









简介
在上一篇文章中,我介绍了《使用Adaboost训练车牌定位》的前两个步骤:
1.准备训练样本图片,包括正例及反例样本
2.生成样本描述文件
3.训练样本
4.目标识别
=================
今天第3步:基于haar特征的adaboost级联分类器的训练。若将本步骤看做一个系统,则输入为正样本的描述文件(.vec)以及负样本的说明文件(.dat);输出为分类器配置参数文件(.xml)。
老规矩,先介绍一下这篇文章需要的工具,分别是(1)训练用的opencv_haartraining.exe,该程序封装了haar特征提取以及 adaboost分类器训练过程;(2)haarconv.exe(老版本命名法)或者convert_cascade.exe(新版本命名法)或者opencv_traincascade.exe,该程序 用于合并各级分类器成为最终的xml文件。一般这两个程序都能在opencv的工程文件里找到,请善用ctrl+F。若没有,则请到http://en.pudn.com/downloads204/sourcecode/graph/texture_mapping/detail958471_en.html 中 下载opencv_haartraining.exe以及相应dll库,到http://mail.pudn.com/downloads554 /sourcecode/graph/detail2285048.html 中下载haarconv.exe以及相应dll库。必备的dll库如下图所示,为了方便你可以将exe以及dll都拷贝出来。目录结构见附图

工具都准备好了,下面进入操作
1.训练分类器
打开cmd,cd到当前目录,运行命令:cd /d F:\objectmarker
opencv_haartraining.exe -data ./cascade -vec ./pos/sample_pos.vec -bg ./neg/sample_neg.dat -npos 2800 -nneg 14000 -mem 256 -mode ALL -featureType HARR -w 40 -h 20
或者
opencv_haartraining.exe -data ./cascade -vec ./pos/sample_pos.vec -bg ./neg/new_sample_neg.dat -npos 2800 -nneg 14000 -mem 256 -mode ALL -featureType HARR -w 40 -h 20
参数意义:
-data 指定生成的文件目录, 是训练生成的检测器存放的目录,你可以自己在工作目录下面建一个叫做cascade的目录,然后训练的时候就可以使用这个作为参数填进去
-vec vec文件名, 也就是前面说的sample_neg.vec文件
-bg 负样本描述文件名称,也就是负样本的说明文件(.dat)
-nstage 20 指定训练层数,推荐15~20,层数越高,耗时越长。
-nsplits 分裂子节点数目,选取默认值 2
-minhitrate 最小命中率,即训练目标准确度。这里的参数表示的是一个stage训练到什么程度就结束,然后开始训练下一个stage呢?标准就是在这个stage的正负样本中,检测率不能小于-minHitRate,虚警率不能高于-maxFalseAlarmRate。比如这里我们都采用默认值,-maxFalseAlarmRate为0.995,-maxFalseAlarmRate为0.5,表示的就是给出1000个正样本,至少分类器要将其中的995个样本判断为正样本,如果给出1000个负样本,最多只能将500个判断为正样本。
-maxfalsealarm最大虚警(误检率),每一层训练到这个值小于0.5时训练结束,进入下一层训练,

