







CUDA并行编程的基本思路是把一个很大的任务划分成N个简单重复的操作,创建N个线程分别执行执行,每个网格(Grid)可以最多创建65535个线程块,每个线程块(Block)一般最多可以创建512个并行线程,在第一个CUDA程序中对核函数的调用是:
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
这里的<<<>>>运算符内是核函数的执行参数,告诉编译器运行时如何启动核函数,用于说明内核函数中的线程数量,以及线程是如何组织的。
<<<>>>运算符完整的执行配置参数形式是<<<Dg, Db, Ns, S>>>
- 参数Dg用于定义整个grid的维度和尺寸,即一个grid有多少个block。为dim3类型。Dim3 Dg(Dg.x, Dg.y, 1)表示grid中每行有Dg.x个block,每列有Dg.y个block,第三维恒为1(目前一个核函数只有一个grid)。整个grid中共有Dg.x*Dg.y个block,其中Dg.x和Dg.y最大值为65535。
- 参数Db用于定义一个block的维度和尺寸,即一个block有多少个thread。为dim3类型。Dim3 Db(Db.x, Db.y, Db.z)表示整个block中每行有Db.x个thread,每列有Db.y个thread,高度为Db.z。Db.x和Db.y最大值为512,Db.z最大值为62。 一个block中共有Db.x*Db.y*Db.z个thread。计算能力为1.0,1.1的硬件该乘积的最大值为768,计算能力为1.2,1.3的硬件支持的最大值为1024。
- 参数Ns是一个可选参数,用于设置每个block除了静态分配的shared Memory以外,最多能动态分配的shared memory大小,单位为byte。不需要动态分配时该值为0或省略不写。
- 参数S是一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
在第一个CUDA程序中使用了1个线程块,每个线程块包含size个并行线程,每个线程的索引是threadIdx.x。
也可以选择创建size个线程块,每个线程块包含1个线程,核函数的调用更改为:
addKernel<<<size, 1>>>(dev_c, dev_a, dev_b);
线程的索引更改为blockIdx.x。完整程序如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = blockIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
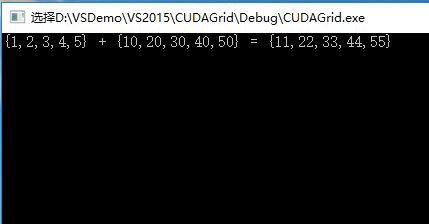
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
c[0], c[1], c[2], c[3], c[4]);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
getchar();
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
//addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
addKernel << <size, 1 >> > (dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
执行结果一致:
更普遍的情况是需要创建多个线程块,每个线程块包含多个并行线程,这种情况下线程索引的计算为:
int tid=threadIdx.x+blockIdx.x*blockDim.x;
blockIdx代表线程块在网格中的索引值,blockDim代表线程块的尺寸大小,另外还有gridDim代表网格的尺寸大小。
如果有N个并行的任务,我们希望每个线程块固定包含6个并行的线程,则可以使用以下的核函数调用:
addKernel<<<(N+5)/6, 6>>>(dev_c, dev_a, dev_b);
把第一个CUDA程序的向量个数增加到15个,修改成以上调用方式:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x + blockIdx.x*blockDim.x;
if (i < 15)
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 15;
const int a[arraySize] = { 1, 2, 3, 4, 5,6,7,8,9,10,11,12,13,14,15 };
const int b[arraySize] = { 10, 20, 30, 40, 50,60,70,80,90,100,110,120,130,140,150 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
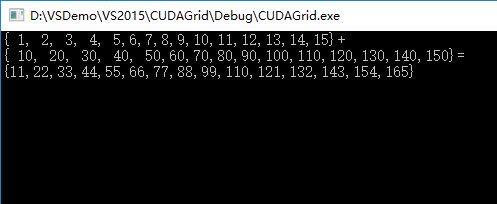
printf("{ 1, 2, 3, 4, 5,6,7,8,9,10,11,12,13,14,15}+\n{ 10, 20, 30, 40, 50,60,70,80,90,100,110,120,130,140,150}=\n{%d,%d,%d,%d,%d,%d,%d,%d,%d,%d,%d,%d,%d,%d,%d}\n",
c[0], c[1], c[2], c[3], c[4], c[5], c[6], c[7], c[8], c[9], c[10], c[11], c[12], c[13], c[14]);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
getchar();
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
//addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
addKernel << <(size + 5) / 6, 6 >> > (dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
执行结果:
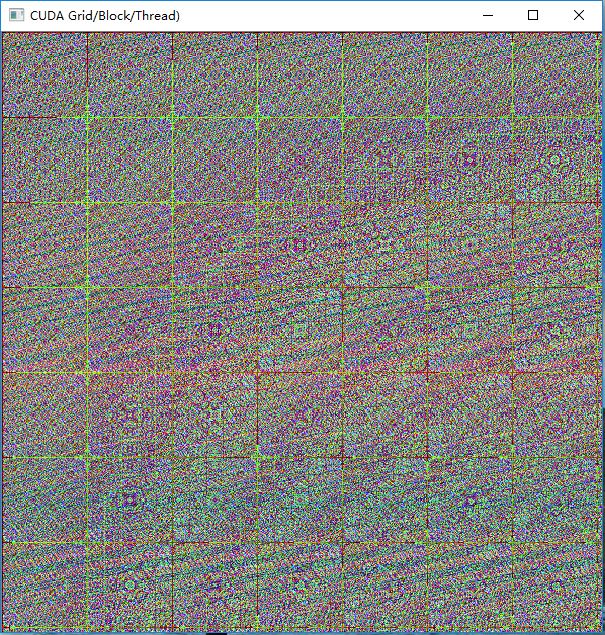
以下CUDA和OpenCV混合编程,对一幅图像上每个像素点的颜色执行一次运算,生成一幅规则的图形。
新建了一个 dim3类型的变量grid(DIM, DIM),代表一个二维的网格,尺寸大小是DIM*DIM个线程块:
#include "cuda_runtime.h"
#include <highgui.hpp>
using namespace cv;
#define DIM 600 //图像长宽
__global__ void kernel(unsigned char *ptr)
{
// map from blockIdx to pixel position
int x = blockIdx.x;
int y = blockIdx.y;
int offset = x + y * gridDim.x;
//BGR设置
ptr[offset * 3 + 0] = 999 * x*y % 255;
ptr[offset * 3 + 1] = 99 * x*x*y*y % 255;
ptr[offset * 3 + 2] = 9 * offset*offset % 255;
}
// globals needed by the update routine
struct DataBlock
{
unsigned char *dev_bitmap;
};
int main(void)
{
DataBlock data;
cudaError_t error;
Mat image = Mat(DIM, DIM, CV_8UC3, Scalar::all(0));
data.dev_bitmap = image.data;
unsigned char *dev_bitmap;
error = cudaMalloc((void**)&dev_bitmap, 3 * image.cols*image.rows);
data.dev_bitmap = dev_bitmap;
dim3 grid(DIM, DIM);
//DIM*DIM个线程块
kernel <<<grid, 1 >>> (dev_bitmap);
error = cudaMemcpy(image.data, dev_bitmap,
3 * image.cols*image.rows,
cudaMemcpyDeviceToHost);
error = cudaFree(dev_bitmap);
imshow("CUDA Grid/Block/Thread)", image);
waitKey();
}















 1422
1422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









