







一、为什么要万卡训练集群:
大语言模型贼牛逼这个就不强调了哈,机器翻译,人机会话表现出巨大潜力和应用价值。模型大小和训练数据大小决定了模型能力,为实现最先进的模型,人们已经致力于万亿tokens训练具有万亿参数的大型模型。这就需要建立具有数万个GPU的大规模人工智能集群来训练LLM(大语言模型)。
二、万卡训练集群的挑战:
1、实现大规模高训练效率;(能不能把万卡的算力有效利用起来)
2、实现大规模高稳定性训练;(卡太多每个都可能故障,很容易出现各种故障)
视频教程
1.1 大规模/万卡集群训练平台MegaScale的挑战、设计原则、考虑因素、出现原因MegaScale: Scaling Large Language_哔哩哔哩_bilibili
1.2 大语言模型LLM训练优化,并行注意力、滑动窗口、增加batchsize单次训练数据量,万卡加速训练MegaScale Scaling Large_哔哩哔哩_bilibili
1.3 万卡分布式训练,ZeRO数据并行优化 通信与数据加载并行_哔哩哔哩_bilibili
1.5 万卡训练 张量并行优化 数据切片计算通信并行 大规模集群_哔哩哔哩_bilibili
1.6 大规模训练数据加载优化,消除多余加载器,数据加载通信并行,万卡集群MegaScale_哔哩哔哩_bilibili
1.7 大规模集群训练、通信初始化优化、网络拓扑_哔哩哔哩_bilibili
1.8 大规模集群网络拥塞控制 ECMP PFC DCQCN NCCL通信超时重传_哔哩哔哩_bilibili
