







0、前言
尽管数据行业的新词热度,由大数据平台->数据治理->数据中台->数字化转型(现代数据技术栈)转换,做为这些新词的基础组成部分,数据资产管理平台/元数据管理平台/数据目录管理平台等技术方案,依旧处于Gartner曲线的爬升恢复期,相关平台百花齐放,一统江湖的开源平台或者商用产品还没出现,在推进企业数字化转型落地过程中,实现数据治理、数据资产管理平台/元数据管理平台/数据目录管理平台的选型,依旧是一项考验人能力的活。
一、Atlas
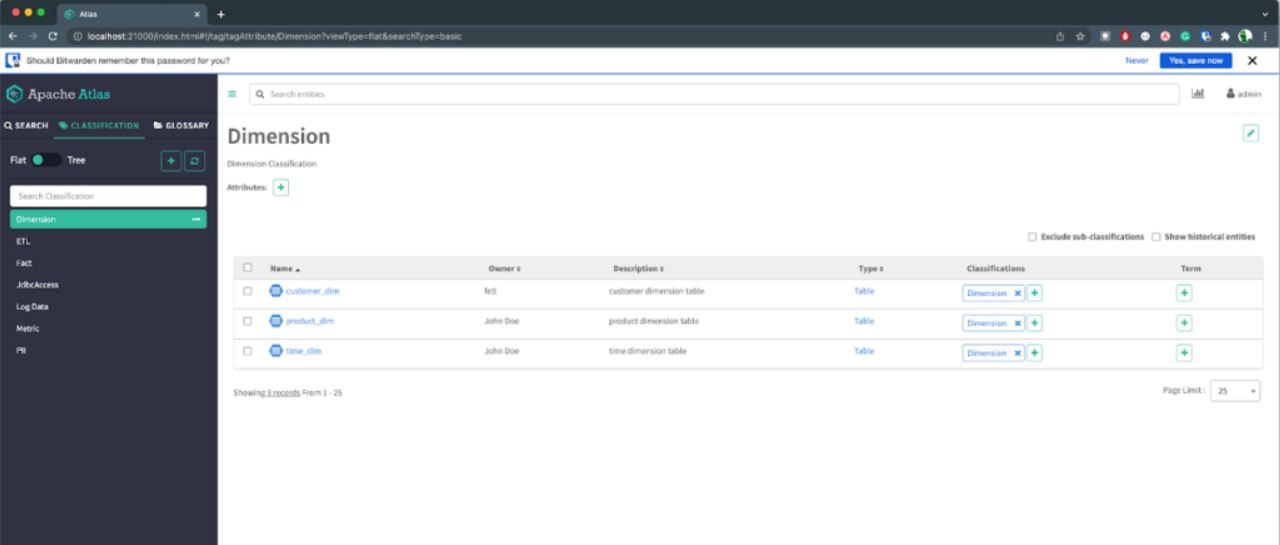
开源地址:https://github.com/apache/atlas
Atlas最早由大数据平台三驾马车(Cloudera,Hortonworks,MapR)之一HortonWorks公司开发,用来管理Hadoop项目里面的元数据,进而设计为数据治理的框架,它为Hadoop集群提供了包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理在内的元数据治理核心能力。
后来开源出来给Apache社区进行孵化,得到Aetna,Merck,Target,SAS,IBM等公司的支持进行发展演进。因其支持横向海量扩展、良好的集成能力和开源的特点,国内大部分厂家选择使用Atlas或对其进行二次开发。目前,Cloudera,Hortonworks已经并购,MapR也鲜有新品。
大数据技术领域,相较于Hadoop技术平台风头正盛的2016年,已经发生了巨大的变化,Hadoop体系正在逐步淡出舞台中央。MPP、现代技术栈、云原生数据库等登上舞台,例如Clickhouse、Doris、StarRocks、Databend、Materialize、Ringswave。
Atlas的优点:
-
大厂开源,深度集成Hadoop生态中的Hive,支持表级、字段级血缘
-
与HDP原生集成,支持对接Ranger实现行列级数据权限管控,安装便捷省心
-
强大的元数据元模型,支持元数据定制及扩展
-
源代码不复杂,国内有大量平台基于Atlas定制修改为商用产品
Atlas的不足:
-
其优势也是劣势,母开源公司已被并购,历史悠久,不再是一种优势,反而是一种负担
-
Hadoop体系已经走向衰退,如何只是完美支持Hive和Hadoop体系,已经无法满足现在快速发展的技术要求
