







文章目录
没有考虑障碍物
摘要
本文研究了一种无人机(UAV)辅助的无线供电物联网网络,其中旋翼无人机采用悬停通信协议依次访问有需求的物联网设备。在悬停期间,无人机以全双工模式工作,同时从目标设备收集数据并为其覆盖范围内的其他设备充电。考虑了实用的推进功耗模型和非线性能量收集模型。我们制定了一个多目标优化问题来共同优化三个目标:最大化总数据速率、最大化总收集能量和最小化无人机在特定任务期间的能量消耗。这三个目标部分地相互冲突,并且给出了权重参数来描述相关的重要性。由于物联网设备不断从物理周围环境中收集信息,并且其上传数据的需求动态变化,因此需要对无人机进行在线路径规划。
在本文中,我们应用深度强化学习算法来实现在线决策。提出了一种扩展的深度确定性策略梯度(DDPG)算法来学习无人机在多个目标上的控制策略。在训练过程中,智能体在按照需求优先级及时收集数据并避免设备数据溢出的基础上,学习在给定权重条件下生成最优策略。
贡献
研究了一个无人机辅助的无线供电物联网网络,其中无人机配备了全双工 HAP。
目标是最大化总数据速率和收集的能量,同时降低无人机的能耗。
提出了一种基于 DRL 的框架来解决多目标优化 (MOO) 问题。我们不是将系统的全部信息作为神经网络的输入,而是提取与无人机飞行决策密切相关的少量信息来构成状态向量。
-
我们提出了无线供电物联网网络中无人机辅助的数据采集和能量传输,其中物联网设备上传数据的要求是实时更新的,无人机采用飞行-悬停通信协议根据物联网设备的要求依次访问优先事项。
-
我们研究了一个旨在最大化总数据速率和总收集能量并同时最小化无人机能量消耗的 MOO 问题,其中开发了一种 MODDPG 算法来寻找无人机飞行决策的最佳策略。为了实现MOO,我们将奖励设计为一个4维向量,其中三个元素对应三个优化目标,另一个辅助元素确保基本任务的完成,并将经典的DDPG算法扩展到多维奖励。
-
通过训练结果,我们表明基于提出的MODDPG算法的最优策略比传统的基于规则的策略更灵活。通过修改权重参数,可以调整最优策略,实现不同优先级下多个目标的协调优化。
介绍
此外,由于高机动性、优异的机动性和低部署成本,无人机(UAV)已应用于无线网络,以提高通信覆盖范围、系统容量和部署效率[12] - [13] [14]. 结合 WPT,无人机可以为广泛分布的物联网设备执行直流和能量传输。它已成为物联网网络的关键组成部分[15]、[16]。
- 针对无人机辅助无线供电物联网网络优化的研究工作较多。
在[17] - [18] [19]中,DC 和能量传输是使用收获-然后传输协议进行处理的。它是基于时分多址方案,物联网设备在下行链路中收集能量,然后在上行链路中使用能量上传收集到的信息。
目标包括:
最大化所有物联网设备的上行链路吞吐量
最大化地面终端的最小吞吐量
总吞吐量最大化、总时间最小化和总能量最小化
最小化传感数据的信息年龄
在所有地面节点的数据速率约束下最小化无人机的总能量消耗
能源消耗和任务完成时间之间的权衡
- 面对复杂多变的物联网网络环境,无人机需要具备感知周围环境的能力和实时决策的能力。
目标包括:
实现目标区域内地面兴趣点的有效和公平的通信覆盖
设计了无人机的巡航路线,用于在传感区域进行数据收集