1.9 底层算子融合为什么能加速计算_哔哩哔哩_bilibili
1.10 万卡集群集群容错性能监控 心跳检测 自行诊断 故障恢复_哔哩哔哩_bilibili
视频教程还在持续更新中
三、万卡训练集群设计原则:
1、算法-系统协同设计
2、减少通信量/时间,通信和计算重叠
3、不降低精度情况下,优化计算过程
4、深度可观测性
万卡训练集群设计需考虑因素:
1、算法
2、分布式并行方案
3、数据加载
4、网络与通信
5、底层算子
6、集群容错与性能监测
4.1 LLM算法优化
在不影响模型精度的情况下进行算法优化,以实现大规模的高训练效率。
4.1.1 并行注意力机制( parallel attention)

如上面公式(1)所示,Attention算完的结果作为LN输入,LN才算。LN算完之后作为MLP输入,MLP才算,这是一个串行的计算过程,
改进为公式(2),LN算完之后,MLP和Attention可以并行的算。因此,并行注意力可以减少计算时间。
视频教程:1.2 大语言模型LLM训练优化,并行注意力、滑动窗口、增加batchsize单次训练数据量,万卡加速训练MegaScale Scaling Large_哔哩哔哩_bilibili
4.1.2 滑动窗口注意力机制(Sliding window attention (SWA))
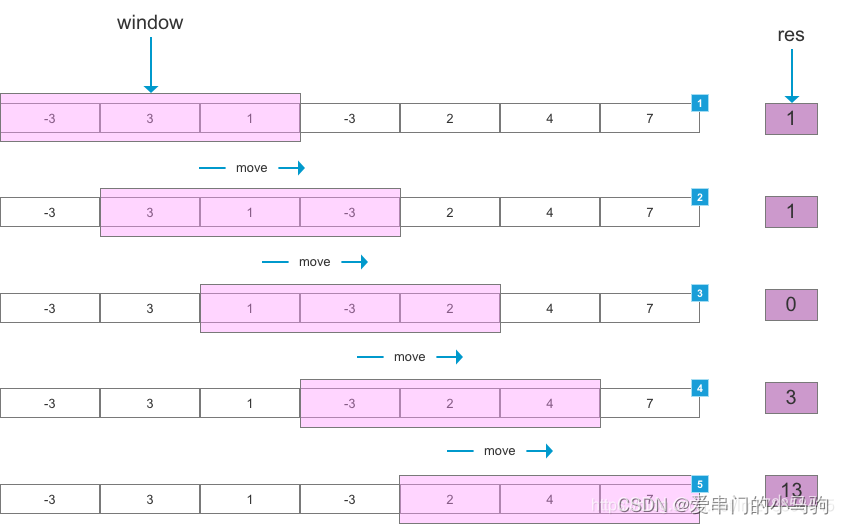
