络(CNN)由输入层、卷积层、激活函数、池化层、全连接层组成,即INPUT-CONV-RELU-POOL-FC。
初识卷积
首先,我们去学习卷积层的模型原理,在学习卷积层的模型原理前,我们需要了解什么是卷积,以及CNN中的卷积是什么样子的。
大家学习数学时都有学过卷积的知识,微积分中卷积的表达式为:
离散形式是:
这个式子如果用矩阵表示可以为:
其中星号表示卷积。
如果是二维的卷积,则表示式为:
在CNN中,虽然我们也是说卷积,但是我们的卷积公式和严格意义数学中的定义稍有不同,比如对于二维的卷积,定义为:
这个式子虽然从数学上讲不是严格意义上的卷积,但是大牛们都这么叫了,那么我们也跟着这么叫了。后面讲的 CNN C N N 的卷积都是指的上面的最后一个式子。
其中,我们叫 W W 为我们的卷积核,而X则为我们的输入。如果X是一个二维输入的矩阵,而也是一个二维的矩阵。但是如果 X X 是多维张量,那么也是一个多维的张量。
CNN中的卷积层
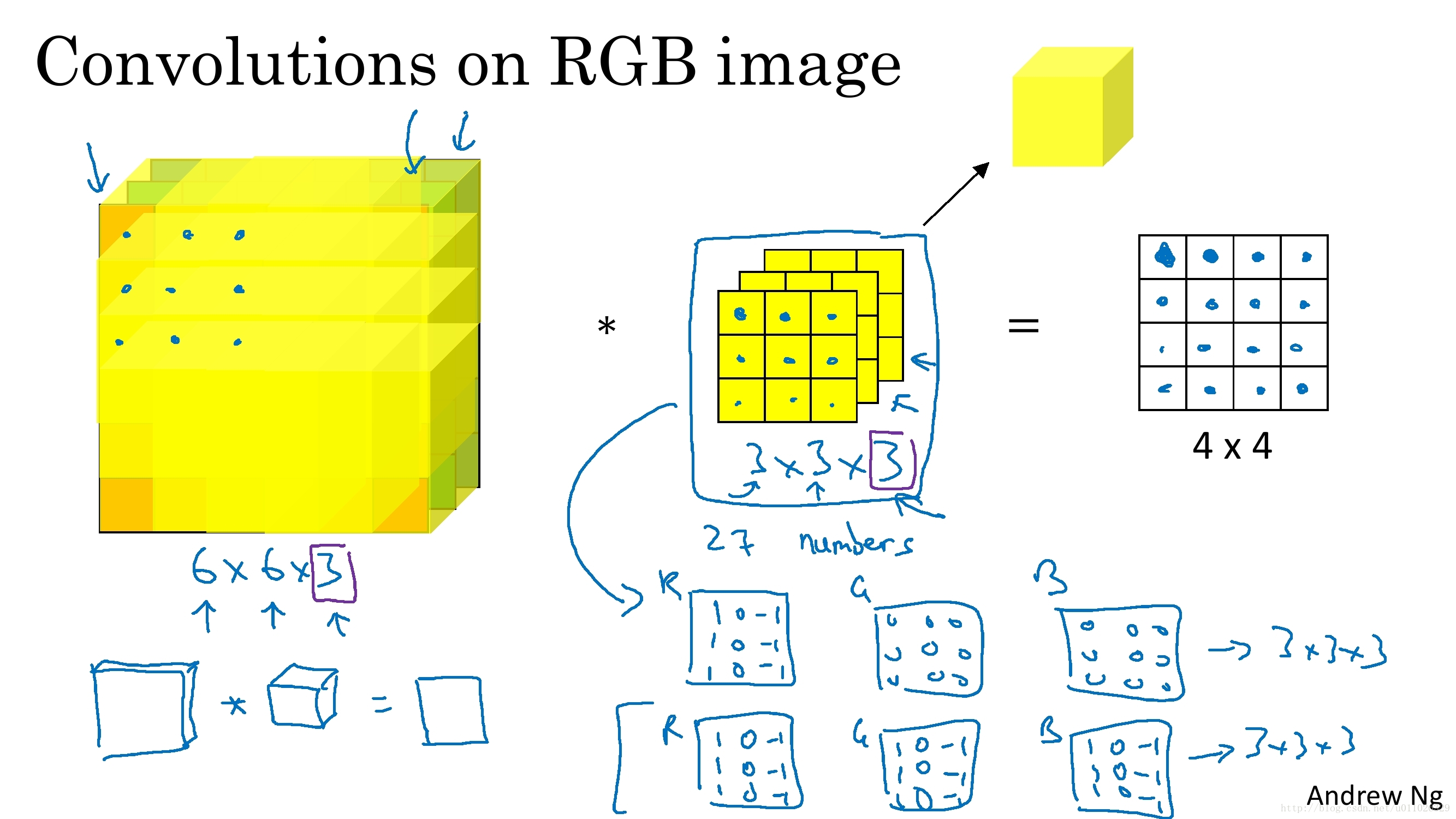
有了卷积的基本知识,我们现在来看看CNN中的卷积,假如是对图像卷积,如上面的卷积公式(5),其实就是对图像的不同局部的矩阵和卷积核矩阵各个位置的元素相乘,然后相加得到。
