







文章目录
TensorFlow:2015年谷歌,支持python、C++,底层是C++,主要用python。支持CNN、RNN等算法,分CPU TensorFlow/GPU TensorFlow。
TensorBoard:训练中的可视化。
快捷键:shift+enter执行命令,Tab键进行补全,ctrl+b隐藏导航栏,shift+tab显示函数的详细描述
基础知识
创建图,启动图
#创建一个常量op
m1 = tf.constant([[3,3]]) #两行一列
m2 = tf.constant([[2],[3]]) #一行两列
# 创建一个矩阵乘法op
product = tf.matmul(m1,m2)
print(product) #结果返回一个tensor
# Tensor("MatMul:0", shape=(1, 1), dtype=int32)
#定义一个会话,启动默认的图
sess = tf.Session()
# run(product)触发了图中三个op
result = sess.run(product)
print(result)
sess.close()
# [[15]]
# 另外一种写法
with tf.Session() as sess:
result = sess.run(product)
print(result)
# 不需要关闭操作
变量的使用
x = tf.Variable([1,2])
a = tf.constant([3,3])
# 增加一个减法op
sub = tf.subtract(x,a)
# 增加一个加法op
add= tf.add(x,sub)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(sub))
print(sess.run(add))
#Attempting to use uninitialized value Variable_1
for循环
# 变量和操作其实是可以起名字的
status = tf.Variable(0,name = 'counter')
new_value = tf.add(status,1)
# 赋值op new_value赋值给status
update = tf.assign(status,new_value)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(status))
for _ in range(5):
sess.run(update)
print(sess.run(status))
fetch、feed的使用
# fetch 同时执行多个op
input1 = tf.constant(3.0)
input2 = tf.constant(2.0)
input3 = tf.constant(5.0)
add = tf.add(input2, input3)
mul = tf.multiply(input1,add)
with tf.Session() as sess:
result = sess.run([mul,add])
print(result)
# feed
input1 = tf.placeholder(tf.float32)#创建占位符
input2 = tf.placeholder(tf.float32)
output = tf.multiply(input1,input2)
with tf.Session() as sess:
# feed的数据以字典的形式传入
print(sess.run(output, feed_dict = {input1:[7.],input2:[2.0]}))
线性规划
# 线性规划
x_data = np.random.rand(100)
y_data = x_data*0.1 + 0.2
b = tf.Variable(0.)
k = tf.Variable(0.)
y = k*x_data + b
# 二次代价函数
loss = tf.reduce_mean(tf.square(y_data-y)) #误差平方均值
# 定义一个梯度下降法来进行训练的优化器
optimizer = tf.train.GradientDescentOptimizer(0.2) # 随机梯度下降法,学习率0.2
# 最小化代价函数
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for step in range(201):
sess.run(train)
if step%20 ==0:
print(step,sess.run([k,b]))
'''
0 [0.053777255, 0.10018825]
20 [0.10350733, 0.19811046]
40 [0.102103, 0.19886708]
60 [0.10126095, 0.1993207]
80 [0.10075606, 0.1995927]
100 [0.10045333, 0.19975579]
120 [0.10027182, 0.19985357]