由于一句话是一个时间序列,我们在根据已有序列预测下一个字时,越靠前的字与我要预测字的相关性越弱。我们可以设置一个窗口,窗口之前的单词我们就忽略不计算了,减少计算量。每预测出一个单词,窗口就往回移动一格,预测下一个,所以叫滑动窗口。
就比如说,“爱串门的小”,我们预测下一个字,我们可以直接利用整个序列“爱串门的小”预测出“马”字。我们用“爱”一个字就预测不出“马”,距离太远,相关性太弱。我们可以设置长度为4当窗口,用“串门的小”就预测出“马”字了,忽略“爱”,减少计算量。但我们把“马”字预测出来了,预测下一个字时,我们把“爱”和“串”字都忽略,直接用“门的小马”预测下一个字,这里窗口是不是就往后滑动一格,忽略了“串”字。所以叫滑动窗口。
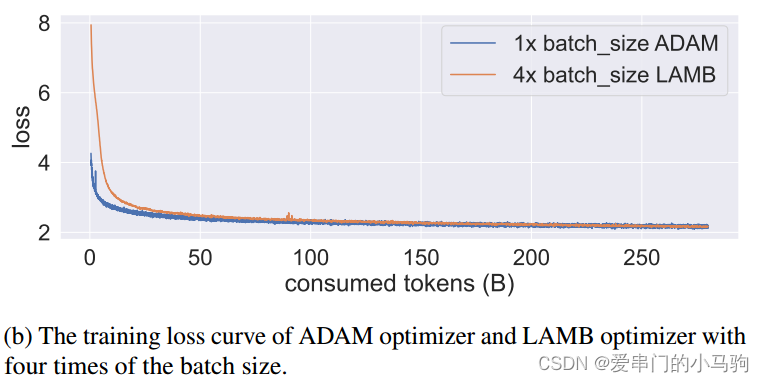
4.1.3 LAMB优化器
大规模训练受到批量大小限制。特别是,增加批量可能会影响模型收敛。LAMB可以将批量大小扩展到4倍,而不会损失准确性。为什么增大一批次训练数据量会减少训练时间,哈哈哈,爱串门的小马驹,贴心的给大家画了个图(怎么这么贴心,不点赞说不过去了啊),如下图所示,训练同样的数据耗时:
4.2 分布式训练方案
4.2.1 数据并行通信重叠
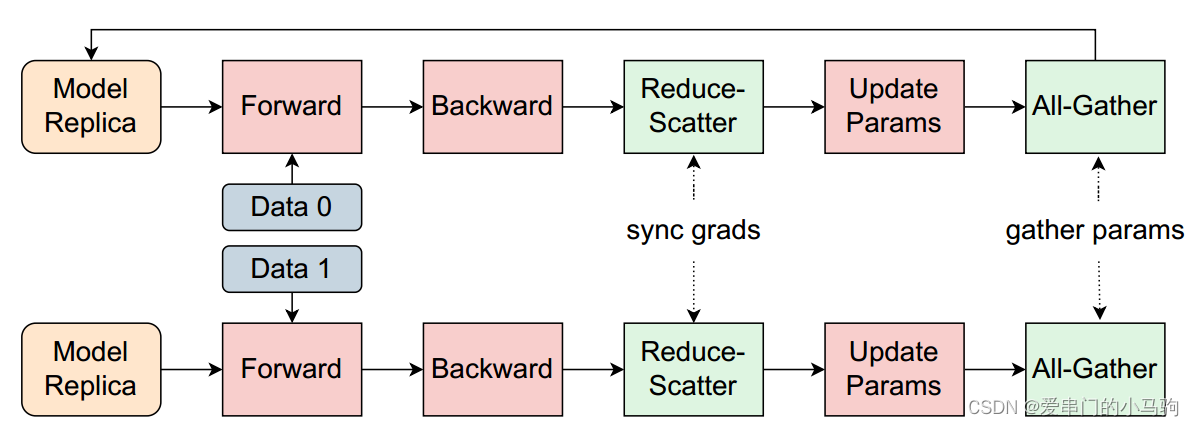
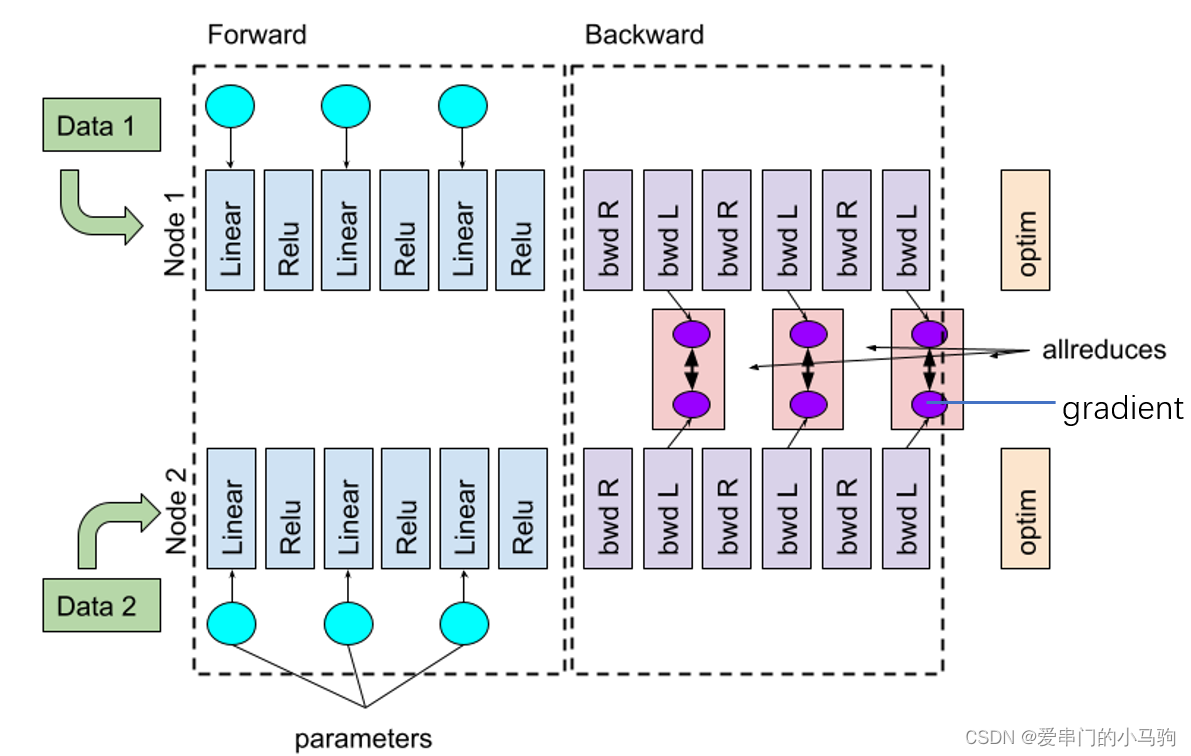
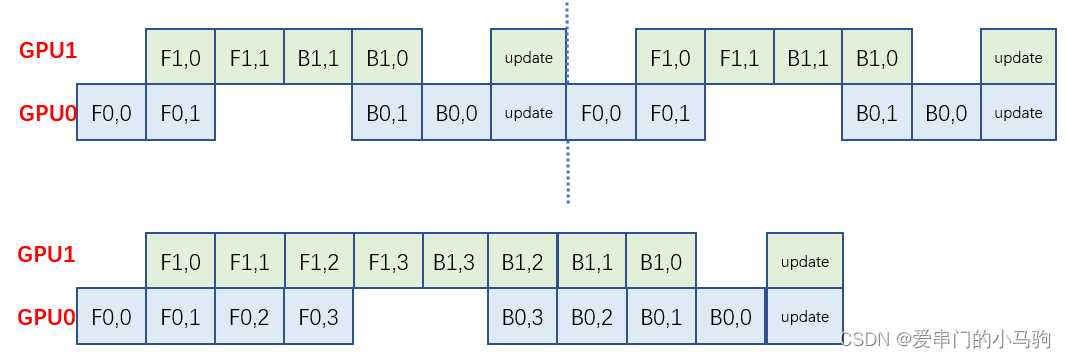