-
其设计界面复杂,体验老旧、数据目录及数据检索都不够便捷
-
使用体验复杂及产品功能更聚焦于解决技术人员的问题,而非数据的最终用户,比如业务人员
-
生态渐渐失去新鲜感、新的类似平台不断发展
相关介绍:https://mp.weixin.qq.com/s/MvaxSF74NE0E43i4rQEb3g
选型建议:
1)如果您只有Hadoop生态,可以试试。
2)如果您的数据资产是面向数据团队的技术人员,可以试试。
二、DataHub
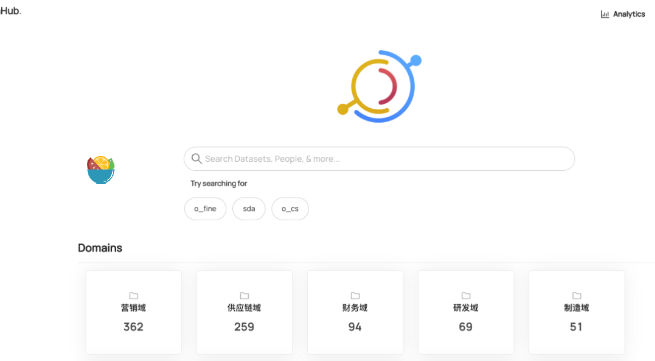
开源地址:https://github.com/datahub-project/datahub 7.2K star
DataHub是由Linkedin开源的,官方Slogan:The Metadata Platform for the Modern Data Stack - 为现代数据栈而生的元数据平台。目的就是为了解决多种多样数据生态系统的元数据管理问题,它提供元数据检索、数据发现、数据监测和数据监管能力,帮助大家解决数据管理的复杂性。
DataHub基于Apache License 2开源,采用基于推送的数据收集架构(当然也支持pull拉取的方式),能够持续收集变化的元数据。当前版本已经集成了大部分流行数据生态系统接入能力,包括但不限于:Kafka, Airflow, MySQL, SQL Server, Postgres, LDAP, Snowflake, Hive, BigQuery。
Datahub的优点:
-
名门开源,与Kafka同家庭。社区活跃,发展势头迅猛,版本更新迭代迅速。
-
定位清晰且宏远,Slogan可以看出团队的雄心壮志及后期投入,且不断迭代更新的版本也应证了这一点。
-
底层架构灵活先进,未扩展集成而生,支持推送和拉去模式,详见:https://datahubproject.io/docs/architecture/architecture/
-
UI界面简单易用,技术人员及业务人员友好
-
接口丰富,功能全面
Datahub的不足:
-
前端界面不支持国际化,界面的构建和使用逻辑不够中国化
-
版更更新迭代快,使用后升级是个难题
-
较多功能在建设中,例如Hive列级血缘
-
部分功能性能还需要优化,例如SQL Profile
-
中文资料不多,中文交流社群也不多
