







1、正则表达式findall函数
python中re模块提供了正则表达式相关操作
1.1 二元字符: . ^ $ * + ? {} [] | () \
. 匹配除换行符以外的任意字符
#print(re.findall("al.x","sdasdalsxdds"))
^ 匹配字符串的开始
#print(re.findall("^al.x","alexsdasdalsxdds"))
$ 匹配字符串的结束
#print(re.findall("al.x$","alexsdsasdalsxddsalex"))
[] 匹配里面的一个,或的关系
print(re.findall("al[abc]x","dsasdalxddsalbx"))
[] 匹配里面的一个,使用范围
print(re.findall("al[a-z]x","dsasdalxddsalfx"))以上中的*、$在中括号[]里不再有意义,除了以下三个:
1)”-“表示范围;
2)“^”不表示起始位置匹配,表示否的意思,非;
3)“\d”表示匹配数字,如s[\d]d,s3d;
1.2 反斜杠跟元字符,用来去除特殊功能:
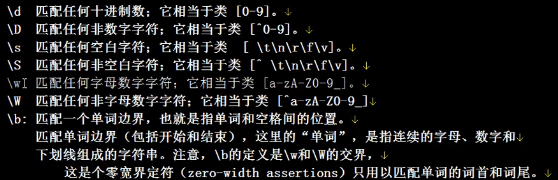
\w 匹配字母或数字或下划线或汉字
print(re.findall("a\wx","a_x"))
\s 匹配任意的空白符
\b 匹配单词(单词的开始或结束)
import re
p=re.compile(r'I\b')
a=p.finditer("I Have I gotten A plus glat get I")
for item in a:
print("{}-->{}".format(item.group(),item.span()))结果:I–>(0, 1) I–>(7, 8) I–>(32, 33)
\d 匹配数字
import re
p=re.compile(r'\d')
a=p.findall("11I32 44ave gotten A plus glat get")
print(a)结果:[‘1’, ‘1’, ‘3’, ‘2’, ‘4’, ‘4’]
p=re.compile(r'\d+')
结果:[‘11’, ‘32’, ‘44’]
1.3 次数
* 重复零次或更多次
print(re.findall("al.*x$","dsasdalsxddsalsssex")) + 重复一次或更多次
print(re.findall("al.+x$","dsasdalsxddsalsssex")) ? 重复零次或一次
print(re.findall("al.?x","dsasdalsxddsalx")){n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
print(re.findall("al.{0,5}x","dsasdalsxddsalx"))1.4 匹配单词
使用/b,需要加原生态字符,‘r’:
print(re.findall(r"I\b","I am a handsome Ice cream!"))#r表示原生字符
匹配的不光是空白的间隔,还有特殊的符号“¥&”等:
print(re.findall(r"I\b","I$¥#¥$ am a handsome Ice cream!"))#r表示原生字符
2、match函数
只在开头匹配,匹配成功会返回object,使用object.span查看位置,object.group()查看内容。
import re
a=re.match('I','I am a handsome Ice cream!')#匹配开头
print(a.span())#拿取位置3、search函数
只拿取第一个位置的信息
import re
a=re.search('I','aaaI am a handsome Ice cream!')#匹配第一次出现的位置
print(a.span())#拿取位置4、finditer函数
比findall多了一个可迭代的对象,
import re
p=re.compile('dd')
iterator=p.finditer("addssddssssdssawf")
for match in iterator:
print("{}--->{}".format(match.group(),match.span()))结果:
dd—>(1, 3)
dd—>(5, 7)
5、sub函数
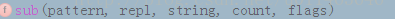
查找替换功能:
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
a=re.sub("g.{0,2}t","Go","I have gotten A plus glat get")
print(a)
结果:I have Goen A plus Go Go
a=re.sub("g.{0,2}t","Go","I have gotten A plus glat get",count=2)#加个最大替换次数
结果:I have Goen A plus Go get
6、subn函数
用于计算替换次数:
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
a=re.subn("g.{0,2}t","Go","I have gotten A plus glat get")#加个最大替换次数
print(a)
结果:(‘I have Goen A plus Go Go’, 3)
7、split函数
a=re.split(r'\d',"I 1Have 2I 3gotten A plus glat get I")
print(a)等价于下面的compile函数格式:
import re
p=re.compile(r'\d')
a=p.split("I 1Have 2I 3gotten A plus glat get I")
print(a)结果:[‘I ‘, ‘Have ‘, ‘I ‘, ‘gotten A plus glat get I’]
8、compile格式,查找邮箱

#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
p=re.compile(r'\w+@\w+[.]com')
a=p.finditer("ss12@3#.com dwkldjke%.com "
"1111@qq.com sjdfa2017@163.com "
"djiwdjwu28hd@yahoo.com ddj22@singlang.com "
"kh2ss223@as,com e22d@$%@sddmo.com")
for item in a:
print(item.group())
结果:
1111@qq.com
sjdfa2017@163.com
djiwdjwu28hd@yahoo.com
ddj22@singlang.com
9、flag标志位