- 在大多数实际应用场景中,都部署了大量的地面节点来观察物理过程的实时更新,因此不能忽视传感数据的动态优先级要求
在[35]和[36],作者提出了数据生成模型来描述实时数据更新过程,并开发了基于深度 Q 网络(DQN)算法的无人机在线路径规划算法。
至于环境模型中状态空间的设计,在[30]、[32]和[34]中,所有用户和无人机的信息都包含在状态中。在[33]和[35]中,代理的观察被设置为一个地图,并作为卷积神经网络的输入。
系统模型—具有双天线无人机和单天线物联网设备
无人机配备了 HAP。当它悬停在相应的位置时,它以全双工模式运行。它通过一根天线在下行链路中向物联网设备传输能量,并在上行链路中与另一根天线同时从物联网设备收集数据。
物联网设备
我们考虑物联网设备在线监控各种物理过程的实际应用场景。关于他们观察到的过程的状态更新包被实时收集并存储在他们的数据缓冲区中。其中 Δt 是更新间隔,λj(t) 是设备 j 在 t 的数据生成率。
我们假设λj(t)服从泊松分布,不同器件的泊松分布参数不同。 lj(t) 的最大值通常受硬件限制,并假定以 [0,lmax] 为界,其中 lmax 是数据缓冲区的存储容量,并且假定所有设备都相同。如果数据缓冲区被数据填满,旧数据可能会被新数据覆盖,或者新收集的数据可能会被丢弃,这两种情况都会导致数据丢失。因此,物联网设备将收集到的信息及时上传到无人机非常重要。
我们假设物联网设备的信息传输采用时分多址协议,设备的上行发射功率为Pu。 lmax对应的传输数据大小为Q。在t时要传输的数据为
由于数据缓冲区的长度和数据生成速率因设备而异,因此它们上传数据的优先级不同。我们用 quj(t) 表示设备 j 的数据上传优先级。它被给出为
数据传输优先级不仅取决于采集到的数据与存储容量的比值,还受数据生成速率的影响。它包含对未来优先级的预测。
无人机
我们假设无人机以固定高度 H>0 飞行。时间 t 的水平位置记为 [xu(t),yu(t)] ,此处省略悬停高度。无人机实时确定其下一步行动并相应地更新位置。无人机的飞行控制由飞行速度 v(t) 和偏航角 θ(t) 描述,其中 v(t) 受最大飞行速度 vmax=20 m/s 和 θ(t)∈[−π ,π] 。飞行时,速度为 V 的推进功率消耗可通过 [24] 计算如下。
无人机的推进功率消耗包括翼型、感应功率和寄生功率,对应上式三部分。 P0 是悬停时的叶片轮廓功率,Utip 是转子叶片的尖端速度。 Pi 和 v0 表示悬停条件下的感应功率和平均转子感应速度。寄生功率d0、ρ、s、A分别表示机身阻力比、空气密度、旋翼密度和旋翼盘面积。
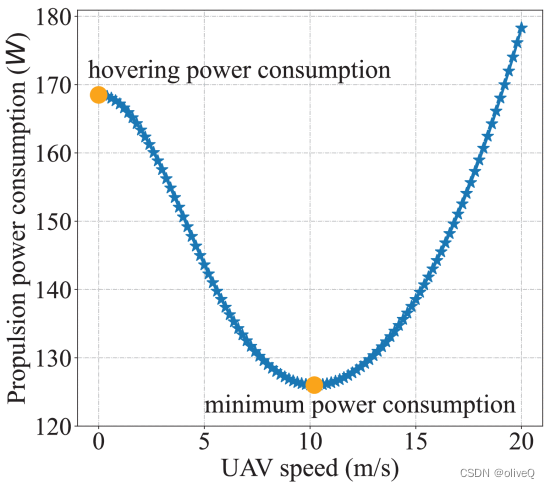
推进功率消耗随速度的变化趋势如图所示。我们可以发现,在加速过程中功率先减小后增大。与最低功耗相对应的速度称为最大耐力 (ME) 速度 VME 。并且悬停功耗Phov=P0+Pi可以通过设置V=0来计算。