其实向Pytorch的DDP和FSDP已经做了训练与通信重叠,如上面的图所示,比如后向计算过程中,计算完一部分就通信Reduce-Scatter通信,这样,后续的后向计算过程中,同时进行通信,计算通信就重叠了。
但这样存在问题,就是我后向计算完成之后,还会进行一次Reduce-Scatter通信,前向计算开始之前,至少需要进行一次Allgather操作,才能进行进行计算,这两次通信时,计算通信是没有重叠的。
因此可以在这两次通信过程中,预加载数据,来让通信与数据加载重叠。
视频教程:1.3 万卡分布式训练,ZeRO数据并行优化 通信与数据加载并行_哔哩哔哩_bilibili
4.2.2 流水线并行通信重叠
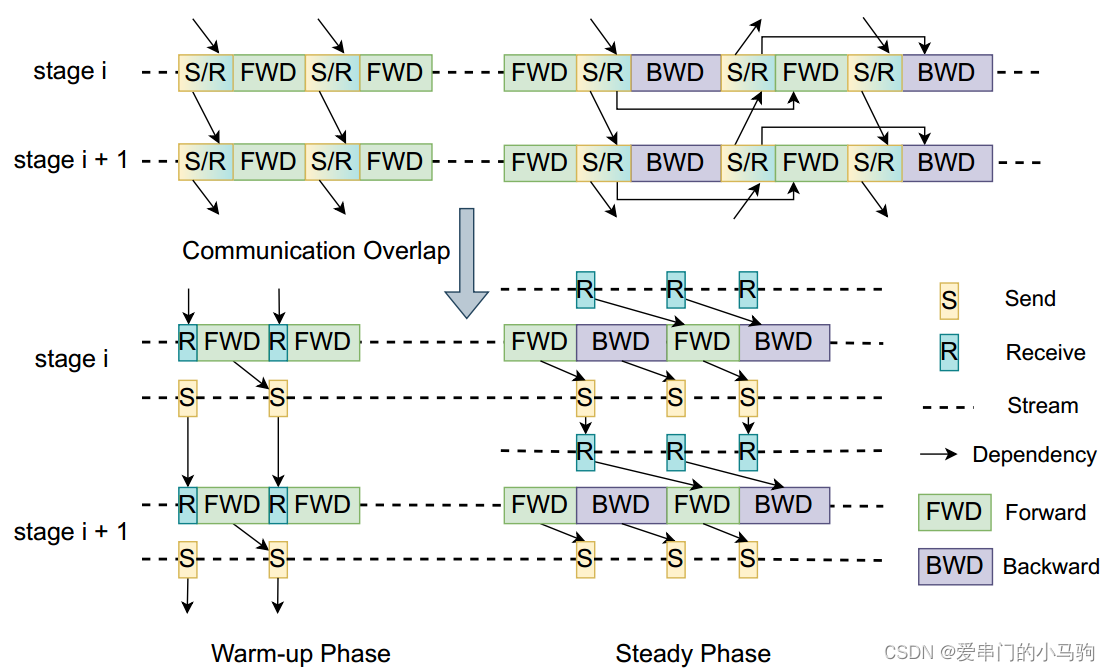
前向流水并行时,当一个GPU计算完发送数据给下个GPU当同时,就进行下一次计算。发送数据就和前向计算重叠了,即。
哈哈哈,反向时是不是也可以用同样当技术啊,发送数据时就进行下一次反向计算。我看有的博文说,这里是将recv和backward,个人感觉不是啊,只有收到数据后才能进行计算,这里还是send和backward重叠。(哈哈哈,同学们要对自己有信心,要勇于挑战专家,错了就错了及时纠正就好。哈哈哈,如果是我爱串门的小马驹错了,大不了发视频道歉,承认自己菜)
由于前向和反向计算相对独立,是不是可以让前向的recv接收和backwark反向计算重叠,后向计算的recv和前向计算过程重叠。这里不就是,recv和计算重叠了么。
4.2.3 张量并行通信重叠
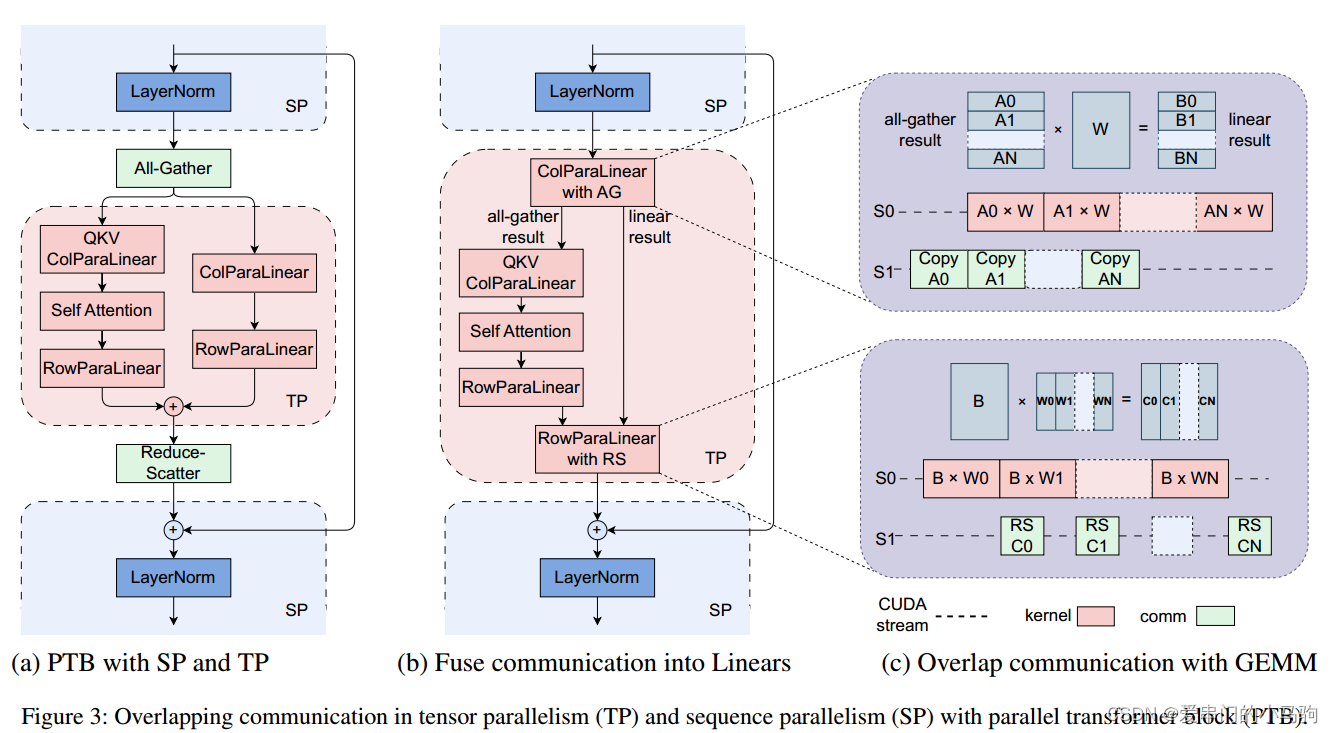