-npos 在每个阶段用来训练的正样本数目,训练的时候用到的正样本的个数 ,这个个数要比你实际拥有的正样本的个数少个100到200个,因为每一个stage的分类器会将少量正样本识别为负样本,因此需要新的正样本补充进来,也就是那100到200个,如果你这里填的-numPos参数是你实际拥有的也就是sample_pos.vec文件中包含的正样本个数,那么当需要补充正样本的时候你就没有新的正样本可以来补充了。我总共有3000个正样本,所以这里我可以填写2800作为训练时候的正样本数,留下200个正样本做替补队员。
-nneg在每个阶段用来训练的负样本数目 这个值可以设置大于真正的负样本图像数目,程序可以自动从负样本图像中切割出和正样本大小一致的,这个参数一半设置为正样本数目的1~3倍或者1~5倍,训练的时候用到的负样本个数,这个个数和你neg.txt(sample_neg.dat )中负样本大图片的个数没什么直接关系,举个栗子我这里填的是14000,那么程序会从neg.txt中的大图中按照某种规则抠出指定个数以及w=40和h=20的小图作为负样本,也就是说一张负样本大图可以产生数十上百个负样本小图,这些小图才是真正在训练的时候作为负样本出现的。一个经验的填法是-numNeg是-numPos的5倍左右。比例太低导致虚警高,太高了导致检测率低。正负比为1:5挺合适的。
-w -h样本尺寸,与前面对应 -mem 程序可使用的内存,这个设置为256即可,实际运行时根本就不怎么耗内存,以MB为单位
-featureType:是你可以选择的特征的种类,总共3种特征可以选择,harr,lbp以及hog。我训练过手掌和人头的检测器,实践表明,harr特征往往在adaboost中有着更好的表现,因此这里我填的是HARR,也就是默认值其实可以不填的。
-mode 指定haar特征的种类,BASIC仅仅使用垂直特征,ALL表示使用垂直以及45度旋转特征,这是选择了HARR特征之后所独有的一个参数,BASIC、CORE、ALL分别含有不同的特征,但三者是包含关系,也就是ALL包含了CORE中的特征,CORE包含了BASIC中的特征。具体内容可以参考博客,也可以看下图:
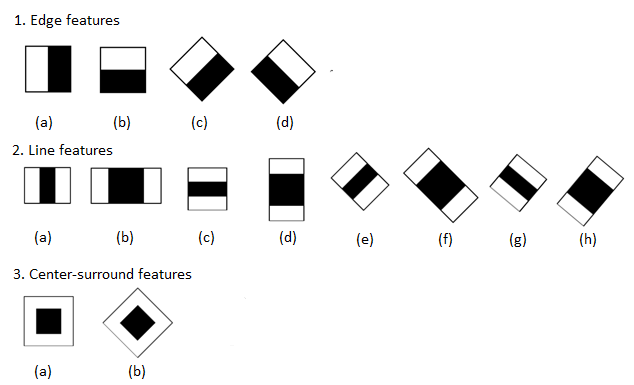
-sym或者-nonsym,后面不用跟其他参数,用于指定目标对象是否垂直对称,若你的对象是垂直对称的,比如脸,则垂直对称有利于提高训练速度
后来发现w、h是浮点型,修改sample_neg.dat文件程序:
'''
Created on 2017年10月7日
@author: XT
'''
with open("F:\\objectmarker\\neg\\sample_neg.dat",'r',encoding='utf-8') as f1,\
open("F:\\objectmarker\\neg\\new_sample_neg.dat",'w',encoding='utf-8')as f2:
total_sum = 0#用于计数
for line in f1:
str_line = line.split(" ")[:-2]
str_line.append('600')
str_line.append('400')
new_line = " ".join(str_line)
total_sum += int(str_line[1])
f2.write(new_line)
f2.write("\n")
print("count_pos_number:",total_sum)后来发现sample_neg.dat不需要写明位置坐标!!!
运行中……….

BACKGROUNG PROCESSING TIME 是负样本切割时间,一般会占用很长的时间
N 为训练层数
%SMP 样本占总样本个数
ST.THR 阈值,
HR 击中率,
FA 虚警,只有当每一层训练的FA低于你的命令中声明的maxfalsealarm数值才会进入下一层训练
EXP.ERR 经验错误率
训练过程好久,少则一天多则一周。换了一台电脑训练,下面是训练2天后的窗口


2.合并子分类器生成xml文件
输入命令:cd /d F:\objectmarker
haarconv.exe ./cascade haar_adaboost.xml 20 40
若你使用的是convert_cascade.exe则是另外一种格式:
convert_cascade.exe –size=”20x40” ..\cascade haar_adaboost.xml
若没有,则convert_cascade.c文件里写着:
"./convert_cascade --size=\"<width>x<height>\"<convertation size> \n"
" input_cascade_path \n"
" output_cascade_filename\n"convert_cascade.exe –size=40x20 ./cascade ./cascade/haarcascade_plate.xml