相关介绍:
https://mp.weixin.qq.com/s/74gK3hTt7-j1lTbKFagbTQ
https://mp.weixin.qq.com/s/iP6sc2DzPaeAKpSWNmf8hQ
选型建议:1)如果有至少半个前端开发人员+后台开发人员;2)如果需要用户体验较好的数据资产管理平台;3)如果有需要扩展支持各种平台、系统的元数据。请把Datahub列为最高选择。尽管列举了一些不足,但是开源产品中Datahub目前是相对最好的选择。笔者也在生产中使用,有问题的可以随时沟通交流。
商用版本: Metaphor(https://metaphor.io/)是Datahub的SaaS版本。
三、Marquez
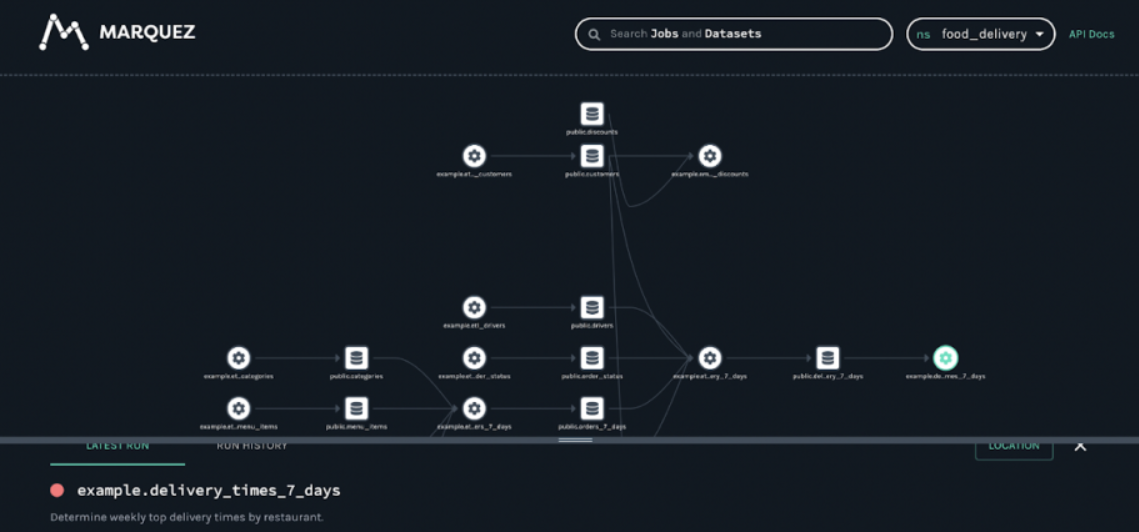
开源地址:https://github.com/MarquezProject/marquez 1.3K star
Marquez的优点:
-
界面美观,操作细节设计比较棒
-
部署简单,代码简洁
-
依靠底层OpenLineage协议,结构较好
Marquez的不足:
-
聚焦数据资产/血缘的可视化,数据资产管理的一些功能,需要较多开发工作
相关介绍:https://mp.weixin.qq.com/s/OMm6QEk9-1bFdYKuimdxCw
选型建议:1)如果您有功能强大的元数据及数据资产管理平台后端,仅需要数据资产的可视化及血缘展示,可以考虑使用体验。2)界面展示比较棒,支持选择依赖线路高亮及隐藏支线依赖。要做到数据资产管理、元数据采集有较多的工作要做。
商用版本: Datakin(https://datakin.com/) 是Marquez的SaaS版本. 支持 Apache Hive, Amazon RDS, Teradata, Amazon Redshift, Amazon S3, and Cassandra.
四、Amundsen
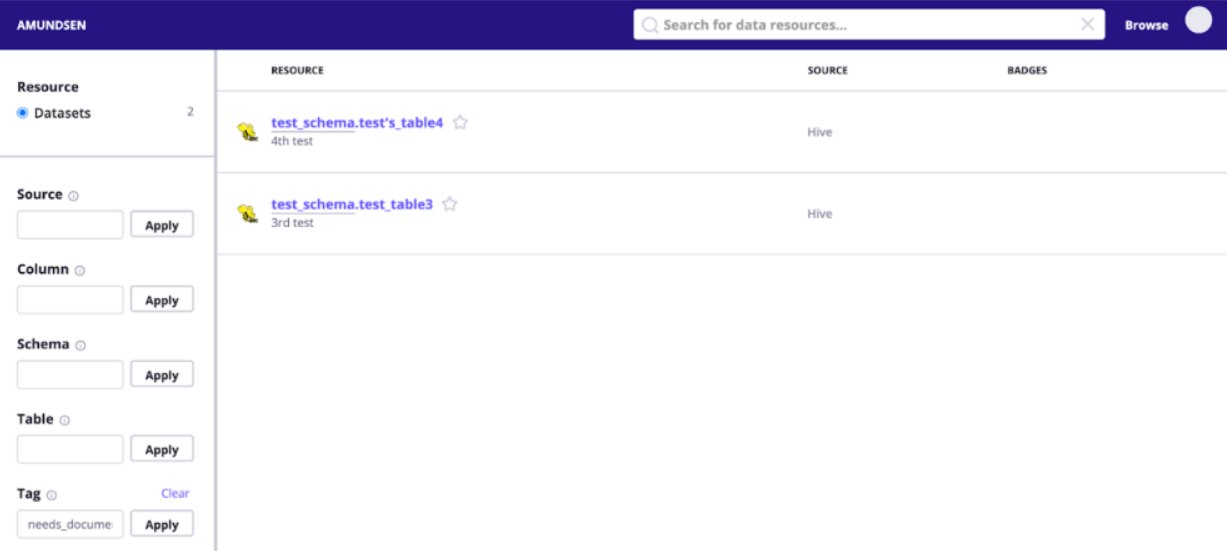
开源地址:https://github.com/amundsen-io/amundsen 3.8K star
Amundsen 是来自Lyft 开源的元数据管理、数据发现平台,功能点很全,有一个比较全的前端、后端以及数据处理框架
Amundsen的优点:
-