这里的核心就是张量并行时,对数据进行分片:(1)对于allgather通信部分,allgather第一个数据片就进行计算,这样后续计算就和通信并行起来;(2)对于Reduce-Scatter通信部分,计算完第一个部分就进行Reduce-Scatter通信,这样后续计算就和通信并行起来了。
视频教程:1.5 万卡训练 张量并行优化 数据切片计算通信并行 大规模集群_哔哩哔哩_bilibili
4.3 数据预处理和加载优化
4.3.1 异步数据预处理
异步数据预处理,训练完成通信同步梯度时,就开始数据预处理/加载。
4.3.2 消除冗余数据加载器
每个GPU都有自己的数据加载器,将数据先读到CPU内存。同一张量并行组,他们输入相同,因此将数据加载到CPU内存只需一个数据加载器,然后各个GPU加载数据到自己显存。
视频教程:1.6 大规模训练数据加载优化,消除多余加载器,数据加载通信并行,万卡集群MegaScale_哔哩哔哩_bilibili
4.4 通信初始化优化
集合通信组初始化,随着集群规模增大,耗时便的无法忽略,影响调参和调试。
(1)同步步骤中使用当阻塞是基于Pytorch内部实现的TCPStore,它单线程、阻塞读写方式运行。 将TCPStore替换为Redis,它是非阻塞异步的。
(2)减少非必要当全局barrier阻塞同步。
4.5 集群
4.5.1 集群拓扑
三层交换机以类似 CLOS 的拓扑结构连接,两层就是spine-leaf如图所示,三层如下图所示。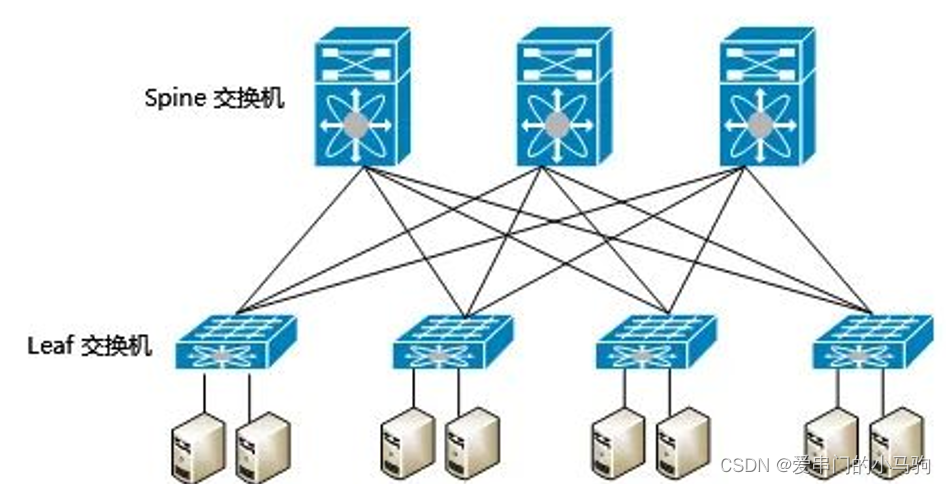