想知道用法可以输入xxx.exe usage,用法以及参数说明一目了然

convert_cascade.exe 在哪里找?
我在opencv的库里没有找到这个程序,于是在网上找到了源码,自己编译运行得到了exe程序, 源码如下,建一个工程并配置好opencv,把代码粘进工程运行即可。或者下载我编译好的: http://download.csdn.net/download/u010603823/9631703 (没有币可以留言或私信邮箱,我给你发)。
**转至使用opencv_haartraining.exe做样本训练死循环无法生成.xml文件的解决办法–convert_cascade.exe - 小罐的博客 - CSDN博客
http://blog.csdn.net/u010603823/article/details/52557760**
如有错误欢迎批评指正
#include "opencv2/objdetect/objdetect.hpp"
#include "opencv2/highgui/highgui.hpp"
#include <ctype.h>
#include <stdio.h>
void help()
{
printf("\n This sample demonstrates cascade's convertation \n"
"Usage:\n"
"./convert_cascade --size=\"<width>x<height>\"<convertation size> \n"
" input_cascade_path \n"
" output_cascade_filename\n"
"Example: \n"
"./convert_cascade --size=640x480 ../../opencv/data/haarcascades/haarcascade_eye.xml ../../opencv/data/haarcascades/test_cascade.xml \n"
);
}
int main( int argc, char** argv )
{
const char* size_opt = "--size=";
char comment[1024];
CvHaarClassifierCascade* cascade = 0;
CvSize size;
help();
if( argc != 4 || strncmp( argv[1], size_opt, strlen(size_opt) ) != 0 )
{
help();
return -1;
}
sscanf( argv[1], "--size=%ux%u", &size.width, &size.height );
cascade = cvLoadHaarClassifierCascade( argv[2], size );
if( !cascade )
{
fprintf( stderr, "Input cascade could not be found/opened\n" );
return -1;
}
sprintf( comment, "Automatically converted from %s, window size = %dx%d", argv[2], size.width, size.height );
cvSave( argv[3], cascade, 0, comment, cvAttrList(0,0) );
return 0;
}
#ifdef _EiC
main(1,"facedetect.c");
#endif3.总结以及注意事项
真正做起来会有各种各样的错误发生让你措手不及。以下是问题及分析:
1)训练时间非常久,少则秒钟,多则几天甚至一礼拜。具体的时间跟你样本的选取、样本数量、机器的性能有着直接联系。举个例子,有人正样本7097负样本2830,在8核3.2Ghz的机器上,开启了多核并行加速(MP)的情况下训练了一周时间,跑到19层。链接http://blog.csdn.net/liulina603/article/details/8197889 。这个真心有点久了,有点夸张。举这个例子是想跟你说明,这是一件耗时间的事情,所以请你耐心等待。
2)卡死在某一层,好像进入死循环。这种情况一般跟样本的选择有关,尤其是负样本。当剩下所有的negtive样本在临时的cascade Classifier中evaluate的结果都是0(也就是拒绝了),随机取样本的数目到几百万都是找不到误检测的neg样本了,因而没法跳出循环!
解决方法是,增大负样本数目,增大负样本之间的变化!
3)训练带某一层出错,报错提示下图。查看cascade目录下发现确实走到第5层。这种情况跟上一种情况其实有点类似,都是opencv_haartraining.exe无法正常terminate。而我们的关注点在于,所生成的这些子分类器能用吗?要依实际情况而定。拿下图来说,在第5层的时候FA已经很低了,0.125000,说明效果已经够用。2)中也是这个道理。

4)到后面训练一个stage会比前面的stage训练时间要长,我训练1000个正样本和5000个负样本在i7的笔记本上花了将近20个小时,所以看到训练程序没有反应的时候不要担心,其实是在训练的,如果程序因为某些原因比如负样本不够而停止训练的话,程序会自己输出提示信息的。我也没有遇到过卡住了不继续训练的情况。另外,如果程序在训练过程中被人为终止了,可以再次输入上面的指令,会接着上次训练的结果继续训练的。比如上次训练了6个stage,那么这次再训练的话会从第7个stage开始的,只要不去改变cascade目录下的文件就行了。最后,祝大家都能训练出效果好的检测器吧。
参考
【1】【原】训练自己haar-like特征分类器并识别物体(1) - 编程小翁 - 博客园
http://www.cnblogs.com/wengzilin/p/3845271.html
【2】训练自己haar-like特征分类器并识别物体(2) - 罗索实验室
http://www.rosoo.net/a/201504/17273.html
【3】如何利用OpenCV自带的haar training程序训练分类器 - 计算机视觉小菜鸟的专栏 - CSDN博客
http://blog.csdn.net/carson2005/article/details/8171571
【4】使用Adaboost训练手掌检测器 - xbcReal的博客 - CSDN博客
http://blog.csdn.net/xbcreal/article/details/77994719
【5】Haar+cascade训练说明手册_百度文库
https://wenku.baidu.com/view/65714b4da0116c175e0e4869.html
【6】OpenCV训练分类器制作xml文档-博客-云栖社区-阿里云
https://yq.aliyun.com/articles/9316?spm=5176.100239.blogcont9317.7.Yk8EnH
















 6988
6988











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