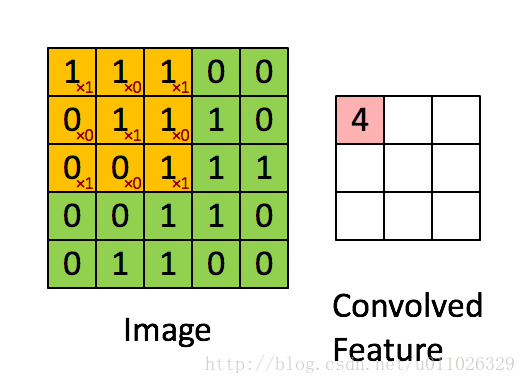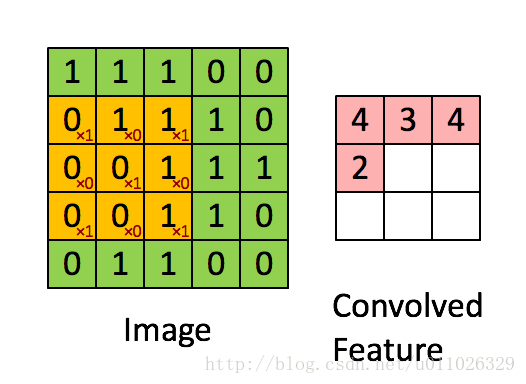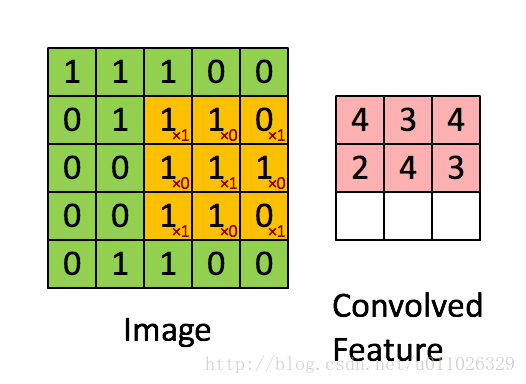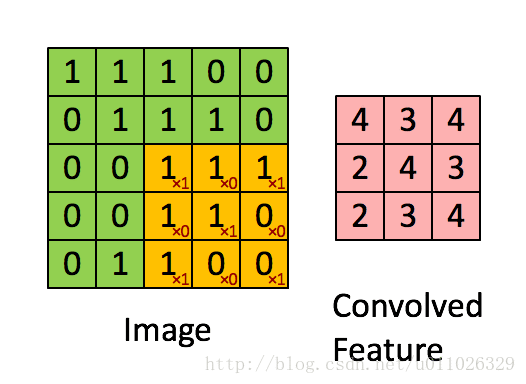
如上面卷积公式所示,卷积核
Wmn
W
m
n
中
m=3,n=3
m
=
3
,
n
=
3
,图像
X
X
,
即上面动态图显示的结果。
Padding
卷积核在提取特征映射时的动作称为 padding,其有两种方式,即 SAME 和 VALID。
由于移动步长(Stride)不一定能整除整张图的像素宽度,我们把不越过边缘取样称为 Valid Padding,输出的面积小于输入图像的像素宽度;越过边缘取样称为 Same Padding,输出的面积和输入图像的像素宽度一致。
- Valid: no padding
- Same: Pad so that output size is the same as the input size (when stride == 1)
例如: (n∗n) image,(f∗f) filter,padding p ( n ∗ n ) i m a g e , ( f ∗ f ) f i l t e r , p a d d i n g p
