









 本文详细介绍了非监督神经网络中的Wake-Sleep算法,该算法用于调整深度信念网络(DBNs)中的生成权重和识别权重,以实现对原始数据的有效特征提取与重建。文中还提供了算法的Matlab代码实例。
本文详细介绍了非监督神经网络中的Wake-Sleep算法,该算法用于调整深度信念网络(DBNs)中的生成权重和识别权重,以实现对原始数据的有效特征提取与重建。文中还提供了算法的Matlab代码实例。
非监督神经网络的wake-sleep算法可以用来Fine tuning DBNs,该算法主要分为两个阶段,即"wake"阶段与"sleep"阶段,其中"wake"阶段用来学习生成权重(generative weights),"sleep"阶段用来学习识别权重(recognition weights)。
一. 原理
识别权重与生成权重分别对应DBNs的编码(encoder)与解码(decoder)过程,如下图所示:
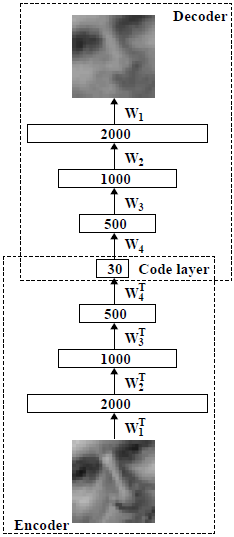
wake-sleep算法的主要目的是学习原始数据特征并能正确恢复原始数据。
整个神经网络中有两种连接(connections),即在Encoder网络从下向上(bottom-up)的recognition connections学习原始数据的特征表达,在Decoder阶段从上到下(top-down)的generative connections以最大概率或最小误差重建原始数据。这些连接的权重w如何学习,这就要用到wake-up算法。
这两组连接的训练算法可以与许多不同类型的随机神经元一起使用,但为了简单起见,wake-sleep算法只使用具有1或0两种状态的随机神经元。
设神经元
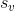
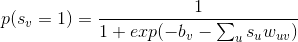
在上式中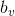

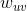
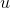

1.1 wake阶段
在wake阶段从输入input学到的各层特征表示representions,称为总的特征表达(total representations) , 用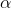
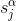
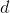
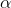