我们假设无人机的直流和能量传输范围是有限的。无人机仅对覆盖范围内的物联网设备进行收费和收集数据。这个假设是合理的,因为当物联网设备离无人机太远时,通信效率低下。我们用 Ddc 和 Deh 表示数据收集和能量传输的最大覆盖半径。每时每刻,无人机都会选择一个物联网设备作为数据采集的目标设备。一旦目标设备落入 Ddc 内,无人机将悬停在相应位置,同时接收信息并向 Deh 内的其他设备传输能量,直到目标设备完成数据上传。我们用 Pd 表示无人机的下行发射功率。
Channel
我们将无人机与物联网设备 j 之间的无线通信链路的下行信道功率增益和上行信道功率增益分别表示为 hj(t) 和 gj(t)。考虑了结合视距(LoS)链路和非视距(NLoS)链路的实用空对地信道模型。对应的路径损失的数学描述如下
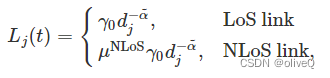
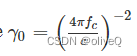
表示参考距离d0=1 m处的信道功率增益,fc表示载频,c表示光速。 dj-α~ 是无人机和物联网设备 j 之间的传播距离,其中 α~ 代表路径损耗指数。 μNLoS 是 NLoS 链路的附加衰减系数。对于物联网设备 j ,在时间 t 的 LoS 概率可以表示为
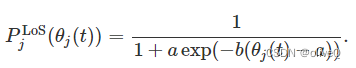
信道条件的 LoS 概率很大程度上取决于传播环境。 a 和 b 是常数值,取决于载波频率和环境类型。它还受到通信各方的相对位置的影响。

能量收集
无人机在悬停阶段以全双工模式工作。当它通过上行信道从目标设备接收信息时,它会以恒定的发射功率 Pd 继续向设备发射射频信号。除目标设备外,其能量传输覆盖范围内的设备将被充电。设备 j 的接收功率为
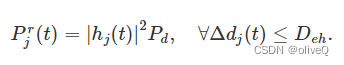
在本文中,我们应用了非线性 EH 模型 [37]。与线性模型不同,非线性EH模型考虑了电路的饱和限制,更实用。通过 RF-EH 电路,收集的能量由下式描述
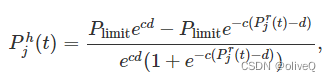
其中 Plimit 是最大输出直流功率,c 和 d 是常数,取决于 EH 系统的相关电路特性。
问题定义
在这项工作中,我们的目标是最大化总数据速率和总收集能量,同时最小化无人机的能量消耗。
无人机是感知物联网环境和实施实时路径规划所必需的。无人机飞行轨迹的决定和悬停位置的选择应考虑设备的服务质量和无人机的能耗。
此外,避免所有物联网设备的数据溢出非常重要。为此,无人机根据物联网设备的实时需求优先级依次访问。
例如,物联网设备 j^=argmaxjquj(t) 将被选为 t 时无人机的目标设备。当无人机飞得离目标设备足够近时,例如,dj(t)≤Ddc,它会悬停在相应的位置,并开始在上行链路中收集数据并在下行链路中传输能量。k表示无人机在任务中的第 k 次悬停,其中 K≥0 表示无人机悬停与物联网设备通信的总次数。我们将第 k 个悬停的相应通信设备表示为 jk 。那么第 k 次悬停时的传输数据速率为:

其中 W 是无线通信带宽,σ2n 是无人机的信道噪声功率。
要将所有收集到的数据上传到无人机,悬停时间可以通过下式计算
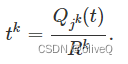
同时,无人机不断向其能量传输覆盖范围内的设备传输能量,除了下行链路中的设备 jk。根据 (8) (9),设备 j 的收获功率由下式给出