Lyft大厂开源,社区活跃,版本更新较多
-
定位清晰明确,与Datahub类似,致力于成为现代数据栈中的数据目录产品
-
支持对接较多的数据平台与工具
Amundsen的不足:
-
中规中矩的UI界面,操作便捷性不足
-
中文文档不多
-
血缘、标签、术语等功能方面不如Datahub使用便捷
-
较多支持友好的组件,国内使用的不多
相关介绍:
https://mp.weixin.qq.com/s/yGZ1RJs2seu943sswxYYzw
https://mp.weixin.qq.com/s/5w6euvUWzm5RWXgisB-rMg
https://mp.weixin.qq.com/s/iVocnMV8zuQN-jcID83nSg
选型建议:
1)如果有人折腾,建议选择Datahub,如果没人折腾,选择Amundsen够折腾
商用版本: Stemma(https://www.stemma.ai/)是Amundsen的SaaS 版本。
五、Open Data Discovery
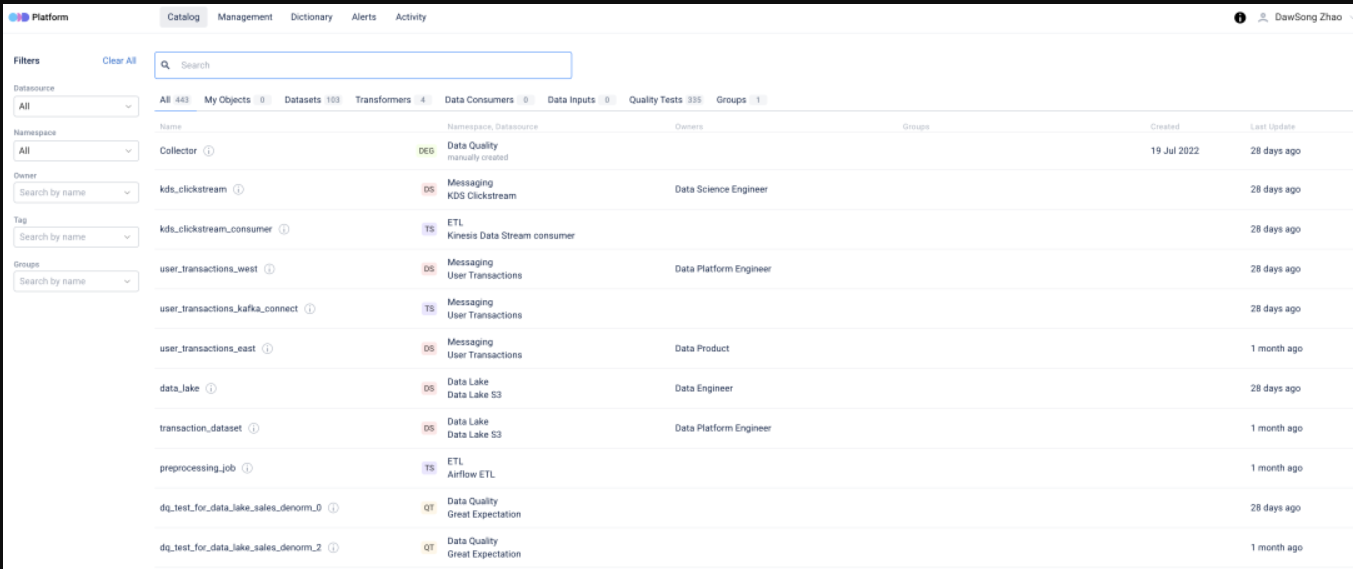
开源地址:https://github.com/opendatadiscovery/odd-platform (692 star)
Open Data Discover是一个开源的数据发现和可观测性平台。它旨在通过使数据更易于发现、管理、可观察、可靠和安全,帮助数据驱动企业实现数据民主化。由于ODD支持开放数据标准,因此数据团队能够在各种数据工具之间进行更高效的数据交换。
说实在,平台的UI确实非常漂亮。它的摄取是基于规范的。但是,该平台正在开发中,因此一些功能仍在开发中。
Open Data Discovery的优点:
-
提供在线体验Demo环境,有助于推广拉新
-
UI界面美观漂亮,界面操作逻辑符合国人使用习惯
-
项目年轻,能够在已有的众多数据资产项目中吸取经验
-
集成了数据质量模块
-
Datahub有的一些优秀功能都做了规划
-
支持开放数据标准,感觉也没啥用,国内玩不转
-
提供了调度工作流告警接口
-
基于数据可观测的新理念设计
-
ML是第一等公民,这个是对赌未来的AI发展预期
Open Data Discovery的不足:
-
项目处于起步阶段,社区还不太活跃
-
与Datahub大量功能重叠
-
中文资料少的可怜
-
产品的定位?