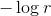
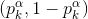
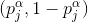
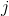
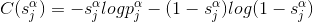
输入数据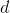
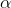
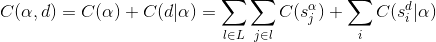
在上式中,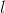
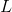
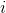
由于隐藏单元及其二进制状态一定概率取到,都是随机的,神经网络的神经元激活或不激活是随机的,也就是说原始数据的表示方式并不总是一样的。设由识别权重(recognition weights)决定的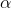
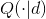
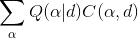
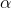
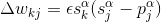
式(4)便是wake阶段的学习算法。显然,在wake阶段尽管是由recognition weights驱动,但是只有generative weights更新了,目的是为了更好的由各层的特征表示重建下一层神经元的激活状态。
1.2 sleep阶段
在得到了generative weights的更新方式之后,下一步就是sleep阶段更新recognition weights的更新算法。很自然的想到,recognition weights的更新方向要朝着使total representations 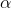
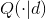
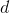
现在关闭(turn off)recognition weights,在整个网络中仅利用generative weights来驱动神经元。这也是wake-sleep二阶段学习方法的含义所在,避免同时学习recognition weights与generative weights,这样的话训练非常耗时。在generative weights从down-bottom在整个网络中驱动神经元时,由于各神经元状态是随机的,驱动到输入端时,会产生很多与input数据相近而各不相同的fantasy vectors。然后,我们调节识别权重,以最大限度地恢复实际产生fantasy vectors隐藏活动状态的对数概率。
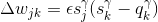
在上式中,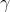
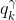
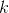
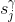
wake-sleep算法的Matlab代码如下
maxepoch=10000;
numhid=500; numpen=500; numpen2=2000;
labgenbiases=zeros(numcases,10);
pengenbiases=zeros(numcases,numpen);
wakehidstates=zeros(numcases,numhid);
wakepenstates=zeros(numcases,numpen);
postopstates=zeros(numcases,numpen2);
neglabstates=zeros(numcases,10);
penhid=hidpen';
epsilonw = 0.01;
epsilonvb = 0.01;
epsilonhb = 0.01;
weightcost = 0.0002;
initialmomentum = 0.5;
finalmomentum = 0.9;
display('Generatively fine-tuning the model using wake sleep........');
load mnistvhclassify
load mnisthpclassify
load mnisthp2classify
makebatches;
[numcases numdims numbatches]=size(batchdata);
N=numcases;
hidvis=vishid';
hidvisinc=zeros(numhid,numdims);
visbiasinc=zeros(numcases,numdims);
penhidinc=zeros(numpen,numhid);
hidgenbiasesinc=zeros(numcases,numhid);
labtopinc=zeros(10,numpen2);
labgenbiasesinc=zeros(numcases,10);
hidpen2inc=zeros(numpen,numpen2);
pengenbiasesinc=zeros(numcases,numpen);
penrecbiases2inc=zeros(numcases,numpen2);
hidpeninc=zeros(numhid,numpen);
penrecbiasesinc=zeros(numcases,numpen);
vishidinc=zeros(numdims,numhid);
hidrecbiasesinc=zeros(numcases,numhid);
for epoch = 1:maxepoch
for batch = 1:numbatches
data = [batchdata(:,:,batch)];
target = [batchtargets(:,:,batch)];
wakehidprobs= 1./(1 + exp(-data*vishid-hidrecbiases));
wakehidstates=wakehidprobs>rand(numcases,numhid);
wakepenprobs=1./(1+exp(-wakehidstates*hidpen-penrecbiases));
wakepenstates=wakepenprobs>rand(numcases,numpen);
postopprobs=1./(1+exp(-wakepenstates*hidpen2-target*labtop-penrecbiases2));
postopstates=postopprobs>rand(numcases,numpen2);
poslabtopstatistics=target' * postopprobs;
pospentopstatistics=wakepenstates' *postopprobs;
posvisact=sum(data);
postarget=sum(target);
pospengen=sum(wakepenstates);
postop=sum(postopstates);
% perform numCDiters Gibbs Sampling iterations using the top level
% undirected associative memory
negtopstates=postopstates;
if (1<=epoch<=100)
numCDiters=3;
elseif (101<=epoch<=200)
umCDiters=6;
elseif (201<=epoch<=10000)
umCDiters=10;
end
% the top level RBM
for iter=1:numCDiters
neglabstates=zeros(numcases,10);
negpenprobs=1./(1+exp(-negtopstates*hidpen2'-pengenbiases));
negpenstates=negpenprobs>rand(numcases,numpen);
neglabprobs=exp(negtopstates*labtop'+labgenbiases);
neglabprobs=neglabprobs./(repmat(sum(neglabprobs,2),1,10));
% sample y
[n_samples,n_classes] = size(visible_prob_post);
neglabstates = zeros(n_samples,n_classes);
r = rand(n_samples,1);
for ii = 1:n_samples
aux = 0;