140 [0.100162975, 0.1999122]
160 [0.10009772, 0.19994736]
180 [0.10005858, 0.19996844]
200 [0.10003512, 0.1999811]
'''
损失函数比较
二次代价函数
合理的是:在离目标远的地方更新的比较快,离目标近的地方更新的比较慢。之所以要慢,就是怕太快了,跳过最优解。
二次代价函数问题:w和b的梯度跟激活函数的梯度成正比。如果最终的结果由0更新到4,更新的速度由快到慢。如果最终的结果由4更新到-4,更新的速度由慢到快到慢,不合理。


交叉熵损失
w和b的梯度跟激活函数的梯度无关。梯度公式sigma-y表示预测值与实际值的误差,所以当误差较大时,梯度就越大,参数w和b调整的就快,训练的速度也会越来越快,符合预期。

二次代价函数与交叉熵代价函数的比较:如果输出神经元是线性的,那么二次代价函数就是一种合适的选择,如果输出神经元是S型函数,那就比较适合交叉熵代价函数。



实验
minist数据库,二次代价函数,迭代7次就到达90%,14次91%。
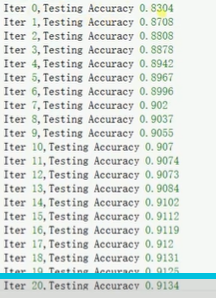
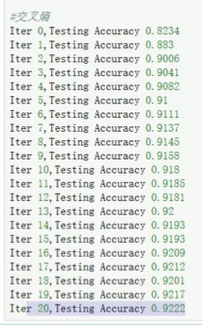
minist数据库,交叉熵函数(softmax_cross_entropy_with_logits),迭代2次就到达90%,5次91%,收敛速度显比二次代价小很多明。
提高准确度:
1、每个批次的大小,50-300
2、更改初始化方法
3、尝试不同的激活函数
4、尝试dropout(参数)、不同正则
5、网络的深度、网络的宽度,五六万张,三层神经网络比较匹配。
6、尝试不同的损失函数
7、改变学习率
8、尝试不同的优化器
9、迭代次数epoch
过拟合
为什么正则能够防止过拟合?
L1正则,会使一些w等于0。
L2正则,也会使一些w变得非常小,接近0。
实验:增加层数,初始化方法

实验:增加层数,初始化方法,增加dropout 0.7 
过拟合有所改正,但收敛速度会变慢。当网络非常复杂的时候,如imagenet比赛那种,dropout会更明显。
优化器


注:Adagrad适用于数据不平衡的数据集。优点:不需要人为的调解学习率。缺点:随着迭代的次数增加,学习率会越来越小,最终趋近于0。
针对Adagrad的缺点如何改进? RMSprop,学习率不会趋近于0。
有没有不需要学习率的优化器?Adadelta。
SGC缺点:收敛速度慢,无法解决“鞍点”的问题。
SGD这么多缺点是不是就被抛弃掉:SGD虽然速度慢,但在确准率上不一定。为了提高准确率,最好每种优化器都要试一下。
Momentum特点:模型收敛速度很快,经常会走一些无效的路径。
AdamOptimizer:学习率一般比10^-2还要小,一般设置的很小,0.001或者0.0001,一般比SGD要小。速度比SGD要快。

tensorboard
CNN
神经网络训练样本数经验:训练集数量是参数5-30倍。
卷积核就是滤波器
max-pooling
mean-poolong
随机pooling:随机找一个值
卷积:same padding 和 valid padding。
池化:same padding 和 valid padding。
文章目录
tf.nn.embedding_lookup()
格式:
tf.nn.embedding_lookup(
params,
ids,
partition_strategy=‘mod’,
name=None,
validate_indices=True,
max_norm=None
)
参数:
params: 表示完整的嵌入张量,或者除了第一维度之外具有相同形状的P个张量的列表,表示经分割的嵌入张量
ids: 一个类型为int32或int64的Tensor,包含要在params中查找的id
partition_strategy: 指定分区策略的字符串,如果len(params)> 1,则相关。当前支持“div”和“mod”, 默认为“mod”。
name: 操作名称(可选)
validate_indices: 是否验证收集索引
max_norm: 如果不是None,嵌入值将被l2归一化为max_norm的值
在Word2vec中会用到这个函数。
例子:
#coding:utf-8
import tensorflow as tf
import numpy as np
c = np.random.random([5,1]) ##随机生成一个5*1的数组
b = tf.nn.embedding_lookup(c, [1, 3]) ##查找数组中的序号为1和3的
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
print(sess.run(b))
print(c)
# 结果:
#b:[[0.27341454]
# [0.96676304]]
#c:[[0.66141005]