if f = 3, then n + 2p - f + 1 = n , so p = 1
if f = 5, then n + 2p - f + 1 = n, so p = 2
if f = 5, then n + 2p -f + 1 = n , so p = 3
stride
stride(步长),即卷积每次滑动的长度。(如果不指定stride,默认为1)
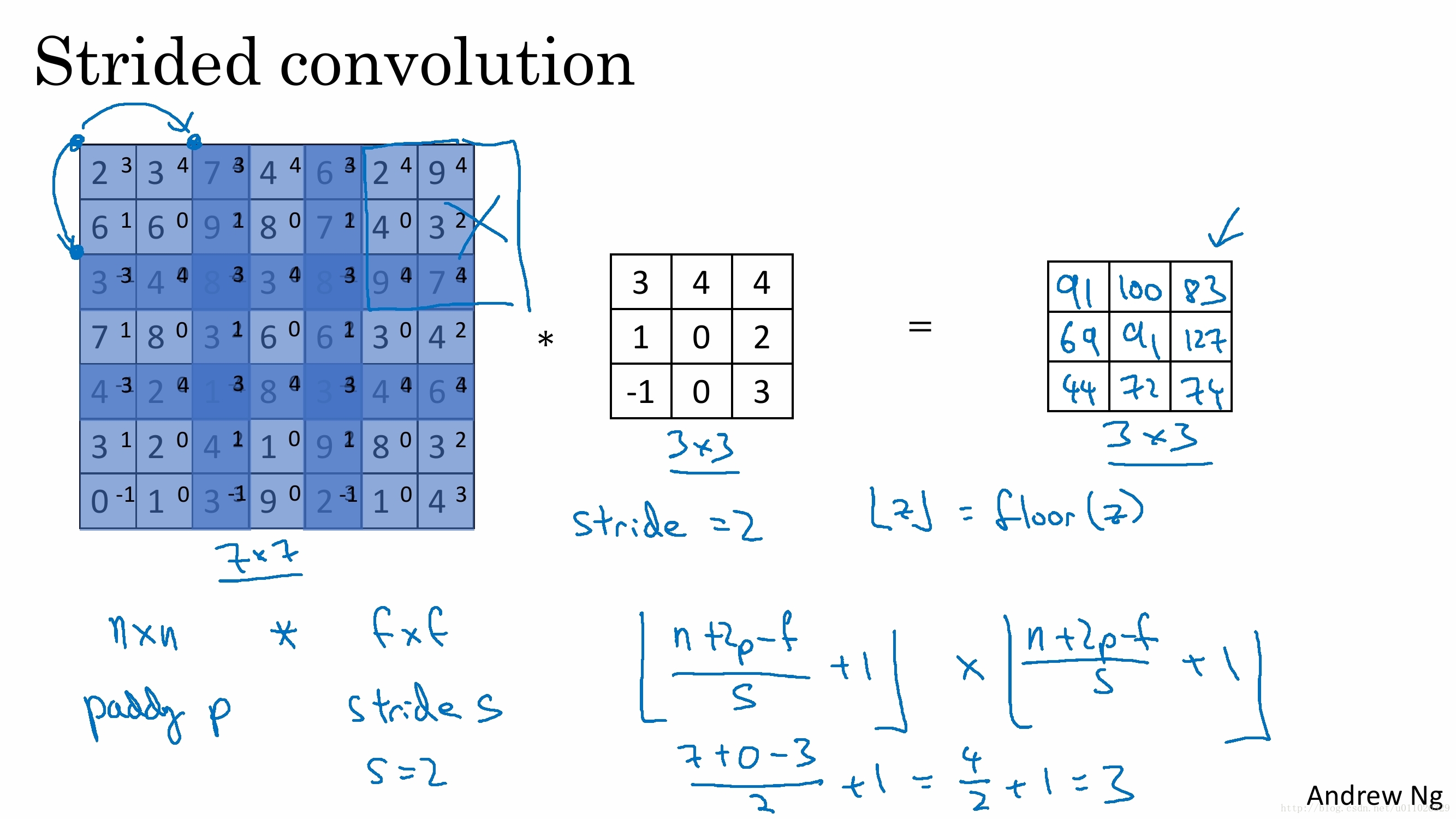

padding(p=1),stride(s=2) 的两个卷积核(Filter W0, W1)的动画效果如下:
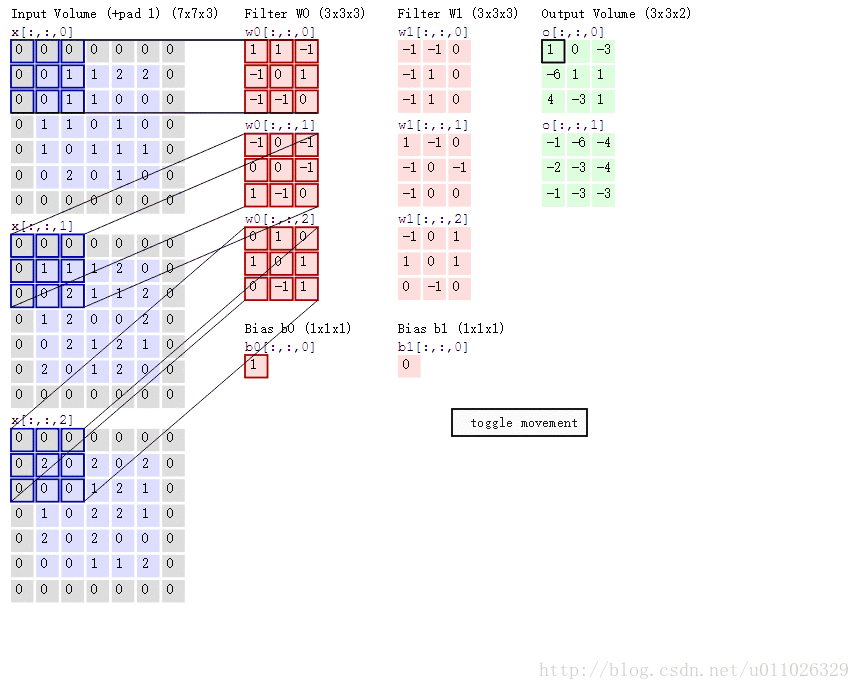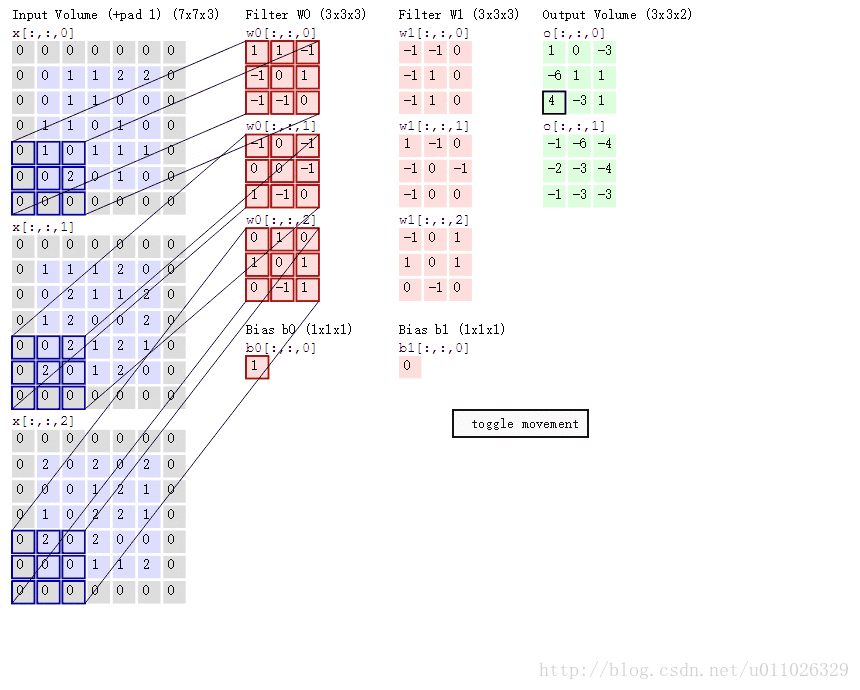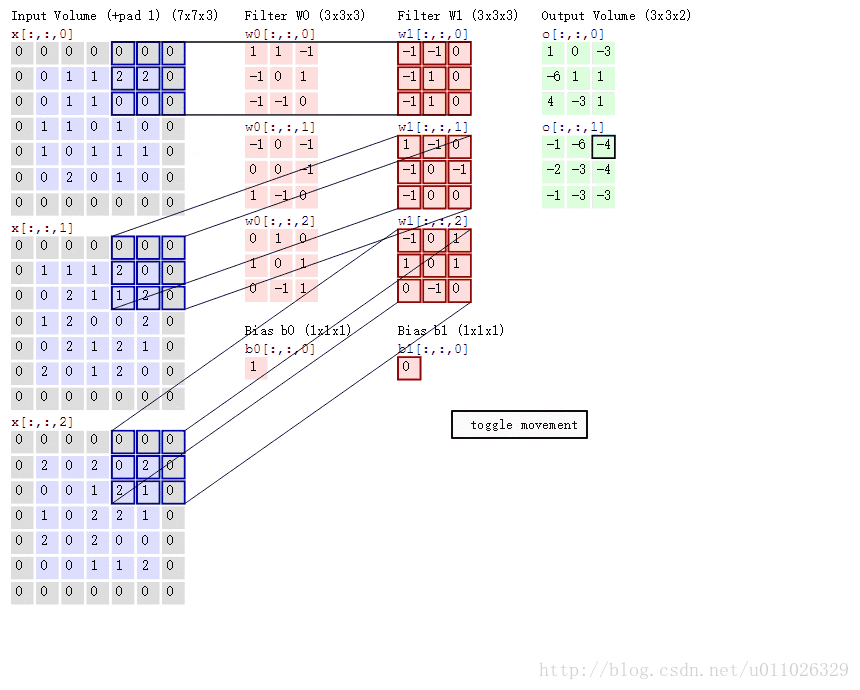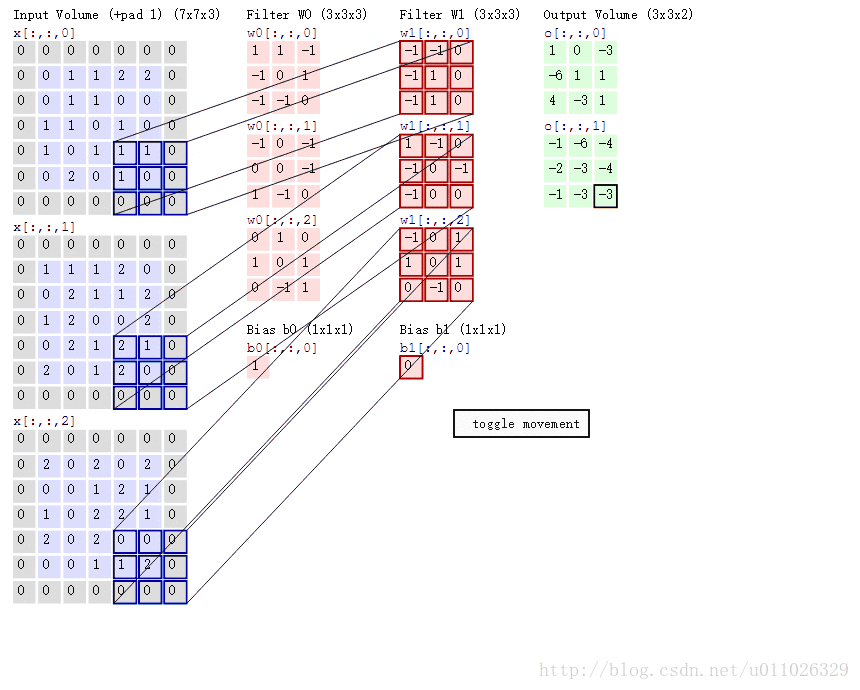
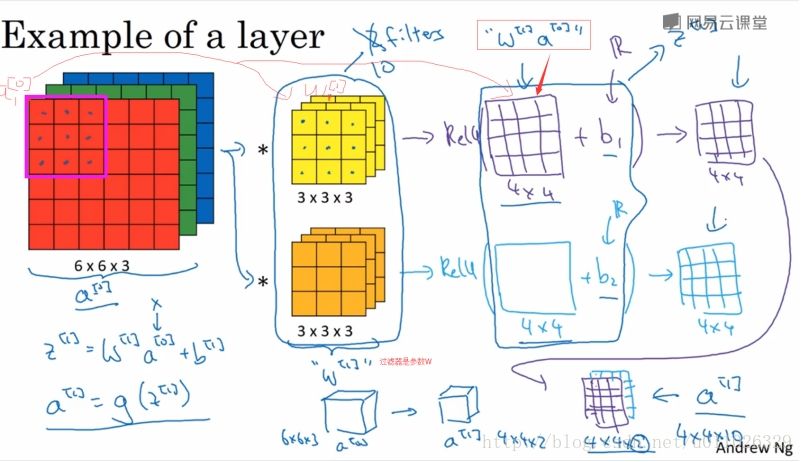
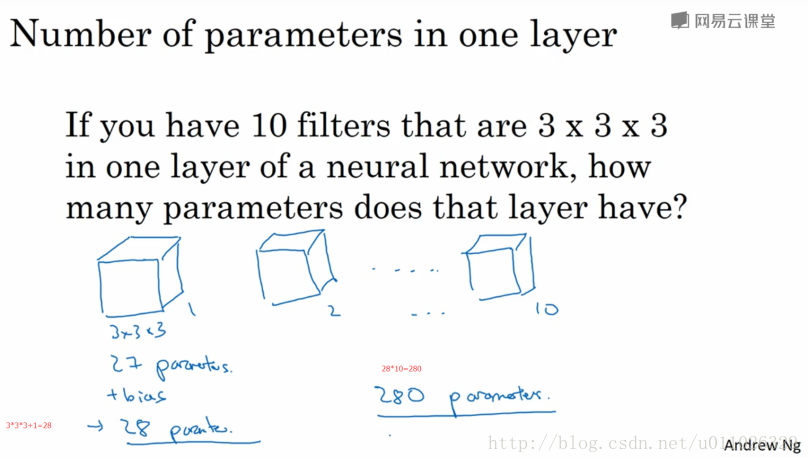