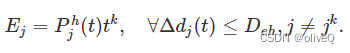
然后在第 k 次悬停时获得的总能量为
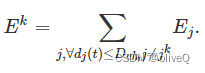
任务中所有悬停阶段的总数据速率和总收集能量如下所示。
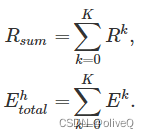
无人机在任务期间飞行和悬停的总能量消耗为
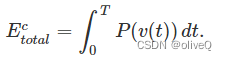
需要说明的是,能量消耗还包括通信能量。由于我们假设下行链路发射功率 Pd 为常数,因此该分量不包括在优化目标中。 MOO 问题可以表述为
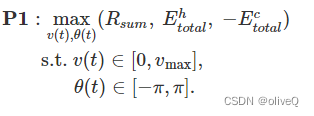
至于总数据率,其最大化取决于无人机任务期间上传数据的设备数量,即悬停的总数K和每次悬停的数据率。可以很容易地得出结论,为了最大化 Rsum,一方面,无人机应该以更高的速度飞行,以便它可以访问更多的物联网设备。另一方面,悬停位置应靠近目标设备,以提高数据速率并缩短每次悬停的通信时间。从这方面来说,将鼠标悬停在设备上是最好的选择。至于总收集能量的最大化,除了 K 的最大化,我们希望每次悬停时有更多的设备落入无人机的覆盖范围内。此外,无人机与充电设备之间的距离越小越好。它可能与无人机直接悬停在目标设备上以获得最大数据速率相冲突。至于无人机的能耗目标,显然VME可以实现其 最小化。 但是,收集更多数据和为更多设备充电可能不够快。 更重要的是,低飞行速度可能导致物联网设备的数据溢出。
正如我们所看到的,这三个目标部分地相互冲突。由于这些设备是随机分布的,并且它们的数据生成是动态的,因此找出最佳悬停位置并做出飞行决定非常复杂并且可能会产生相当大的计算成本。此外,环境是部分观察的,传统的基于模型的方法,如动态规划方法,无法解决这个问题。
近年来,DRL表现出出色的解决复杂问题的能力,被视为人工智能的核心技术之一。作为深度学习和强化学习的结合体,具有很强的理解能力和决策能力,可以实现端到端的学习。它在解决复杂的网络优化方面显示出巨大的潜力。 DDPG 是经典的 DRL 算法之一,已被证明可以使用低维观察在连续动作空间中学习有效的策略 [31]。
它适用于我们提出的无人机飞行决策问题,其中飞行速度和偏航角在连续区间内选择。由于原始 DDPG 算法的奖励是标量的,我们将其扩展到 MOO 问题的多维奖励。提出了一种用于无人机辅助数据收集的MODDPG算法,并引入了能量传递和权重参数来描述目标的偏好。
DQN不行—要连续动作
DQN 使用神经网络作为函数逼近器来逼近 Q 函数 [39]。并且通过最小化 Q 函数和目标值之间的损失来优化 Q 网络 θQ:
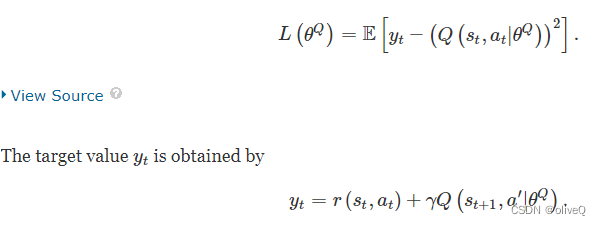
然而,DQN 只能对具有离散和低维动作空间的问题进行决策,无法解决连续动作控制问题。对于连续控制任务,应用了策略梯度算法,并在 [40] 中提出了一种actor-critic 方法。它结合了两种基于值(如 Q 学习)和动作概率(如策略梯度)的 RL 算法,因此可以毫不费力地从连续动作空间中选择正确的动作。基于 actor-critic 框架并从 DQN 的成功见解中学习,DDPG 在 [31] 中被提出,并被证明对于稳健地解决来自各个领域的具有连续动作空间的复杂问题是有效的。
