







参考:http://www.matrix67.com/blog/archives/292
c=(0.285,0)的图不知道为什么弄不出来QAQ
用cuda写了一下Julia分形
直接生成bmp (下次写个带交互的能放大缩小的
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <iostream>
#include <cmath>
#include <iomanip>
#include <fstream>
#include <Windows.h>
#include <wingdi.h>
using namespace std;
struct BMP {
template<class T>
void wri(ofstream &os, T data) {
//小端输出
int len = sizeof(T);
char *p = new char[len];
for (int i = 0; i < len; ++i) {
p[i] = data % 256;
data >>= 8;
}
os.write(p, len);
}
BITMAPFILEHEADER p1;
BITMAPINFOHEADER p2;
unsigned char *src;
int wid, hei;
BMP(unsigned char *source, int width, int height):
src(source), wid(width), hei(height) {
p1.bfType = 0x4d42;//"MB" 小端输出变成"BM"
p1.bfSize = 54 + width * height * 4;
p1.bfReserved1 = p1.bfReserved2 = 0;
p1.bfOffBits = 54;
p2.biSize = 40;//40 (in windows)
p2.biWidth = width;
p2.biHeight = height;
p2.biPlanes = 1;
p2.biBitCount = 32;
p2.biCompression = 0;
p2.biSizeImage = width * height * 4;
p2.biXPelsPerMeter = width;
p2.biYPelsPerMeter = height;
p2.biClrUsed = 0;
p2.biClrImportant = 0;
}
void write(string path) {
ofstream out(path, ios_base::out | ios_base::binary);
wri(out, p1.bfType);
wri(out, p1.bfSize);
wri(out, p1.bfReserved1);
wri(out, p1.bfReserved2);
wri(out, p1.bfOffBits);
wri(out, p2.biSize);
wri(out, p2.biWidth);
wri(out, p2.biHeight);
wri(out, p2.biPlanes);
wri(out, p2.biBitCount);
wri(out, p2.biCompression);
wri(out, p2.biSizeImage);
wri(out, p2.biXPelsPerMeter);
wri(out, p2.biYPelsPerMeter);
wri(out, p2.biClrUsed);
wri(out, p2.biClrImportant);
out.write((char*)src, wid*hei*4);
out.close();
}
};
struct c2 {
float x, y;
__device__ c2(float _x = 0, float _y = 0) : x(_x), y(_y) {}
__device__ c2 operator + (const c2 &t) {
return c2(x+t.x, y+t.y);
}
__device__ c2 operator - (const c2 &t) {
return c2(x - t.x, y - t.y);
}
__device__ c2 operator * (const c2 &t) {
return c2(x*t.x - y*t.y, x*t.y + y*t.x);
}
__device__ c2 operator / (const int &t) {
return c2(x / t, y / t);
}
__device__ float square() {
return x*x + y*y;
}
};
void HANDLE_ERROR(cudaError_t status);
void cudaCalc(unsigned char *res, int width, int height);
const unsigned int WIDTH = 8192, HEIGHT = 8192;
int main()
{
HANDLE_ERROR(cudaSetDevice(0));
unsigned char *p = new unsigned char[WIDTH * HEIGHT * 4];
cudaCalc(p, WIDTH, HEIGHT);
HANDLE_ERROR(cudaDeviceReset());
BMP s(p, WIDTH, HEIGHT);
s.write(".//a.bmp");
return 0;
}
void HANDLE_ERROR(cudaError_t status) {
if (status != cudaSuccess) {
fprintf(stderr, "Error~\n");
exit(0);
}
}
__global__ void kernel(unsigned char *p, int width, int height) {
float x1 = -1.6, y1 = -1.6, x2 = 1.6, y2 = 1.6;
c2 c(-0.8, 0.156);
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int cnt = (y*width+x)*4;
if (x < width && y < height) {
c2 sp(x1 + (x2-x1) * x / width, y1 + (y2-y1) * y / height);
int i;
for (i = 0; i < 100; ++i) {
sp = sp * sp + c;
if (sp.square() >= 1000)
break;
}
sp = sp / sqrt(sp.square());
float gi = 1.0f * i / 100;
p[cnt] = 255 * gi;
p[cnt + 1] = (1.0-sp.x) * 255 * gi;
p[cnt + 2] = (1.0-sp.y) * 255 * gi;
p[cnt + 3] = 0;
}
return;
}
void cudaCalc(unsigned char *res, int width, int height) {
unsigned char *p = 0;
HANDLE_ERROR(cudaMalloc((void**)&p, width*height*4));
dim3 blockDim(32, 32);
dim3 gridDim((width + 31) / 32, (height + 31) / 32);
kernel << <gridDim, blockDim >> > (p, width, height);
cudaError_t status;
status = cudaGetLastError();
if (status != cudaSuccess) {
fprintf(stderr, "Build kernel failed.\n");
goto Error;
}
status = cudaDeviceSynchronize();
if (status != cudaSuccess) {
fprintf(stderr, "kernel run failed.\n");
goto Error;
}
status = cudaMemcpy(res, p, width*height*4, cudaMemcpyDeviceToHost);
if (status != cudaSuccess) {
fprintf(stderr, "cudaMemCpy Error!\n");
goto Error;
}
Error:
cudaFree(p);
return;
}样图:
c=(-0.8,0.156)