卷积层通过一个个卷积核(kenel)或者过滤器(filter),TensorFlow中使用filter的概念,在原始图像上平移来提取特征,每一个特征就是一个特征映射, 每一个特征映射对应一个特征平面(不管输入图像和卷积核是不是立体的,都会输出特征平面),即一个卷积核的输出是一个特征平面,特征平面中的每一个点是一个神经元,特征平面中的每一个点共享权重(即使用同一个卷积核),有多少卷积核,就输出多少特征平面。一个卷积核映射一个特征平面。
过滤器可以将当前层神经网络上的一个子节点矩阵转化为下一层神经网络上的一个单位节点矩阵。单位节点矩阵指的是一个长和宽都为1,但深度不限的节点矩阵。
在一个卷积层中,过滤器所处理的节点矩阵的长和宽都是由人工指定的,这个节点矩阵的尺寸也被称为过滤器的尺寸。常用的过滤器尺寸有
3*3或5*5。因为过滤器处理的矩阵深度和当前层神经网络节点矩阵的深度是一致的,所有虽然节点矩阵是三维的,但过滤器的尺寸只需要指定两个维度。过滤器中另外一个需要人工指定的设置是处理得到的单位节点矩阵的深度,这个设置称为过滤器的深度。注意过滤器的尺寸指的是一个过滤器输入节点矩阵的大小,而深度指的是输出单位节点矩阵的深度。
局部连接(Sparse Connectivity)和权值共享(Shared Weights)