# [0.27341454]
# [0.68577857]
# [0.96676304]
# [0.46089145]]
tf.nn.nce_loss()
格式:
def nce_loss(weights, biases, inputs, labels, num_sampled, num_classes,
num_true=1,
sampled_values=None,
remove_accidental_hits=False,
partition_strategy=“mod”,
name=“nce_loss”)
功能:计算并返回噪声对比估计(NCE, Noise Contrastive Estimation)训练损失。
参数:
weights:一个Tensor,shape为[num_classes, dim],或者是Tensor对象列表,其沿着维度0的连接具有shape [num_classes,dim]。
biases:一个Tensor,shape为[num_classes],类偏差。
labels:一个Tensor,类型为int64和shape [batch_size, num_true],目标类。
inputs:一个Tensor,shape [batch_size, dim]。输入网络的正向激活。
num_sampled:int,每批随机抽样的类数。
num_classes:int,可能的类数。
num_true:int,每个训练示例的目标类数。
tf.train.GradientDescentOptimizer()
格式:tf.train.GradientDescentOptimizer(learning_rate, use_locking=False,name=’GradientDescent’)
功能:优化器。
参数:
learning_rate: A Tensor or a floating point value,要使用的学习率。
use_locking: 要是True的话,就对于更新操作(update operations.)使用锁。
name: 名字,可选,默认是”GradientDescent”。
例子:
import tensorflow as tf
x = tf.Variable(2, name='x', dtype=tf.float32)
log_x = tf.log(x)
log_x_squared = tf.square(log_x)
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(log_x_squared)
init = tf.initialize_all_variables()
def optimize():
with tf.Session() as session:
session.run(init)
print("starting at", "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
for step in range(10):
session.run(train)
print("step", step, "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
optimize()
#结果:
#starting at x: 2.0 log(x)^2: 0.480453
#step 0 x: 1.6534264 log(x)^2: 0.25285786
#step 1 x: 1.3493005 log(x)^2: 0.08975195
#step 2 x: 1.1272697 log(x)^2: 0.014351694
#step 3 x: 1.0209966 log(x)^2: 0.0004317743
#step 4 x: 1.0006447 log(x)^2: 4.1534943e-07
#step 5 x: 1.0000006 log(x)^2: 3.5527118e-13
#step 6 x: 1.0 log(x)^2: 0.0
#step 7 x: 1.0 log(x)^2: 0.0
#step 8 x: 1.0 log(x)^2: 0.0
#step 9 x: 1.0 log(x)^2: 0.0
minimize() :梯度计算和参数更新两个操作
compute_gradients() :函数用于获取梯度
apply_gradients(): 用于更新参数
tf.random_uniform()
格式:
random_uniform(
shape,
minval=0,
maxval=None,
dtype=tf.float32,
seed=None,
name=None
)
功能:从均匀分布中输出随机值。生成的值在该 [minval, maxval) 范围内遵循均匀分布,下限 minval 包含在范围内,而上限 maxval 被排除在外。对于浮点数,默认范围是 [0, 1)。用来做初始化。
参数:
shape:一维整数张量或 Python 数组,输出张量的形状。
minval:dtype 类型的 0-D 张量或 Python 值;生成的随机值范围的下限;默认为0.