无人机辅助数据采集和能量传输的MODDPG算法
Environmental Model
state space
收集所有物联网设备的实时服务需求依赖于无人机和物联网设备之间频繁的信息交换。会占用大量的无线资源,造成延迟,大大降低系统的效率。为了更实用,我们假设无人机只能观察到自己的状态和部分网络信息。具体来说,无人机可以观察到自己的位置,累计飞出禁区的次数,目标设备的位置,数据丢失的设备数量。然后状态空间被符号定义为
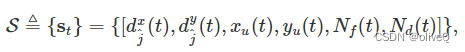
其中[dxj^ (t), dyj^ (t)]是笛卡尔坐标下目标设备与无人机的距离。一旦无人机完成对目标设备的数据采集,就会根据当时系统的状态选择一个新的。该元素有助于引导无人机将目标设备纳入其数据收集范围。
Nf(t) 记录了无人机在时间 t 前连续超出禁区的累计次数。
结合无人机的绝对位置[xu(t),yu(t)],有助于避免无人机飞出指定区域造成不必要的资源浪费。
而数据丢失 Nd(t) 的设备数量将驱动无人机及时为高需求设备提供服务。
在实际场景中,无人机无法获取全球网络信息,每个设备的实时信息是未知的。此外,大多数信息对于决策来说并不是必需的。在我们的设置中,我们提取一个 表示环境状态的少量必要信息。 状态空间的这些元素将使无人机对环境有良好的整体感知。 解决了海量不确定物联网系统普遍存在的网络信息缺失问题。
action space
观察状态,无人机实时做出动作决策。动作空间定义为
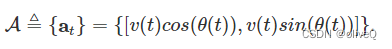
我们使用 [cos(θ(t)),sin(θ(t))] 来表示偏航,然后网络将学习归一化的二维向量。假设飞行速度v(t)和偏航角θ(t)分别在区间[0,vmax]和[-π,π]中是连续值。与离散动作空间相比,它扩大了无人机的控制自由度,提高了控制方案的效率。
Reward
由于环境是部分观察的,无人机依靠奖励来评估其决策、推断状态分布以及学习和了解环境。此外,代理依靠精心设计的奖励函数来学习针对提出的 MOO 问题的有效控制策略。根据我们的优化问题,奖励设计为 4 维向量。
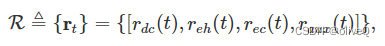
其中 rdc(t) 、 reh(t) 、 rec(t) 对应于三个优化目标:最大化总数据速率、最大化总收集能量和最小化无人机的能量消耗。它们的设计如下

一旦目标设备落入无人机的数据采集覆盖范围内,无人机就会悬停以进行数据采集和能量传输。否则无人机处于飞行阶段。我们给予代理更多的奖励,因为它更高的数据速率,更多的物联网设备在悬停时获得更多的能量,并惩罚它在飞行和悬停阶段的更高能量消耗。 wdc 、 weh 和 wec 是与每个属性关联的优先级权重。此外,还有一个辅助奖励 raux(t) 给出为
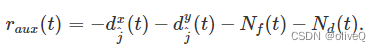