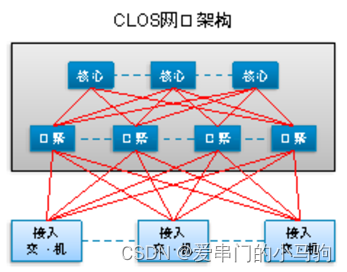
4.5.2 减少 ECMP 哈希冲突
ECMP(Equal-Cost Multi-Path routing)等价多路径负载均衡。就是比如现在有两条路径都可以到达,ECMP根据IP、端口号等计算一个哈希值(这个我们NCCL源码解读1里面有讲到)。
通过计算哈希值,确定走哪条路径。由于IP、端口号等完全一致,计算出的哈希值也一页,可以保证同一会话始终走同一路径,防止会话中断。
如何减少ECMP 哈希冲突,这玩意真不了解,后面有时间再调研调研。
4.5.3 拥塞控制
IB(Infiniband)不是贼贵么,而且还是私有协议,但确定快。以太网就参考它,搞了RoCE v2,参考IB继承了IB无损网络的约束,所有提出PFC(Priority-based Flow Control)。PFC当交换机缓存快溢出的时候,直接就通知上游端口,粗暴的暂停任何数据发送。
DCQCN(Data Center Quantized Congestion Notification)就出生,DCQCN涉及三个东西,发送方网卡,交换机,接收方网卡。
1、交换机缓存不够了,按拥塞程度以概率给要转发的数据包打上标记,表示交换机快不行了。
2、接收网卡收到带标记的数据包,知道交换机快不行了,发送数据包给发送方网卡。
3、接收网卡收到交换机快不行的数据包,根据概率,减缓发送。一段时间没收到交换机快不行的包,开始提速。