for j = 1:n_classes
aux = aux + visible_prob_post(ii,j);
if aux >= r(ii)
neglabstates(ii,j) = 1;
break;
end
end
end
negtopprobs=1./(1+exp(-negpenstates*hidpen2-neglabstates*labtop-penrecbiases2));
negtopstates=negtopprobs>rand(numcases,numpen2);
end
negpentopstatistics=double(negpenstates') *double( negtopprobs);
neglabtopstatistics=double(neglabstates') * negtopprobs;
negtarget=sum(neglabstates);
negtop=sum(negtopstates);
% starting from the end of the Gibbs SAMPLING RUN, perform a
% top-down generative pass to get sleep phase probabilities and
% sample states
sleeppenstates=negpenstates;
sleephidprobs=1./(1+exp(-sleeppenstates*penhid-hidgenbiases));
sleephidstates=sleephidprobs>rand(numcases,numhid);
sleepvisprobs=1./(1+exp(-sleephidstates*hidvis-visbiases));
% predictions
psleeppenstates=1./(1+exp(-sleephidstates*hidpen-penrecbiases));
possleeppenstates=psleeppenstates>rand(numcases,numpen);
psleephidstates=1./(1+exp(-sleepvisprobs*vishid-hidrecbiases));
negsleephidstates=psleephidstates>rand(numcases,numhid);
pvisprobs=1./(1+exp(-wakehidstates*hidvis-visbiases));
phidprobs=1./(1+exp(-wakepenstates*penhid-hidgenbiases));
phidstates=phidprobs>rand(numcases,numhid);
negvisact=sum(pvisprobs);
poshidgen=sum(wakehidstates);
neghidgen=sum(phidstates);
negpengen=sum(negpenstates);
possleeppen=sum(sleeppenstates);
negpsleeppen=sum(possleeppenstates);
possleephid=sum(sleephidstates);
negpsleephid=sum(negsleephidstates);
if epoch>5,
momentum=finalmomentum;
else
momentum=initialmomentum;
end;
% update to generative parameters
hidvisinc=momentum * hidvisinc + epsilonw*(wakehidprobs'*(data-pvisprobs)/numcases-weightcost * hidvis);
visbiasinc=momentum * visbiasinc + (epsilonvb/numcases)*(repmat(posvisact,numcases,1)-repmat(negvisact,numcases,1));
penhidinc=momentum * penhidinc + epsilonw*(wakepenprobs'*(wakehidstates-phidstates)/numcases-weightcost * penhid);
hidgenbiasesinc=momentum * hidgenbiasesinc + (epsilonhb/numcases)*(repmat(poshidgen,numcases,1)-repmat(neghidgen,numcases,1));
hidvis=hidvis+hidvisinc;
visbiases=visbiases+visbiasinc;
penhid=penhid+ penhidinc;
hidgenbiases=hidgenbiases+hidgenbiasesinc;
% update to top level associative memory parameters
labtopinc=momentum * labtopinc + epsilonw * ((poslabtopstatistics-neglabtopstatistics)/numcases- weightcost * labtop);
labgenbiasesinc=momentum *labgenbiasesinc + (epsilonhb/numcases) *(repmat(postarget,numcases,1)-repmat(negtarget,numcases,1));
hidpen2inc=momentum * hidpen2inc + epsilonw * ((pospentopstatistics-negpentopstatistics)/numcases- weightcost * hidpen2);
pengenbiasesinc=momentum * pengenbiasesinc + (epsilonhb/numcases) * (repmat(pospengen,numcases,1)-repmat(negpengen,numcases,1));
penrecbiases2inc=momentum * penrecbiases2inc + (epsilonhb/numcases) * (repmat(postop,numcases,1)-repmat(negtop,numcases,1));
labtop=labtop +labtopinc;
labgenbiases=labgenbiases+labgenbiasesinc;
hidpen2=hidpen2 + hidpen2inc;
pengenbiases=pengenbiases+pengenbiasesinc;
penrecbiases2=penrecbiases2 + penrecbiases2inc;
% update to recognition approximation parameters
hidpeninc=momentum * hidpeninc + epsilonw * ((sleephidprobs' * (sleeppenstates-possleeppenstates)/numcases)-weightcost * hidpen);
vishidinc=momentum * vishidinc + epsilonw *((sleepvisprobs' * (sleephidstates-negsleephidstates)/numcases)-weightcost * vishid);
penrecbiasesinc=momentum * penrecbiasesinc + (epsilonhb/numcases) * (repmat(possleeppen,numcases,1)-repmat(negpsleeppen,numcases,1));
hidrecbiasesinc=momentum * hidrecbiasesinc + (epsilonhb/numcases) * (repmat(possleephid,numcases,1)-repmat(negpsleephid,numcases,1));
hidpen=hidpen + hidpeninc;
penrecbiases=penrecbiases+penrecbiasesinc ;
vishid=vishid + vishidinc ;
hidrecbiases=hidrecbiases+ hidrecbiasesinc;
end
save parameters hidvis visbiases penhid hidgenbiases labtop labgenbiases hidpen2 pengenbiases penrecbiases2 hidpen penrecbiases vishid hidrecbiases;
fprintf(1,'After epoch %d Train. \n',epoch);
generating_samples;
end
% generating_samples;
参考:
1. The wake-sleep algorithm for unsupervised neural networks

















 2217
2217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