可以看出,raux(t)包括无人机与目标设备之间的距离。如果无人机距离目标设备较远,则它会很小,这有助于无人机识别目标设备的位置,从而靠近它。
此外,如果无人机试图飞出禁区或因未能及时收集数据而导致物联网设备数据溢出,则将获得负奖励。我们对无人机的错误飞行决策进行惩罚,以驱动无人机学习完成基本任务,无论优化目标的偏好如何。相应的权重 waux 一直设置为 1。
MODDPG Algorithm
基于 DDPG 架构,我们维护一个参与者网络 μ(s|θμ) 来指定构建从状态到动作的映射的主要策略和一个批评者网络 Q(s,a |θQ) 来估计动作值。θμ 和 θQ 是两个网络的参数。
演员网络和评论家网络的权重都是从以 0 为中心的截断正态分布初始化的,标准差为 √2/f,其中 f 是权重张量中输入单元的数量。偏差全部初始化为 0.001。
此外,目标网络被应用于actor-critic架构来计算目标值。具体来说,通过在初始化阶段复制mian网络的参数来创建目标actor网络μ’(s,a|θμ’)和目标critic网络Q’(s,a|θQ’)。
在更新网络参数时,随机小批量经验元组从重放内存中均匀采样。与原始的 DDPG 是带有标量奖励信号的单目标 MDP 不同,经验元组中的奖励是一个向量。
由于动作的价值取决于竞争目标之间的偏好,我们使用线性加权方法来计算具有给定权重的奖励向量元素的加权和,给出为 r=rwT ,其中 w=[wdc, weh,wec,waux] 。然后将奖励向量转换为标量形式。需要注意的是,通过这种设计,MODDPG 算法适用于任意数量目标的 MOO 问题。它还支持单目标优化(SOO)问题。在我们的设置中,所有的权重参数都是根据每个属性的重要性偏好在区间 [0.0, 1.0] 中选择的。使用目标网络,目标值 yi 计算如下。
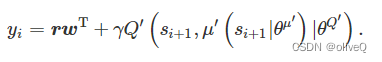
为了优化主评论家网络,我们计算了主评论家网络给出的目标值和 Q 函数之间的差异。然后用梯度下降法训练main-critic网络,最小化损失函数,定义为差值的均方误差。
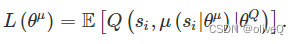
链式法则通过最大化 L(θμ) 来更新参与者网络权重。并且两个目标网络的参数将在训练期间使用“软”目标更新进行更新。
为了确保对连续动作空间的充分探索,将探索策略应用于参与者策略。详细地说,在每个决策步骤中,动作是从一个遵循高斯分布的随机过程中选择的,该过程具有期望 μ(st,|θμt) 和方差 εσ2 ,其中 ε 是一个可调整的参数,用于衰减训练过程的动作随机性。完整的算法在算法 1 中给出。
- 状态空间:无人机可以观察到自己的位置,累计飞出禁区的次数,目标设备的位置,数据丢失的设备数量。
- 动作空间:无人机实时做出动作决策,网络将学习一个归一化的二维向量(速度和偏航角是连续的)
- 奖励函数:三个优化目标:最大化总数据速率、最大化总收集能量和最小化无人机的能量消耗。
一旦目标设备落入无人机的数据采集覆盖范围内,无人机就会悬停以进行数据采集和能量传输。否则无人机处于飞行阶段。我们给予代理更多的奖励,因为它更高的数据速率,更多的物联网设备在悬停时获得更多的能量,并惩罚它在飞行和悬停阶段的更高能量消耗。