4.5.4 超时重传设置
NCCL中的参数可以设置控制重传定时器和重试计数,NIC网卡自适应重传使能。
4.6 底层算子
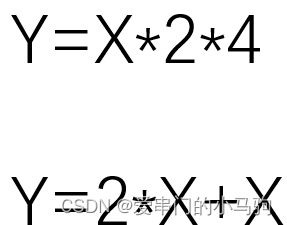
算子融合,优化计算过程。就比如说,上面的第一个计算,原本X是要进行两次乘法得到Y,先乘以2再乘以4,算子融合,X乘以8一次搞定,减少计算量。
算子融合不仅可以优化计算计算过程,有时也可以优化读写过程。比如上面的第二个计算,第一次读取X乘以2得到结果,再读取X加上结果得到Y,融合后只读取一次X就搞定了。
4.5 集群容错
1.10 万卡集群集群容错性能监控 心跳检测 自行诊断 故障恢复_哔哩哔哩_bilibili
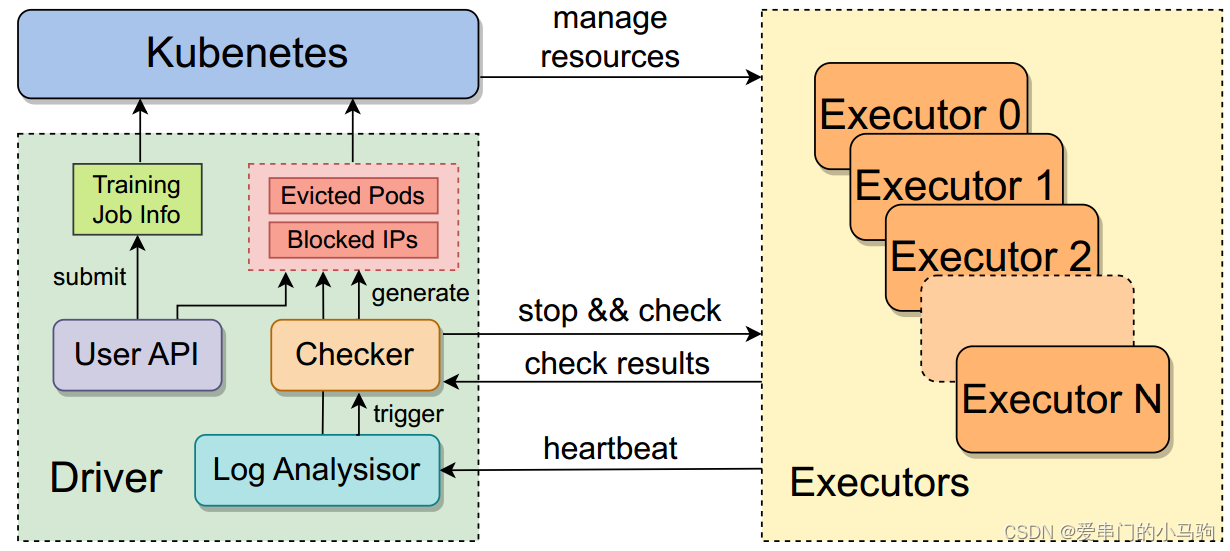
4.5.1 心跳检测
心跳消息监测异常,发现异常发出早期警告。
毫秒级监测:IP地址、Pod名称、硬件信息、训练状态、RDMA流量发现错误或者流量异常立即警报。
4.5.2 自行诊断
轻量级软硬件故障诊断,快速自动定位问题。
主机内网测试:(1)RDMA网卡到主机内端点(内存节点和GPU)带宽测试。
(2)同一主机上不同RDMA网卡之间的连接和带宽测试。
NCCL测试: (1)服务器内GPU之间alltoall测试。
(2)同一交换机下服务器allreduce测试
注:用Allreduce也可以测不同底层通信算子,reduce类通信和alltoall等非reduce类底层通信算子和协议不同。
4.5.3 故障恢复
双阶段checkpoint快速保存和调用