下图是一个很经典的图示,左边是全连接,右边是局部连接。
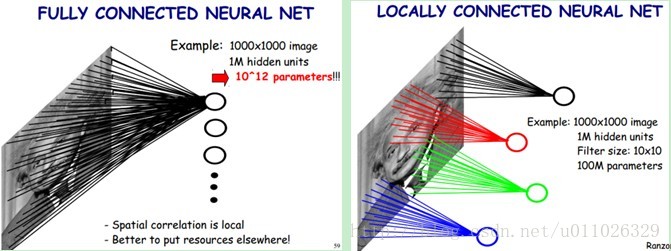
对于一个1000 × 1000的输入图像而言,如果下一个隐藏层的神经元数目为10^6个,采用全连接则有1000 × 1000 × 10^6 = 10^12个权值参数,如此数目巨大的参数几乎难以训练;而采用局部连接,隐藏层的每个神经元仅与图像中10 × 10的局部图像相连接,那么此时的权值参数数量为10 × 10 × 10^6 = 10^8,将直接减少4个数量级。
尽管减少了几个数量级,但参数数量依然较多。能不能再进一步减少呢?能!方法就是权值共享。具体做法是,在局部连接中隐藏层的每一个神经元连接的是一个10 × 10的局部图像,因此有10 × 10个权值参数,将这10 × 10个权值参数共享给剩下的神经元,也就是说隐藏层中10^6个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10 × 10个权值参数(也就是卷积核(也称滤波器)的大小),如下图。
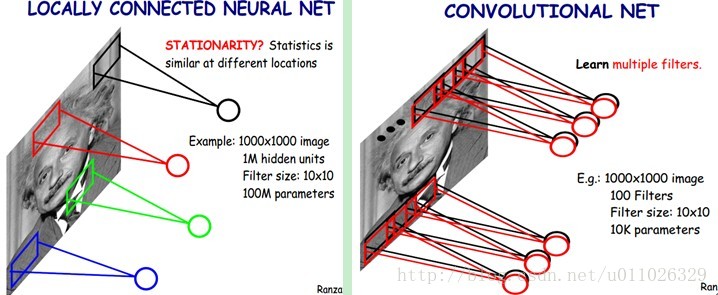
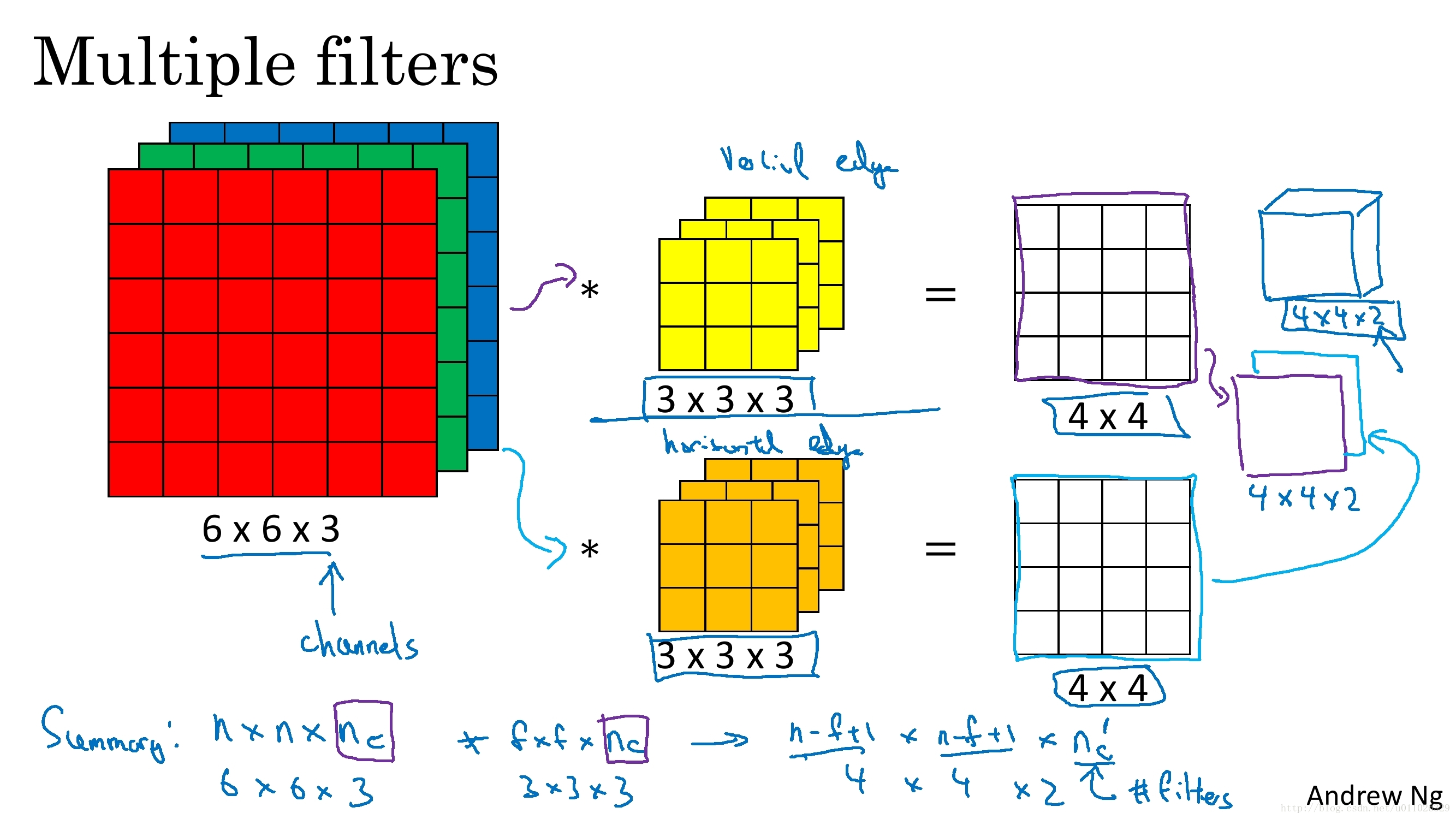