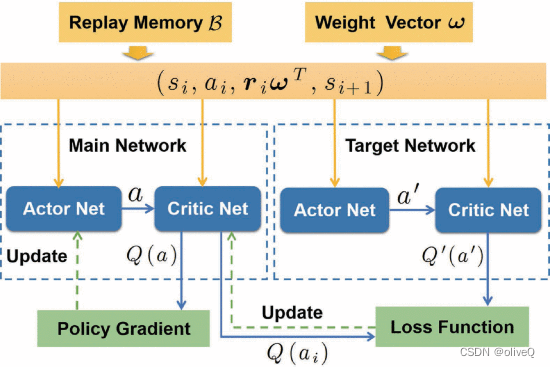
在更新网络参数时,随机小批量经验元组从重放内存中均匀采样。与原始的 DDPG 是带有标量奖励信号的单目标 MDP 不同,经验元组中的奖励是一个向量。由于动作的价值取决于竞争目标之间的偏好,我们使用线性加权方法来计算具有给定权重的奖励向量元素的加权和
为了优化主评论家网络,我们计算了主评论家网络给出的目标值和 Q 函数之间的差异。然后用梯度下降法训练主critic网络,最小化损失函数,定义为差值的均方误差。演员网络的损失函数可以简单地通过计算状态的 Q 函数之和来获得。我们使用主批评者网络并通过主要参与者网络计算的动作来计算 Q 函数。
实验
参数设置
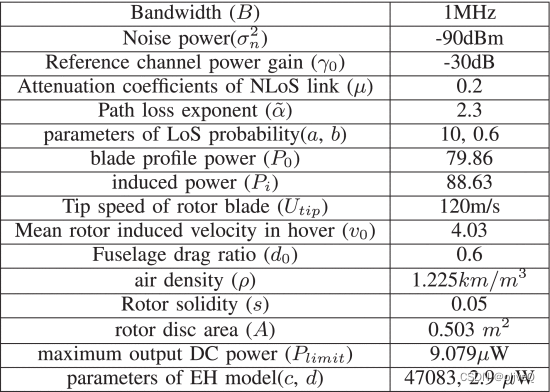
将 IoT 设备的数量设置为 100 个,任务周期设置为 10 分钟。物联网设备随机分布在一个 400 m × 400 m 范围的正方形区域内。在每项任务开始时,无人机在指定区域的随机位置开始执行任务。飞行高度为 10 m,最大飞行速度20米/秒,无人机的覆盖半径设置为Ddc=10 米和Deh=30 米。无人机发射功率设置为40dBm、物联网设备发射功率-20dBm,物联网设备的数据缓存每秒更新一次。他们对数据积累的泊松过程的期望是从集合 {4,8,15,20} 中随机分配的。数据缓冲区容量5000,传输数据大小Q设置为10Mb。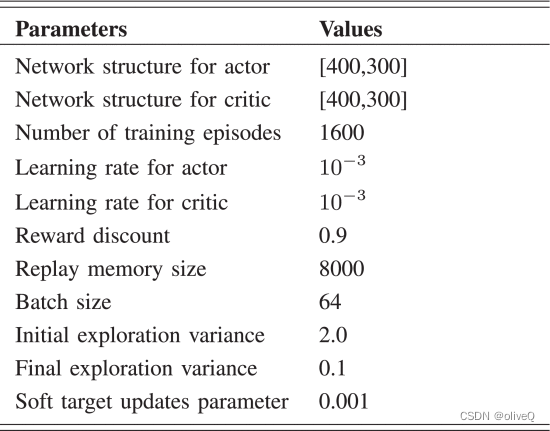
所有隐藏层都是完全连接的,并且使用 ReLU 函数进行激活。Actor 网络的最终输出层设置为 tahn 层来绑定动作。
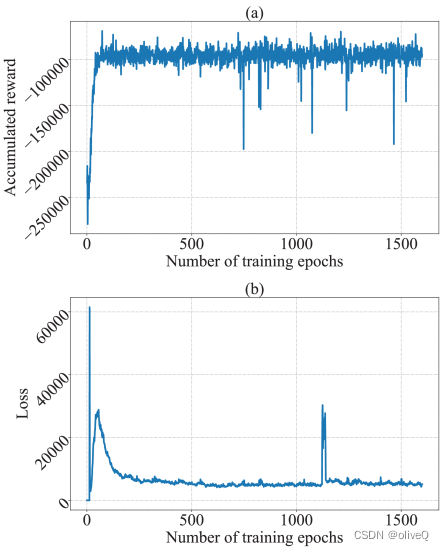
展示了所提出的MODDPG算法的有效性和收敛性
- 训练后的 MODDPG 代理的学习曲线((a)累积奖励;(b) 损失)
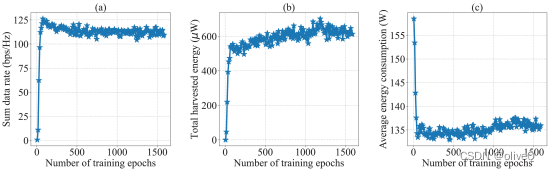
- 训练曲线跟踪优化目标( (a) 总数据率;(b) 收集的总能量;© 平均能源消耗)
我们可以看到在大约第 500 个 epoch 之前有一个主要的探索和学习阶段。在这个阶段,网络的损失在急剧上升后迅速下降。同一时期内,在降低能耗的同时,总数据速率和总收集能量迅速增加。 - 训练曲线跟踪优化结果((a)直流设备总数;(b) 平均数据速率;© EH 设备的平均数量;(d) 总 EH 率。)
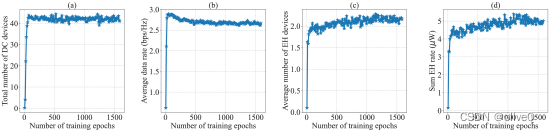
可以发现为了提高总数据率,无人机学会让更多的目标设备进入Ddc 激活数据收集。平均数据速率很快达到最大值。之后随着平均EH设备数和总EH率的增加缓慢下降,代表平均设备数落在Deh和悬停阶段所有EH设备的EH率之和。为了增加总收集能量,代理在总数据速率上做出让步。此外,critic network 的训练损失在大约 1100 个 epoch 出现急剧波动。之后,随着能源消耗的增加,总收集能量进一步提高。它揭示了智能体进一步调整其控制策略以找到所有目标之间的权衡。最后,随着损失函数的振荡收敛,所有优化目标基本稳定。这表明我们提出的算法可以针对 MOO 问题产生有效的无人机控制策略。