maxval:dtype 类型的 0-D 张量或 Python 值.要生成的随机值范围的上限,如果 dtype 是浮点,则默认为1。
dtype:输出的类型:float16、float32、float64、int32、orint64。
seed:一个 Python 整数,用于为分布创建一个随机种子。查看 tf.set_random_seed 行为。
name:操作的名称(可选)。
例子:
import tensorflow as tf
with tf.Session() as sess:
print(sess.run(tf.random_uniform(
(6,6), minval=-0.5,
maxval=0.5, dtype=tf.float32)))
# 结果:
#[[ 0.22067761 -0.23697007 -0.27792156 -0.19219089 -0.04778063 -0.09754169]
# [ 0.3165928 -0.3930397 -0.411559 -0.47160363 -0.3989321 0.05053937]
# [-0.36394072 -0.3138739 0.16599143 0.48196137 0.47544062 -0.22295702]
# [ 0.49236917 -0.42440557 -0.29696238 0.03384793 -0.24676847 0.23208869]
# [ 0.1420126 0.2645086 -0.43570924 0.25621068 0.17929697 0.01833749]
# [-0.3911531 -0.41240644 -0.49978328 -0.30677032 0.04667234 -0.05241919]]
tf.truncated_normal()
格式:
truncated_normal(
shape,
mean=0.0,
stddev=1.0,
dtype=tf.float32,
seed=None,
name=None
)
功能:产生截断正态分布随机数,取值范围为 [ mean - 2 * stddev, mean + 2 * stddev ]。
参数:
shape:必选,1维整形张量或array,输出张量的维度。
mean:0维张量或数值,均值。
stddev:0维张量或数值,标准差。
dtype:输出类型。
seed:随机种子,若seed赋值,每次产生相同随机数。
name:运算名称。
例子:
import tensorflow as tf
import matplotlib.pyplot as plt
tn = tf.truncated_normal([20],mean=5,stddev=1)
sess = tf.Session()
ov = sess.run(tn)
# 结果:
#[4.761795 4.879238 5.512024 4.0696497 3.7318196 4.775479 3.6837173
# 6.296341 3.9887147 5.108976 4.6989813 4.742924 4.693607 5.911699
# 3.5907323 4.1943345 6.249139 3.7722433 4.8389206 5.9726944]
tf.multiply()
格式: tf.multiply(x, y, name=None)
功能:两个矩阵中对应元素各自相乘
参数:
x: 一个类型为:half, float32, float64, uint8, int8, uint16, int16, int32, int64, complex64, complex128的张量。
y: 一个类型跟张量x相同的张量。
返回值: x * y element-wise.
注意:
(1)multiply这个函数实现的是元素级别的相乘,也就是两个相乘的数元素各自相乘,而不是矩阵乘法,注意和tf.matmul区别。
(2)两个相乘的数必须有相同的数据类型,不然就会报错。
例子:
import tensorflow as tf
a = tf.constant([1, 2, 3, 4, 5, 6], shape=[2, 3])
b = tf.constant([7, 8, 9, 10, 11, 12], shape=[3, 2])
c = tf.matmul(a, b)
d = tf.multiply(a, a)
with tf.Session() as sess:
print(sess.run([a]))
print(sess.run([b]))
print(sess.run([c]))
print(sess.run([d]))
#a:[array([[1, 2, 3],
# [4, 5, 6]], dtype=int32)]
#b:[array([[ 7, 8],
# [ 9, 10],
# [11, 12]], dtype=int32)]
#c:[array([[ 58, 64],
# [139, 154]], dtype=int32)]
#d:[array([[ 1, 4, 9],
# [16, 25, 36]], dtype=int32)]
tf.matmul()
格式: tf.matmul(a, b, transpose_a=False, transpose_b=False, adjoint_a=False, adjoint_b=False, a_is_sparse=False, b_is_sparse=False, name=None)
功能:矩阵相乘。
参数:
a: 一个类型为 float16, float32, float64, int32, complex64, complex128 且张量秩 > 1 的张量。
b: 一个类型跟张量a相同的张量。
transpose_a: 如果为真, a则在进行乘法计算前进行转置。
transpose_b: 如果为真, b则在进行乘法计算前进行转置。