这大概就是CNN的一个神奇之处,尽管只有这么少的参数,依旧有出色的性能。但是,这样仅提取了图像的一种特征,如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像的不同映射下的特征,称之为Feature Map。如果有100个卷积核,最终的权值参数也仅为100 × 100 = 10^4个而已。另外,偏置参数也是共享的,同一种卷积核共享一个。
CNN中的池化层
池化层可以非常有效地缩小矩阵的尺寸,从而减少最后全连接层中的参数。使用池化层既可以加快计算速度也有防止过拟合问题的作用。
池化层:对输入的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征,如下:
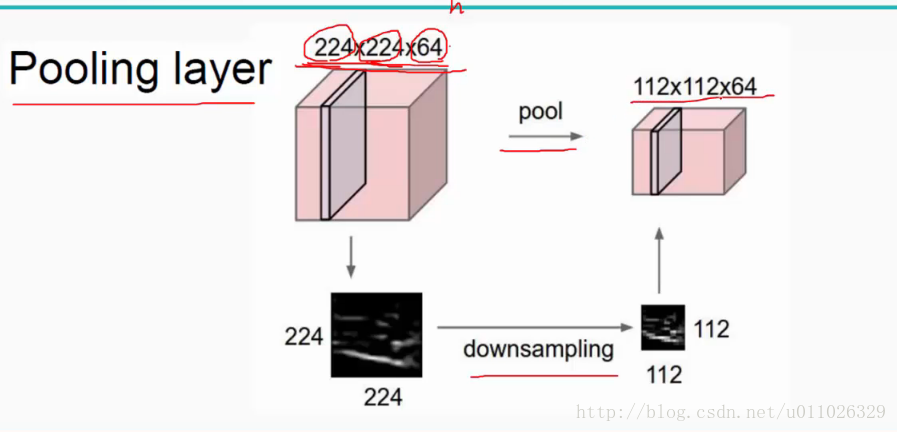
池化层最常见的包括最大值池化(max pooling)和平均值池化(average pooling)
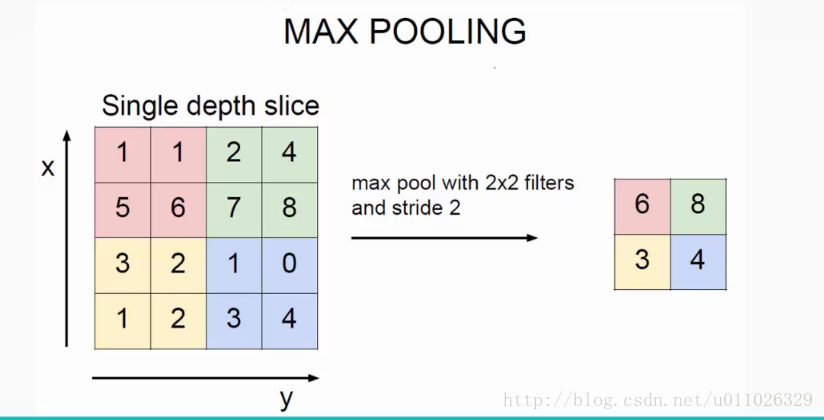
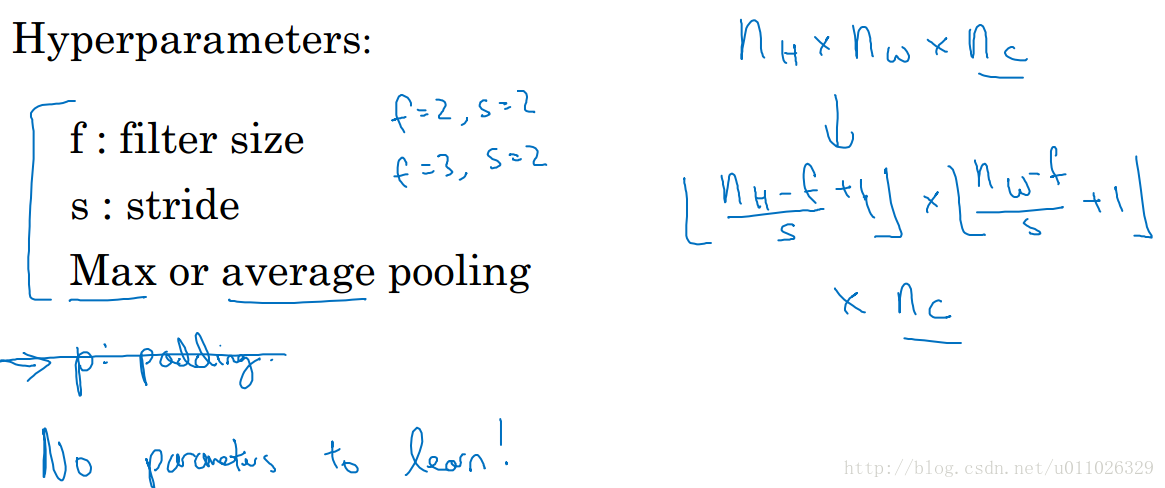
CNN 池化层不会改变网络的深度 nc n c
CNN中的全连接层