没有re.S时:
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
p=re.compile('f.?')
a=p.findall("dsf\n"
"enfdddfe")
print(a)
结果:[‘f’, ‘fd’, ‘fe’]
有re.S:
p=re.compile('f.?',re.S)
结果:[‘f\n’, ‘fd’, ‘fe’]
10、匹配斜杆
方法1:
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
p=re.compile('\\\\men')
a=p.finditer("dsf\menfdddfe")
print(a)
for item in a:
print("{0}-->{1}".format(item.group(),item.span()))方法2:
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
p=re.compile(r'\\men')
a=p.finditer("dsf\menfdddfe")
print(a)
for item in a:
print("{0}-->{1}".format(item.group(),item.span()))结果:
<callable_iterator object at 0x0000000000DBCCC0>
\men-->(3, 7)
11、r读取原生字符,取消斜杆作用,匹配单词
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
p=re.compile(r'\bblow')#开头
a=p.finditer("dsf blow ddblow dblow blownfdddfe")
print(a)
for item in a:
print("{0}-->{1}".format(item.group(),item.span()))结果:
<callable_iterator object at 0x0000000000DCCCC0>
blow-->(4, 8)
blow-->(22, 26)
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
p=re.compile(r'blow\b')#结尾
a=p.finditer("dsf blow ddblow dblow blownfdddfe")
print(a)
for item in a:
print("{0}-->{1}".format(item.group(),item.span()))
结果:
<callable_iterator object at 0x0000000000B65048>
blow-->(4, 8)
blow-->(11, 15)
blow-->(17, 21)
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
p=re.compile(r'\bblow\b')#开头和结尾
a=p.finditer("dsf blow ddblow dblow blownfdddfe")
print(a)
for item in a:
print("{0}-->{1}".format(item.group(),item.span()))结果:
<callable_iterator object at 0x0000000000DCDC50>
blow-->(4, 8)
12、分组
去已经提取到的数据,再提取数据。没有使用分组时:
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
str ="has sdhjahhdlahd"
r=re.match("h\w+",str)#
print(r.group())#获取匹配到的所有结果
print(r.groups())#获取模型中匹配到的分组结果
print(r.groupdict())结果:
has
()
{}
使用分组后:
__author__ = 'Alex_XT'
import re
str ="has sd hja hhdlahd"
r=re.match("h(\w+)",str)#分组
print(r.group())#获取匹配到的所有结果
print(r.groups())#获取模型中匹配到的分组结果
print(r.groupdict())
结果:
has
(‘as’,)
{}
给组命名:
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
str ="has sd hja hhdlahd"
r=re.match("h(?P<key>\w+)",str)#分组
print(r.group())#获取匹配到的所有结果
print(r.groups())#获取模型中匹配到的分组结果
print(r.groupdict())
结果:
has
(‘as’,)
{‘key’: ‘as’}
13、findall分组
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
str ="hasaabc sd halaabc hhdlahd"
r=re.findall("h(\w+)aabc",str)#分组
print(r)
结果:[‘as’, ‘al’]
进一步分组:
匹配到的再加上匹配分组结果;
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
str ="hasaabc sd halaabc hhdlahd"
r=re.findall("h(\w+)a(ab)c",str)#分组
print(r)
结果:[(‘as’, ‘ab’), (‘al’, ‘ab’)]
14、split分组
无分组时:
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
str ="hasaabc sd halaasdbc sd hhdlahd"
r=re.split("sd",str,1)#1表示分割次数
print(r)
结果:[‘hasaabc ‘, ’ halaasdbc sd hhdlahd’]
有分组时,包含分割词:
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
str ="hasaabc sd halaasdbc sd hhdlahd"
r=re.split("(sd)",str,1)
print(r)
结果:[‘hasaabc ‘, ‘sd’, ’ halaasdbc sd hhdlahd’]
有分组时,进一步分割词:
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
str ="hasaabc sd halaasdbc sd hhdlahd"
r=re.split("s(d)",str,1)
print(r)
结果:[‘hasaabc ‘, ‘d’, ’ halaasdbc sd hhdlahd’]
有分组时,进一步双重分割词:
#_*_coding:utf-8_*_
__author__ = 'Alex_XT'
import re
str ="hasaabc sd halaasdbc sd hhdlahd"
r=re.split("(s(d))",str,1)
print(r)
结果:[‘hasaabc ‘, ‘sd’, ‘d’, ’ halaasdbc sd hhdlahd’]
参考
【1】Python开发【第六篇】:模块 - 武沛齐 - 博客园
http://www.cnblogs.com/wupeiqi/articles/5501365.html
















 7044
7044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