c=(0.285,0.01)
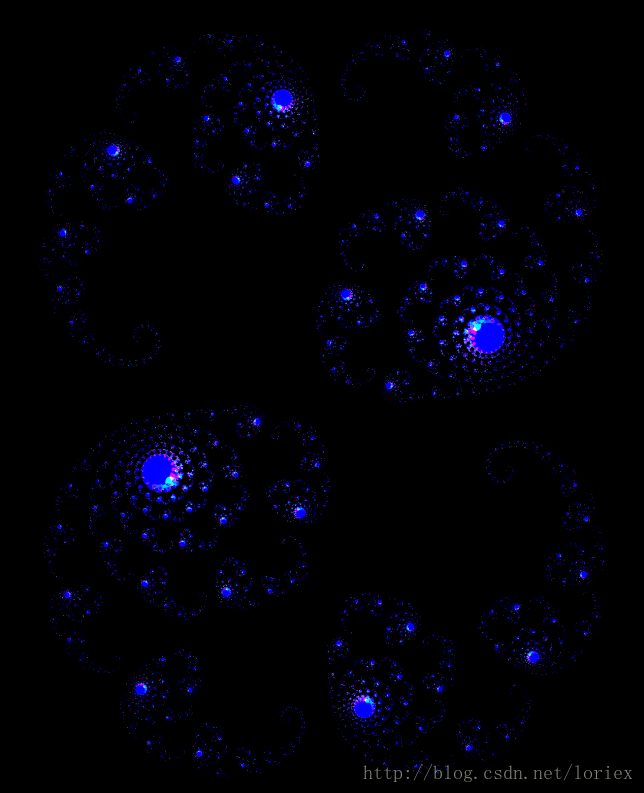
c=(0.285,-0.01)
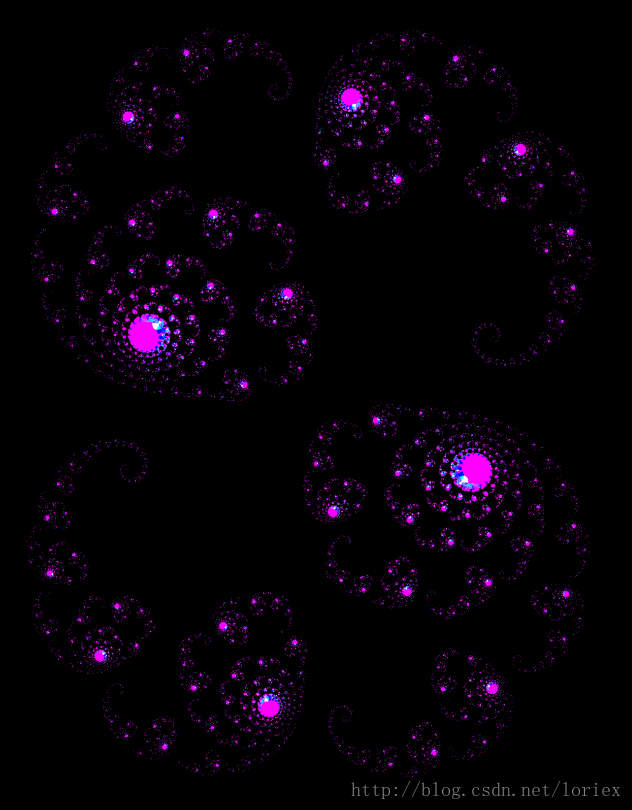
后来又发现了一个奇怪的问题
__global__ void kernel(unsigned char *p, int width, int height) {
float x1 = -1.6f, y1 = -1.6f, x2 = 1.6f, y2 = 1.6f;
c2 c(0.285f, 0.01f);
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int cnt = (y*width + x) * 4;
if (x < width && y < height) {
c2 sp(x1 + (x2 - x1) * x / width, y1 + (y2 - y1) * y / height);
int i;
for (i = 0; i < 100; ++i) {
sp = sp * sp + c;
if (sp.square() >= 1000)
break;
}
sp = sp / sqrt(sp.square());
float gi = 1.0 * i / 100;//******
p[cnt] = 255 * gi;
p[cnt + 1] = (1.0f - sp.x) * 255 * gi;
p[cnt + 2] = (1.0f - sp.y) * 255 * gi;
p[cnt + 3] = 0;
}
return;
}float gi = 1.0 * i / 100;
float gi = 1.0f * i / 100;
第一种写法的kernel运行时间比第二种写法多出近50%
原因推测:第一种写法做了double除法
更深层次的原因未知














 2271
2271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