全连接层:连接所有的特征,将输出值送给分类器(如softmax分类器)。
总的一个结构大致如下:
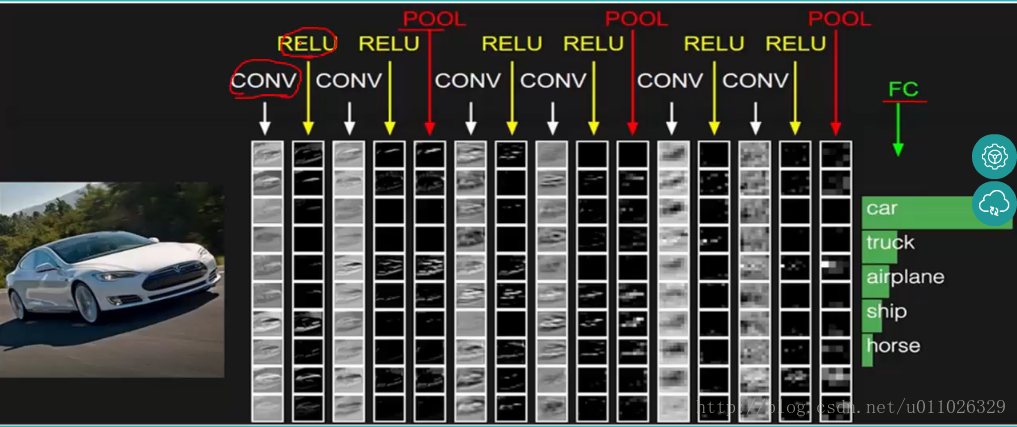
另外:CNN网络中前几层的卷积层参数量占比小,计算量占比大;而后面的全连接层正好相反,大部分CNN网络都具有这个特点。因此我们在进行计算加速优化时,重点放在卷积层;进行参数优化、权值裁剪时,重点放在全连接层。
计算机是怎么存储图片的
为了更好的理解计算机对图片的存储,我找了一个非常简单的图片,是一个385*385(像素)的jpg格式的图片,如图1所示,这个图片就是一个白色为底色,数字为黑色的数字“2”,也就是说,图片中只涉及两种颜色——黑与白(实际上并不是,因为图片在显示器中显示是一个像素一个像素的,黑白相间的地方其实并不是纯黑或者纯白的,将图片经过稍后描述的处理后也可以看出来,不过简单起见,我们就当它是黑白两色的)。


可以使用scipy包中的imread函数将图片转换为数值型矩阵
from scipy.misc import imreadimport pandas as pd
img = imread('2.jpg')
print(img.shape)
img_df=pd.DataFrame(img)