相关介绍:https://demo.oddp.io/ 百闻不如一见,百见不如一干。
选型建议:项目处于早期,国内生态还未起来。有尝新意识和乐于折腾精神的人,可以去跟踪、研究。生产环境搭建使用,需要做好前、后端问题,都去深挖源码的准备。
六、Open Metadata
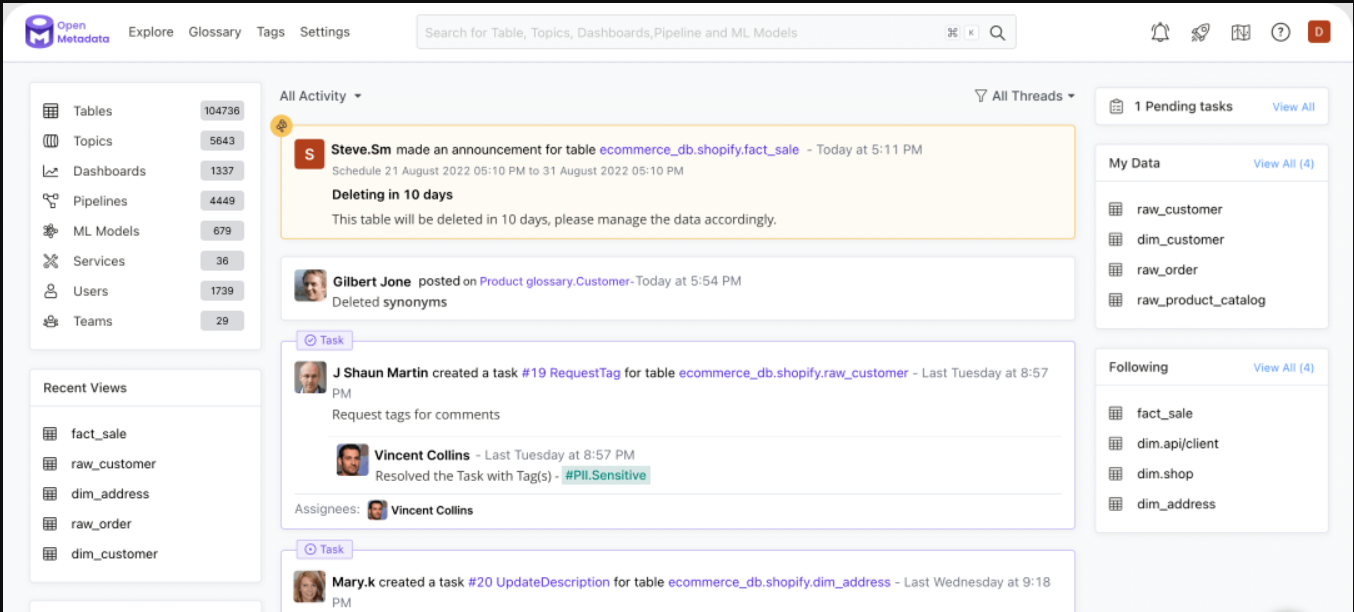
开源地址:https://github.com/open-metadata/OpenMetadata (1.9K star)
OpenMetadata是元数据的开放标准,为端到端元数据管理解决方案提供了基础能力。提供数据发现、数据治理、数据协同、数据质量和可观测性的所有必要组件。
与Open Data Discover类似,其UI非常美观,其操作和使用逻辑,也符合业务人员的习惯。
Open Metadata的优点:
-
提供在线体验Demo环境,有助于推广拉新
-
UI界面美观漂亮,界面操作逻辑符合国人使用习惯
-
项目年轻,能够在已有的众多数据资产项目中吸取经验
-
集成了数据质量模块
-
支持开放数据标准,感觉也没啥用,国内玩不转
-
基于数据可观测的新理念设计
Open Metadata的不足:
-
项目处于起步阶段,国人参与不多
-
与Open Data Discovery的区分度不是特别大
-
产品还在快速开发中
-
中文资料少的可怜
相关介绍:https://sandbox.open-metadata.org/ 百闻不如一见,百见不如一干。
选型建议:项目处于早期,国内生态还未起来。有尝新意识和乐于折腾精神的人,可以去跟踪、研究。生产环境搭建使用,需要做好前、后端问题,都去深挖源码的准备。
商用版本:collate(https://www.getcollate.io/)是Open Metadata的SaaS版本。
七、Magda
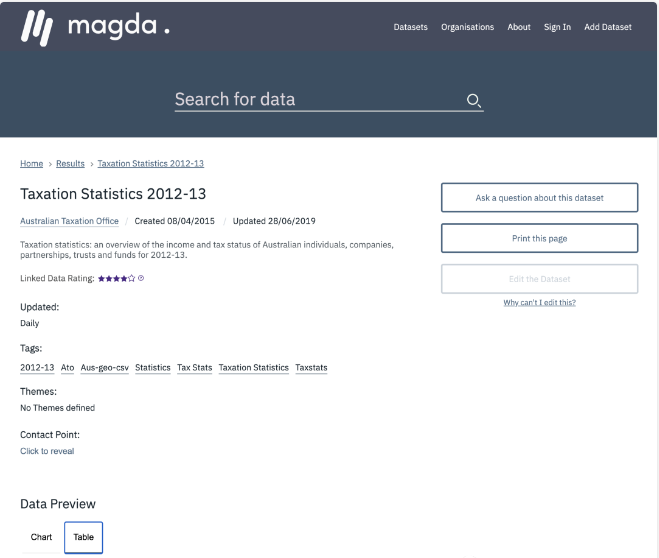
开源地址:https://github.com/magda-io/magda (408 star)
Magda是一个数据目录系统,提供数据编目、增强、搜索、跟踪和排序等功能。支持内部、外部数据源,支持大数据及小数据处理,支持通过文件、数据库或API的方式对外提供数据资产服务。
目标用户:数据技术人员,例如数据分析师、数据科学家和数据工程师。
价值目标:为数据技术人员,提供历史数据版本管理、重复数据检测等辅助功能,提高数据查询、管理的效率及质量。
Magda的优点:
-
轻量、简单的数据目录管理平台
-
支持数据预览
-
功能聚焦,独立部署
-