两阶段快速Checkpoint保存:第一阶段Checkpoint写入主机内存;
第二阶段模型训练同时, Checkpoint由内存写入HDFS。
两阶段快速Checkpoint调用:第一阶段单个GPU从HDFS读取Checkpoint;
第二阶段,广播给所有其它所有需相同数据的GPU。
4.5.4 性能监控可视化
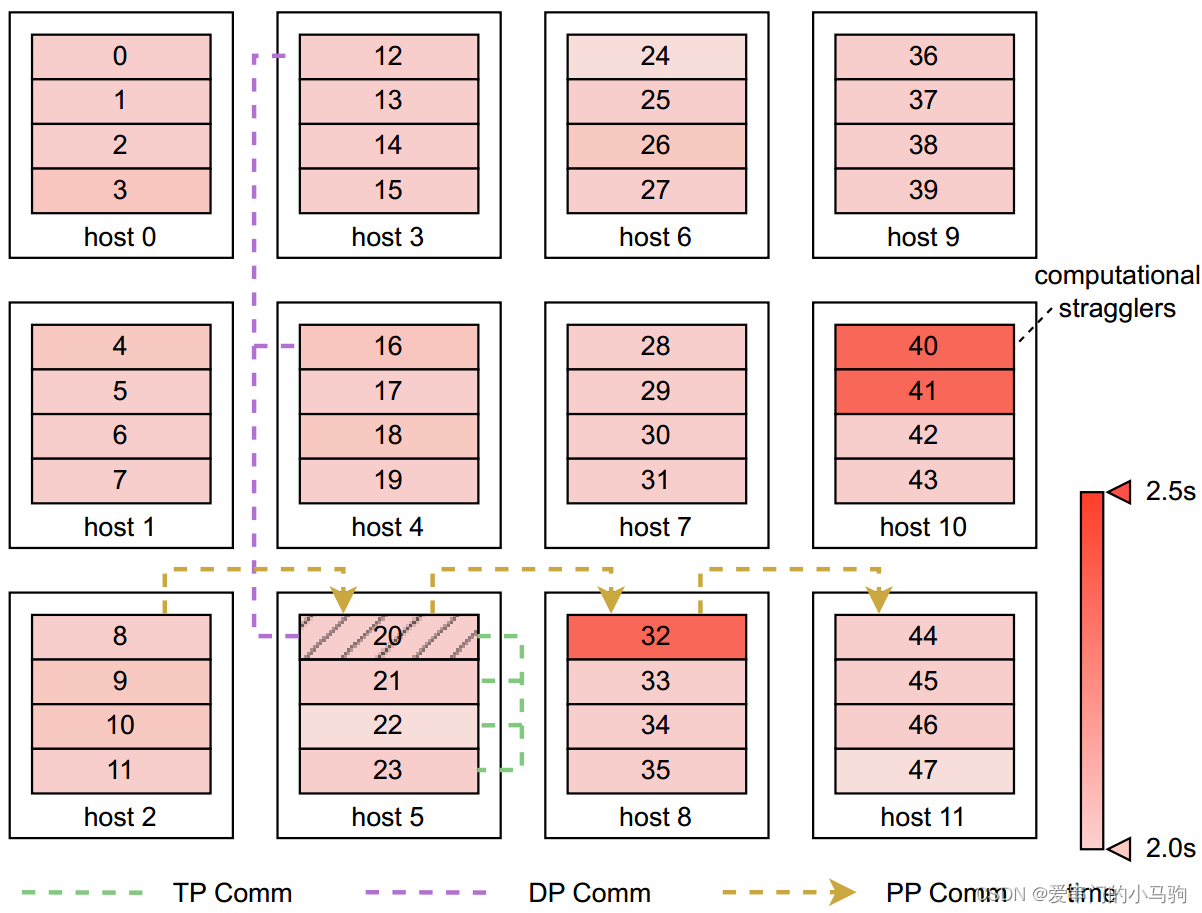
性能监控需注意GPU与GPU的依赖关系,不是直接通过GPU运行的快慢来确定GPU的性能。当GPUA的输入是GPUB给的时候,可能是GPUA自己慢自己性能差,也可能是GPUB慢导致GPUA看起来运行慢。

结论:
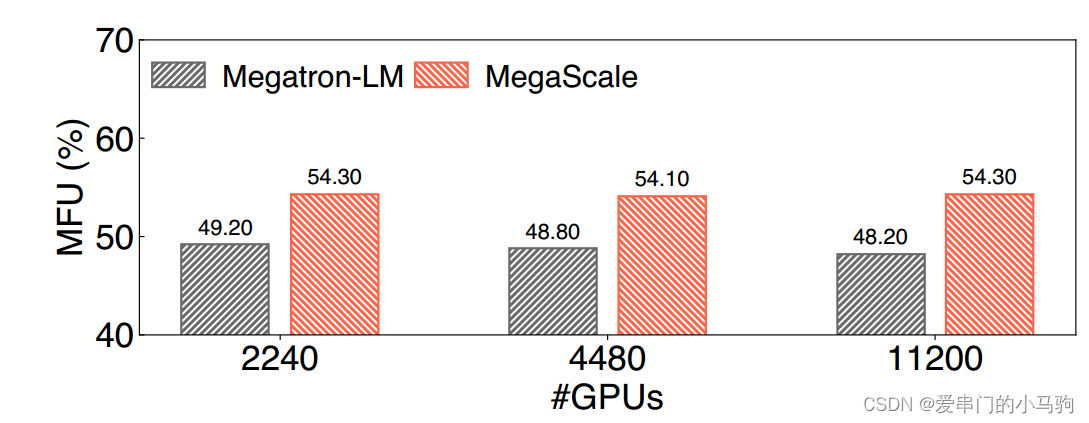
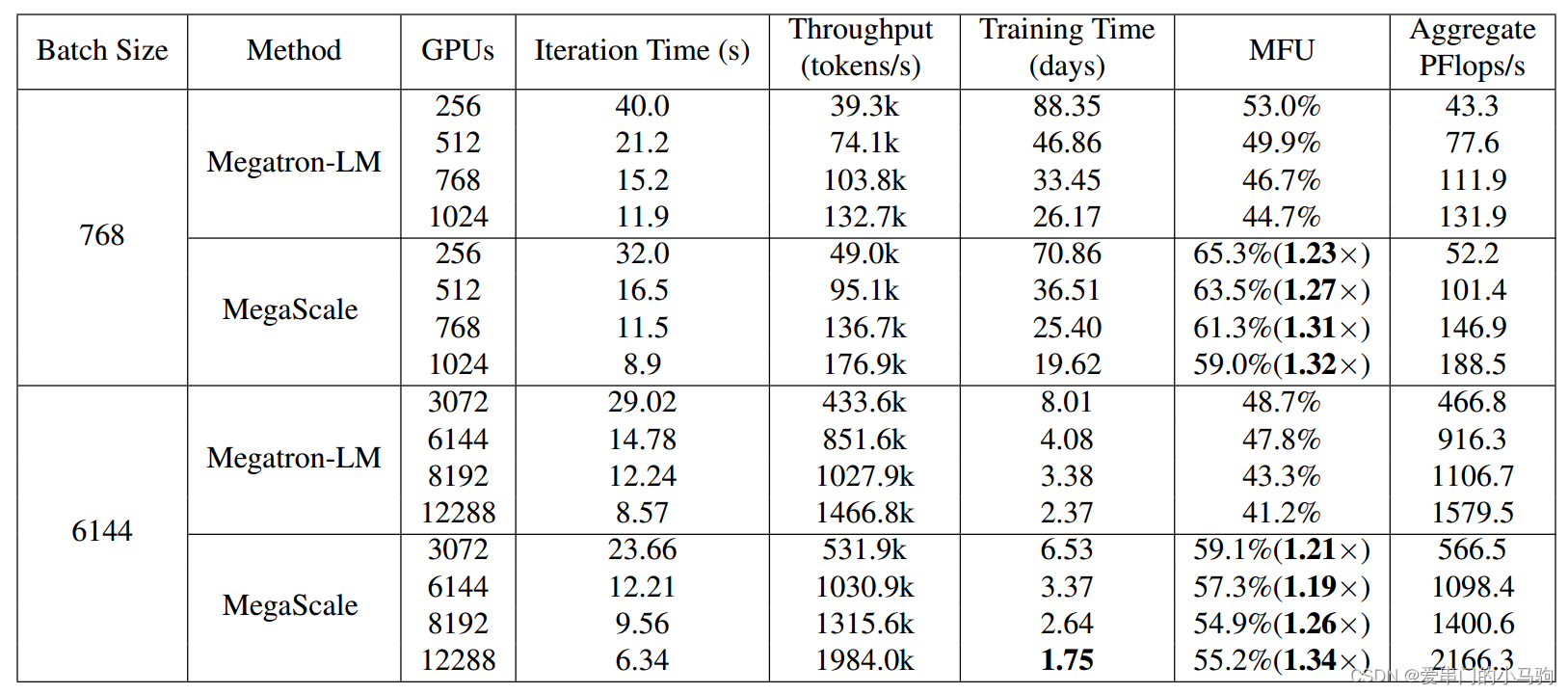
在模型训练精度不变的情况下,实现了55.2%的算力利用率Model FLOPs Utilization (MFU),与最先进的开源训练框架Megatron LM相比,提升了1.34倍。
参考文献:
[2402.15627] MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs (arxiv.org)


















 1622
1622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