img_df.to_csv('2.csv')上面的代码不用太过研究,能实现这个过程的方法很多。其实图片在计算机中就是数字,385*385=148225,图片中有148225个数字,每个数字其实就是该像素的颜色对应的数值(如白色是255),那么我们来看一下图片转换成为的矩阵是什么样子,如图2所示(我把csv按比例缩放了一下,看的比较清楚)。

是不是惊艳到了!!!原来这个2在计算机中是这么存储的,好,我把局部放大一下,如图3所示,图3这个区域放大了,所以你可能看不太出来这是个啥,其实就是图4中红色圆圈的部分。
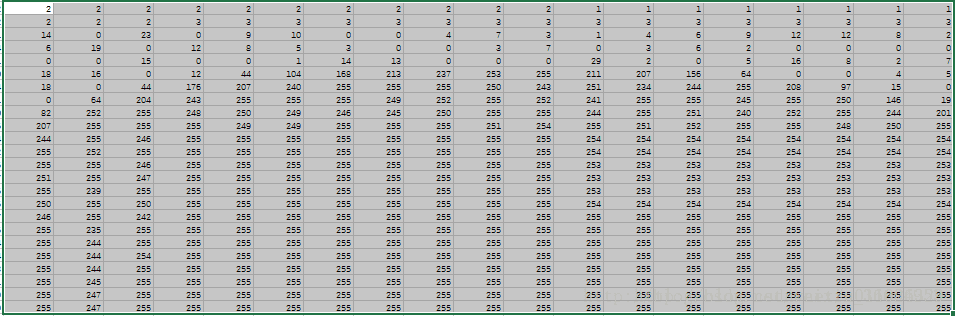
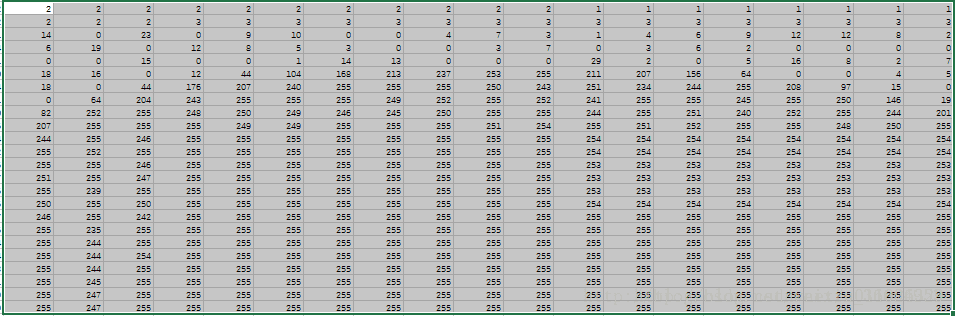
现在你可能明白了,其实每个图片都由若干像素点构成,每个像素点存储了该位置的颜色,其实还隐藏存储了另一个信息,就是位置。每一个像素点都有一对索引元组,例如(1,1)就是第一行第一列的像素点,如果写作(1,1,255),就是说第一行第一列的像素点是黑色,以此类推,也就是这样一个矩阵就完整的记录着图片的所有信息。
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