界面朴素简洁
-
支持地图数据
Magda的不足:
-
功能单一,与下面的CKAN一样,定位于数据编目,数据展示及共享
-
海量数据传输,性能有问题
-
不支持现代大数据同步、集成
-
功能相对单一
相关介绍:https://demo.dev.magda.io/ 百闻不如一见,百见不如一试。
选型建议:现在的数据中台、数据资产平台都会包含类似的数据门户,Magda的功能会被集成,企业基本上比较少的场景会单独使用。
八、CKAN
开源地址:https://github.com/ckan/ckan (3.7K star)
CKAN是世界领先的开源数据门户平台,用于制作开放数据网站的工具。CKAN使发布、共享和处理数据变得容易。这是一个数据管理系统,它为编目、存储和访问数据集提供了强大的平台,具有丰富的前端、完整的API(用于数据和目录)、可视化工具等。
上面的描述,是直接百度翻译CKAN github主页的描述。用大白话说,CKAN就是一个工具,可以帮助您把个人或者企业的数据集通过网站的方式展示出去。其他人可以浏览、检索、预览、编目、下载。CKAN非常适合国家、地方政府、研究机构、学校和其他组织用于开放数据。
CKAN的优点:
-
Python主要开发语言,上手入门似乎不是问题哈
-
历史悠久,有大量的政府、研究组织用来开放公开数据
-
使用简单、独立部署
-
功能聚焦,中小规模数据编目、开发、预览及下载
CKAN的不足:
-
聚焦于数据门户,即编目组织数据、提供数据预览及下载。
-
海量数据传输,性能有问题
-
不支持现代大数据同步、集成
-
功能相对单一
相关介绍:https://blog.csdn.net/iCloudEnd/article/details/125676123
选型建议:现在的数据中台、数据资产平台都会包含类似的数据门户,CKAN的功能会被集成,企业基本上比较少的场景会单独使用。政府、学校等机构有不少应用场景。
总结
数据治理、数据资产管理等工作,是企业数字化转型中的底层基建,很重要,却又很难体现出效果和价值。上层数据战略、数据架构、数据流程、数据规范等问题,在组织层面没有解决;不论数据资产平台等工作规划和实现得如何好,都只能体现出杯水车薪的效果。
参考资料:
1.wx公众号(大数据流动)-《12款开源数据资产(元数据)管理平台选型分析(一)》
2.wx公众号(大数据与数字化转型)-《12款开源数据资产(元数据)管理平台选型分析(二)》

















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