策略性能对比评估:最大速度悬停采集策略PVmax(实现总和吞吐量的最大化),最大续航速度悬停采集策略PVME(实现总能量的最小化)
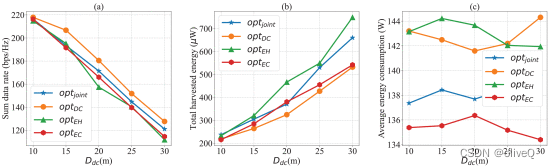
数据采集的覆盖半径Ddc设置为10 m、15 m、20 m、25 m和30 m。所有实验数据均为100个评价结果的平均值。
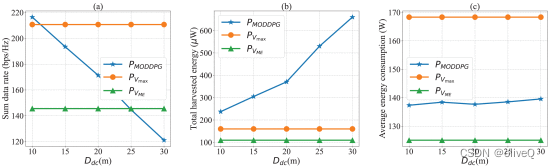
不同政策下的优化目标: (a) 总数据率;(b) 收集的总能量;© 平均能源消耗。
Ddc小于10m时的总数据率比其他两个都好
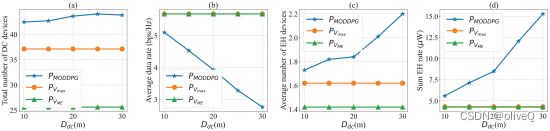
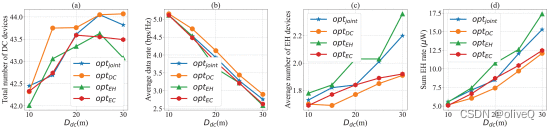
不同策略下的优化结果: (a) 直流设备总数;(b) 平均数据速率;© EH 设备的平均数量;(d) 总 EH 率。
平均 EH 设备数量和总 EH 率均随着DdC . 原因是增加DdC 增强了无人机控制决策的自由度。无人机可以更灵活地选择悬停位置DdC 增加。因此,它可以让更多的设备进入其能量传输覆盖范围,并缩短电力传输距离,以获得更高的物联网设备总收集能量。
不同策略下的优化结果: (a) 无人机轨迹;(b) 数据速率;© 总 EH 率
揭示了基于MODDPG算法的策略具有实现多目标协调优化的优势。

验证了最优策略是根据权重参数进行调整的
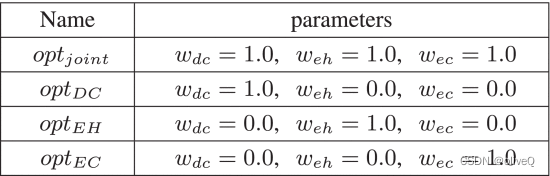
比较不同权重设置对最优策略的影响,分别将与总数据率、总收获能量和能耗相关的权重设置为 1.0,将其他两个目标的权重设置为 0.0。
增加Ddc 导致总数据速率降低和所有策略下总收集能量的提高。随着DC覆盖半径的增加,无人机与目标设备之间的距离也越来越大。一方面,它使无人机能够在一个任务中访问更多的设备。另一方面,它降低了传输数据速率。
此外,越来越多Ddc 提供更广泛的悬停位置选择范围。因此,更多的物联网设备可以从具有更好信道条件的无人机中获取能量。
不同权重参数下的优化目标: (a) 总数据率;(b) 收集的总能量;© 平均飞行能耗
无人机在不考虑总数据率的情况下做出飞行决策。
不同权重参数下的优化结果: (a) 直流设备总数;(b) 平均数据速率;© EH 设备的平均数量;(d) 总 EH 率
提出的 MODDPG 算法成功地学习了控制策略以同时优化多个优化目标。
分析了三种 SOO策略的比较结果
因为试图靠近目标设备可能会与在良好的信道增益下覆盖更多的 EH 设备发生冲突。由于该政策不考虑能耗,因此远高于其他策略。
总收集能量随着EH设备数量和总EH率的提高而提升。无人机不仅在悬停阶段学习覆盖更多的 EH 设备,它还悬停在具有更好通道增益的位置。
提出的算法能够在不同的偏好条件下产生最优策略。















 2604
2604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