adjoint_a: 如果为真, a则在进行乘法计算前进行共轭和转置。
adjoint_b: 如果为真, b则在进行乘法计算前进行共轭和转置。
a_is_sparse: 如果为真, a会被处理为稀疏矩阵。
b_is_sparse: 如果为真, b会被处理为稀疏矩阵。
name: 操作的名字(可选参数)
返回值: 一个跟张量a和张量b类型一样的张量且最内部矩阵是a和b中的相应矩阵的乘积。
注意:
(1)输入必须是矩阵(或者是张量秩 >2的张量,表示成批的矩阵),并且其在转置之后有相匹配的矩阵尺寸。
(2)两个矩阵必须都是同样的类型,支持的类型如下:float16, float32, float64, int32, complex64, complex128。
tf.reduce_sum()
格式:tf.reduce_sum(input_tensor,axis=None,keep_dims=False,name=None)
功能:对tensor x求和。
参数:
input_tensor :是要求和的 tensor
axis:是要求和的列或行,axis=0表示列,1表示行,默认所有维度都要求和。
keep_dims:求和后是否保持维度,否则就降维。
例子:
x = tf.constant([[1, 1, 1], [1, 1, 1]])
a= tf.reduce_sum(x)
b = tf.reduce_sum(x, 0)
c = tf.reduce_sum(x, axis=0)
d = tf.reduce_sum(x, 1)
e = tf.reduce_sum(x, 1, keep_dims=True)
f = tf.reduce_sum(x, [0, 1])
with tf.Session() as sess:
print(sess.run([a]))
print(sess.run([b]))
print(sess.run([c]))
print(sess.run([d]))
print(sess.run([e]))
print(sess.run([f]))
# 结果:
#a:[6]
#b:[array([2, 2, 2], dtype=int32)]
#c:[array([2, 2, 2], dtype=int32)]
#d:[array([3, 3], dtype=int32)]
#[e:array([[3],
# [3]], dtype=int32)]
#f:[6]
tf.reduce_mean()
tf.reduce_mean(
input_tensor,
axis=None,
keep_dims=False,
name=None,
reduction_indices=None
)
功能:计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值。,主要用作降维或者计算tensor的平均值。
参数:
input_tensor: 输入的待降维的tensor
axis: 指定的轴,如果不指定,则计算所有元素的均值
keep_dims:是否降维度,默认False。设置为True,输出的结果保持输入tensor的形状,设置为False,输出结果会降低维度
name: 操作的名称
reduction_indices:在以前版本中用来指定轴,已弃用
例子:
import tensorflow as tf
x = [[1,2,3],
[4,5,6]]
y = tf.cast(x, tf.float32) # tensor
mean_all = tf.reduce_mean(y)
mean_0 = tf.reduce_mean(y, axis=0)
mean_1 = tf.reduce_mean(y, axis=1)
with tf.Session() as sess:
m_all,m_0,m_1 = sess.run([mean_all, mean_0, mean_1])
print(m_all)
print(m_0)
print(m_1)
# 结果:3.5
# [2.5 3.5 4.5]
# [2. 5.]
tf.square()
tf.square(x, name=None)
功能:对x内的所有元素进行平方操作。
import tensorflow as tf
x = [3,5,1]
with tf.Session() as sess:
print(sess.run(tf.square(x)))
# 结果:[ 9 25 1]
# tf.sqrt()
tf.cast()
格式:
cast(
x,
dtype,
name=None
)
功能:将x的数据格式转化成dtype数据类型
例子:
import sys
import tensorflow as tf
a = tf.Variable([1.0,1.3,2.1,3.41,4.51])
b = tf.cast(a>3,dtype=tf.bool)
c = tf.cast(a>3,dtype=tf.int8)
e = tf.cast(a<2,dtype=tf.float32)
d = tf.cast(a,dtype=tf.int8)
sess = tf.Session()
sess.run(tf.initialize_all_variables())
print(sess.run(a))
print(sess.run(b))
print(sess.run(c))
print(sess.run(e))
print(sess.run(d))
# 结果:[1. 1.3 2.1 3.41 4.51]
# [False False False True True]
# [0 0 0 1 1]
# [1. 1. 0. 0. 0.]
# [1 1 2 3 4]
参考:
https://www.cnblogs.com/harvey888/p/6930726.html















 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









